-
Pandas数据分析29——faker构建虚拟数据集
参考书目:《深入浅出Pandas:利用Python进行数据处理与分析》
生活中做科研写论文,或者是给老板老师做案例分析,交任务都需要数据集,要是没有实际的数据集怎么办?可以自己模拟制作一个数据集。faker这个库生成数据集有很多的特点,他会生成名字地址身份证信用卡号等信息,就很像真实的客户信息。下面一起来学习一下这个包。首先体验一下生成数据是长这个样子的:

当然,这种假的数据集是不能用于科研的论文发表的,仅用于做小案例分析练手,做科研第一是学术造假,很严重。第二是这个数据生成的时候都是独立同分布的,一般都是均匀分布。所以也得不到什么有效的结论。要做科研还是老老实实收集数据吧。
首先还是导入包
- #导入相关模块
- import faker
- fake=faker.Faker('zh-cn')
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import seaborn as sns
- plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
- plt.rcParams ['axes.unicode_minus']=False #显示负号
我这里直接生成十几个特征变量——["姓名",'性别',"详细地址","所在省份","手机号","身份证号","出生年月",'年龄',"邮箱",'公司名称','信用卡号','用户名','工作职位','颜色名字','随机类别','均匀浮点数','正态身高']。基本涵盖了faker数据库的常见用法。需要啥就筛选出啥然后储存。
- #Faker.seed(0) #可以固定随机数种子
- #要生成的变量名称
- key_list = ["姓名",'性别',"详细地址","所在省份","手机号","身份证号","出生年月",'年龄',"邮箱",'公司名称','信用卡号','用户名','工作职位',
- '颜色名字','随机类别','均匀浮点数','正态身高']
- def get_data():
- #name = fake.name() #姓名
- sex=fake.random_element(('男','女')) #性别
- if sex=='男':
- name=fake.name_male() # 男性姓名
- else:
- name=fake.name_female() # 女性姓名
- address = fake.address() #详细地址
- province = address[:3] #省份
- number = fake.phone_number() #手机号
- id_card = fake.ssn() #身份证
- birth_date = pd.to_datetime(id_card[6:14]).strftime('%Y-%m-%d') #出生年月
- old=pd.Timestamp('now').year-int(id_card[6:10])# 年龄
- email = fake.email() #邮箱
- company=fake.company() # 公司名
- card=fake.credit_card_number(card_type=None)# 信用卡号
- use_name=fake.user_name() # 用户名
- job=fake.job() #工作职位
- color=fake.color_name() # 颜色名字
- kind=fake.random_int(1,5) #随机类别
- float_num=np.random.rand(1,)[0] #0-1浮点数 均匀分布
- normal=(np.random.randn(1,)[0]+1)*12+156 #正态分布,可用身高
- info_list = [name,sex,address,province,number,id_card,birth_date,old,email,company,card,use_name,job,color,kind,float_num,normal]
- person_info = dict(zip(key_list,info_list))
- return person_info
- df = pd.DataFrame(columns=key_list)
- for i in range(10000): #生成1w条数据
- person_info = [get_data()]
- df1 = pd.DataFrame(person_info)
- df = pd.concat([df,df1])
- df=df[df['年龄']<=65] #将65岁以上的人群都筛掉
- df.to_excel("模拟数据.xlsx",index=None) #储存
数据生成好了也储存了,上面是生存了1w条数据,然后把65岁以上的人群给筛掉了。剩下的数据有6610条,查看一下信息。
df.info()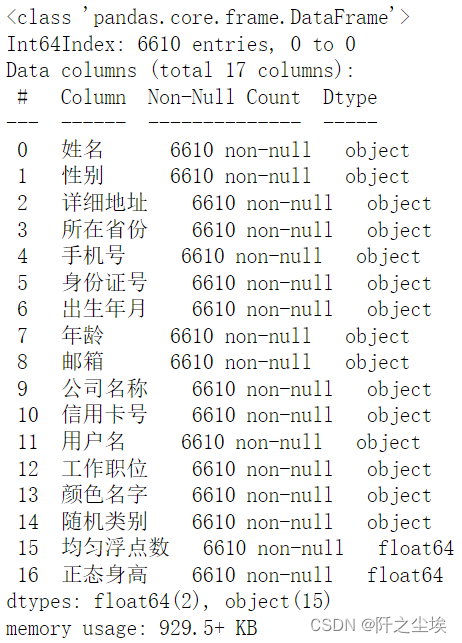
在execl里面打开看看,数据长这个样子:

看上去有模有样的。
研究一下这个生成的数据的变量的分布情况:
df['性别'].value_counts().plot.pie()
男女比很均匀。
df['所在省份'].value_counts().plot.bar(figsize=(12,4))
省份也很均匀。
df['随机类别'].value_counts().plot.bar()
我随机给他们打了一个整数标签,也是均匀分布。
df['均匀浮点数'].plot.box()
也是均匀的分布。
df['年龄'].plot.hist()
年龄也是均匀分布。
df['正态身高'].plot.hist()
身高是正态分布,我故意在代码设定为正态分布的。但是200以上的人居然有这么多.....方差还是大了。
这个包的基础生成的变量分布都是均匀分布,也就是说都是随机从一些选项中挑一项出来的,并且变量和变量之间是独立的,没有相关性。所以没啥特点,数据分析也得不出什么有效结论。
简单使用:
- import faker
- f=faker.Faker('zh-cn')
- df=pd.DataFrame({'客户姓名':[f.name() for i in range(10)],'年龄':[f.random_int(20,50) for i in range(10)],
- '最后来电时间':[f.date_between(start_date='-1y',end_date='today').strftime('%Y-%m-%d') for i in range(10)],
- '意向':[f.random_element(('有','无')) for i in range(10)], '街道地址':[f.street_address() for i in range(10)],
- '手机号':[f.phone_number() for i in range(10)],
- })
- df

#也可以一列列添加
- ( pd.DataFrame()
- .assign(客户姓名=[f.name() for i in range(10)])
- .assign(年龄=[f.random_int(20,50) for i in range(10)])
- .assign(最后来电时间=[f.date_between(start_date='-1y',end_date='today').strftime('%Y-%m-%d')for i in range(10)])
- .assign(意向=[f.random_element(('有','无')) for i in range(10)])
- .assign(地址=[f.address() for i in range(10)])
- )

其他的随时生成的代码:
时间的用法
- #时间
- fake.date_time(tzinfo=None) # 随机日期时间
- fake.iso8601(tzinfo=None) # 以iso8601标准输出的日期
- fake.date_time_this_month(before_now=True, after_now=False, tzinfo=None) # 本月的某个日期
- fake.date_time_this_year(before_now=True, after_now=False, tzinfo=None) # 本年的某个日期
- fake.date_time_this_decade(before_now=True, after_now=False, tzinfo=None) # 本年代内的一个日期
- fake.date_time_this_century(before_now=True, after_now=False, tzinfo=None) # 本世纪一个日期
- fake.date_time_between(start_date="-30y", end_date="now", tzinfo=None) # 两个时间间的一个随机时间
- fake.timezone() # 时区
- fake.time(pattern="%H:%M:%S") # 时间(可自定义格式)
- fake.am_pm() # 随机上午下午
- fake.month() # 随机月份
- fake.month_name() # 随机月份名字
- fake.year() # 随机年
- fake.day_of_week() # 随机星期几
- fake.day_of_month() # 随机月中某一天
- fake.time_delta() # 随机时间延迟
- fake.date_object() # 随机日期对象
- fake.time_object() # 随机时间对象
- fake.unix_time() # 随机unix时间(时间戳)
- fake.date(pattern="%Y-%m-%d") # 随机日期(可自定义格式)
- fake.date_time_ad(tzinfo=None) # 公元后随机日期
文件
- #文件
- fake.file_name(category="image", extension="png") # 文件名(指定文件类型和后缀名)
- fake.file_name() # 随机生成各类型文件
- fake.file_extension(category=None) # 文件后缀
- fake.mime_type(category=None) # mime-type
#lorem 乱数假文
- #lorem 乱数假文
- fake.text(max_nb_chars=200) # 随机生成一篇文章
- fake.word() # 随机单词
- fake.words(nb=3) # 随机生成几个字
- fake.sentence(nb_words=6, variable_nb_words=True) # 随机生成一个句子
- fake.sentences(nb=3) # 随机生成几个句子
- fake.paragraph(nb_sentences=3, variable_nb_sentences=True) # 随机生成一段文字(字符串)
- fake.paragraphs(nb=3) # 随机生成成几段文字(列表)
生成一篇文章看看
print(fake.text(max_nb_chars=200))
emmmm,不通顺,词语都是词语,但是读不通。
多元正态分布生成
表格数据(二维数据)是科研和工作中最常见的数据,在生成数据的时候,想要变量之间存在一定的相关性(因为正态分布生成的数据相关性都很差),那么如何控制每个不同的变量之间的均值方差和相关性呢。下面这个案例会告诉你。
主要是依靠numpy里面的np.random.multivariate_normal() 函数。
参数解释
mean:多元正态分布的维度。(长度为N的一维数组)
示例:mean = [0, 0] # 1行2列的一维数组,numpy.ramdom.randn()可以生成一维矩阵。
cov:多元正态分布的协方差矩阵,且协方差矩阵必须是对称矩阵和半正定矩阵(形状为(N,N)的二维数组)。
示例:cov = [[1. 0.], [0. 1.]] # 可以使用numpy.eye()生成对角矩阵。
size: 数组的形状(整数或者由整数构成的元组)。如果该值未给定,则返回单个N维的样本(N恰恰是上面mean的长度)。
示例:size = (3, 3) # 生成的数组的每一个元素是3行3列的矩阵。
代码如下:
- import sys
- import numpy as np
- import pandas as pd
- mean = [1,2,3,4,5]
- cov = [[10,2,2,3,4],[2,2,1,1,1],[2,1,3,2,2],[3,1,2,4,3],[4,1,2,3,5]]
- size = (10000,)
- result = np.random.multivariate_normal(mean, cov, size)
- print(result.shape)

上述代码生成了10000*5维的矩阵。5个变量对应着mean的取值是5个(生成p维就要有p个数字),分别是每个变量的均值,协方差阵是p*p维的,而且是对称的半定矩阵 。size就是生成的个数。
计算每列的均值和方差
result.mean(axis=0)
result.std(axis=0)**2
协方差阵的斜对角上就是每个变量自己的方差,可以看到计算和设置的差不多。
再来验证一下相关系数
pd.DataFrame(result).corr()
可以看到相关系数矩阵,我们可以调整相关系数大小。
比如变量0和变量1的相关系数是0.45,怎么算的呢。
介于协方差和相关系数有这么一个关系:

我们可以计算理论上第0个变量和第1个变量之间的相关系数:
2/np.sqrt(10)/np.sqrt(2) 和实际值差不多!
和实际值差不多!所以我们可以控制协方差阵之间每个变量的协方差大小来做到控制相关性系数的大小。
均值就是mean参数设定,方差就是协方差矩阵的对角线上的元素大小。
生成案例数据矩阵
我同学有个数据集太小,想多生成一点数据,然后还需要每个变量的均值方差,以及每个变量的相关系数都要差不多。可以用上面的方法实现:
- df=pd.read_csv('城市管廊数据最终.csv')
- columns=df.columns
- columns
读取原来的案例数据,然后计算其均值,协方差矩阵。然后将其传入,生成更多的数据矩阵。
注意这里我们是把变量放在列上,所以计算协方差矩阵要传入参数“rowvar”=False
- mean = df.to_numpy().mean(axis=0)
- cov = np.cov(df.to_numpy(),rowvar=False)
- size = (1000,)
- data= np.random.multivariate_normal(mean, cov, size)
- print(data.shape)

这就造出来了1k条数据,然后再根据实际要求去赋值筛选修改之类的。
-
相关阅读:
jacob解决freemaker导出word文档手机无法预览问题(附下载地址)
HttpUtils工具类
交流电和直流电的区别是什么?
.NET MAUI in Mac
Android开发笔记——快速入门(全局大喇叭)
一本通1061;求整数的和与均值
JAVA计算机毕业设计宿迁学院学生设计作品交流网站源码+系统+mysql数据库+lw文档
【论文阅读】基于隐蔽带宽的汽车控制网络鲁棒认证(一)
MACH架构的质量工程指南
第十三届蓝桥杯JavaB组国赛H题——修路 (AC)
- 原文地址:https://blog.csdn.net/weixin_46277779/article/details/126389291
