神经网络与深度学习绪论
- 人工智能的一个子领域
- 神经网络:一种以(人工)神经元为基本单元的模型
- 深度学习:一类机器学习问题,主要解决贡献度分配问题
知识结构

学习路线图

预备知识
- 线性代数
- 微积分
- 数学优化
- 概率论
- 信息论
推荐课程
斯坦福大学CS224n: Deep Learning for Natural Language Processing
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/
Chris Manning主要讲解自然语言处理领域的各种深度学习模型
斯坦福大学CS23ln: Convolutional Neural Networks for Visual Recognition
http://cs231n.stanford.edu/
Fei-Fei Li Andrej Karpathy 主要讲解CNN、RNN在图像领域的应用
加州大学伯克利分校CS294:Deep Reinforcement Learning
http://rail.eecs.berkeley.edu/deeprlcourse/
推荐材料
林轩田 “机器学习基石” “机器学习技法”
https://www.csie.ntu.edu.tw/~htlin/mooc/
李宏毅 “1天搞懂深度学习”
http://speech.ee.ntu.edu.tw/~tlkagk/slide/Tutorial_HYLee_Deep.pptx
李宏毅 “机器学习2020”
https://www.bilibili.com/video/av94519857/
顶会论文
- NeurIPS、ICLR、ICML、AAAI、ICAI
- ACL、EMNLP
- CVPR、ICCV
- …
常用的深度学习框架
- 简易和快速的原型设计
- 自动梯度计算
- 无缝CPU和GPU切换
- 分布式计算
人工智能
人工智能的研究领域
图灵测试是促使人工智能从哲学探讨到科学研究的一个重要因素,引导了人工智能的很多研究方向。
因为要使得计算机能通过图灵测试,计算机必须具备理解语言、学习、记忆、推理、决策等能力。
研究领域
- 机器感知(计算机视觉、语音信息处理、模式识别)
- 学习(机器学习、强化学习)
- 语言(自然语言处理)
- 记忆(知识表示)
- 决策(规划、数据挖掘)

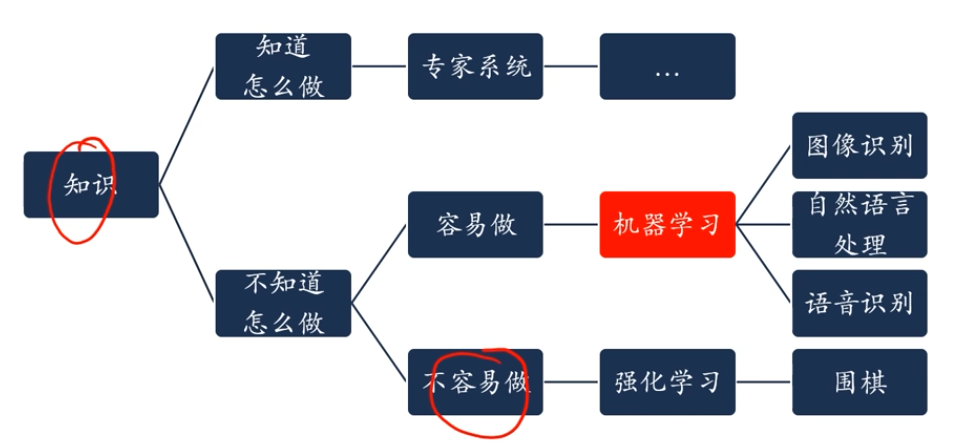
如何开发人工智能系统
规则是什么?


表示学习
当我们用机器学习来解决一些模式识别任务时,一般的流程包含以下几个步骤:

- 浅层学习(Shallow Learning):不涉及特征学习,其特征主要靠人工经验或特征转换方法来抽取。
- 特征工程:需要借助人类智能,人自己处理
数据表示
语义鸿沟:人工智能的挑战之一
底层特征VS高层语义
人们对文本、图像的理解无法从字符串或者图像的底层特征直接获得

什么是好的数据表示(Representation)?
“好的表示”是一个非常主观的概念,没有一个明确的标准。
但一般而言,一个好的表示具有以下几个优点:
- 应该具有很强的表示能力。
- 应该使后续的学习任务变得简单。
- 应该具有一般性,是任务或领域独立的。
数据表示是机器学习的核心问题。
表示形式:如何在计算机中表示语义?
-
局部表示
-
离散表示、符号表示
-
One-Hot向量
-
分布式(distributed)表示
-
压缩、低维、稠密向量
-
用ON)个参数表示O(2)区间
-
k为非0参数,k
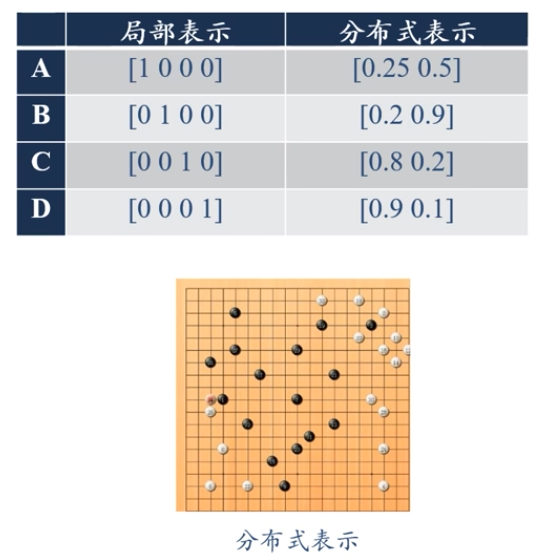
一个生活中的例子:颜色

词嵌入(Word Embeddings)

表示学习
- 表示学习:如何自动从数据中学习好的表示
- 通过构建具有一定“深度”的模型,可以让模型来自动学习好的特征表示(从底层特征,到中层特征,再到高层特征),从而最终提升预测或识别的准确性。

传统的特征提取VS表示学习
特征提取
- 线性投影(子空间)
- PCA、LDA
- 非线性嵌入
- LLE、Isomap、谱方法
- 自编码器
特征提取VS表示学习
特征提取:基于任务或先验对去除无用特征
表示学习:通过深度模型学习高层语义特征【难点:没有明确的目标,将输入和输出连接,是端到端的学习】
深度学习
表示学习与深度学习
一个好的表示学习策略必须具备一定的深度
- 特征重用:指数级的表示能力
- 抽象表示与不变性:抽象表示需要多步的构造
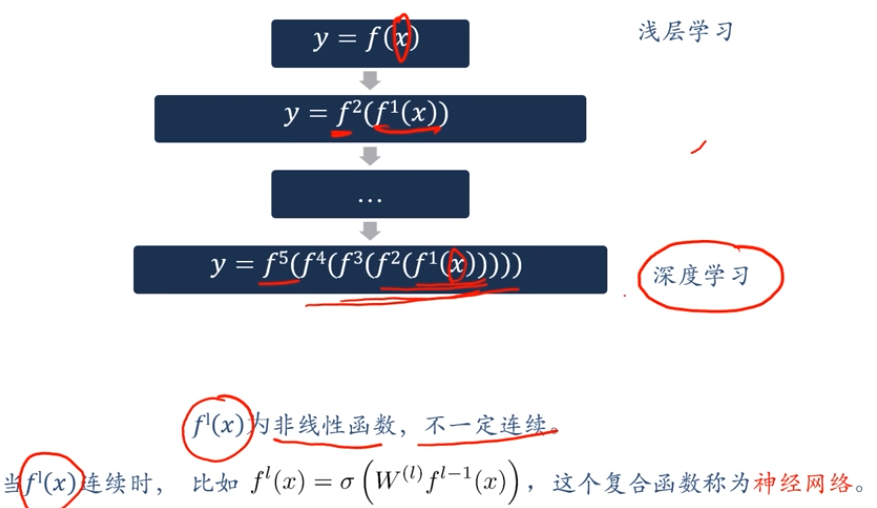
深度学习概述
深度学习=表示学习+决策(预测)学习[浅层学习]

深度学习的关键问题是贡献度分配问题,也就是底层特征还是中高层特征的构造函数谁更重要。

上面这种学习属于端到端学习(end-to-end)没有人为干预。
深度学习的数学描述
神经网络
生物神经元

神经网络如何学习?
赫布法则Hebb's Rule
“当神经元A的一个轴突和神经元B很近,足以对它产生影响,并且持续地、重复地参与了对神经元B的兴奋,那么在这两个神经元或其中之一会发生某种生长过程或新陈代谢变化,以致于神经元A作为能使神经元B兴奋的细胞之一,它的效能加强了。”
——加拿大心理学家 Donald Hebb,《行为的组织》,1949
- 人脑有两种记忆:长期记忆和短期记忆。短期记忆持续时间不超过一分钟。如果一个经验重复足够的次数,此经验就可储存在长期记忆中。
- 短期记忆转化为长期记忆的过程就称为凝固作用。
- 人脑中的海马区为大脑结构凝固作用的核心区域。
人工神经网络
人工神经元

-
人工神经网络主要由大量的神经元以及它们之间的有向连接构成。因此考虑三方面:
- 神经元的激活规则:主要是指神经元输入到输出之间的映射关系,一般为非线性函数。
- 网络的拓扑结构:不同神经元之间的连接关系。
- 学习算法:通过训练数据来学习神经网络的参数。
-
人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。
-
虽然这里将神经网络结构大体上分为三种类型,但是大多数网络都是复合型结构,即一个神经网络中包括多种网络结构。

神经网络

如何解决贡献度分配问题?
偏导数

贡献度
神经网络天然不是深度学习,但深度学习天然是神经网络。
神经网络发展史
神经网络的发展大致经过五个阶段。
第一阶段:模型提出
- 在1943年,心理学家Warren McCulloch和数学家Walter Pitts和最早描述了一种理想化的人工神经网络,并构建了一种基于简单逻辑运算的计算机制。他们提出的神经网络模型称为MP模型
- 阿兰·图灵在1948年的论文中描述了一种“B型图灵机”。(赫布型学习)
- 1951年,McCulloch和Pitts的学生Marvin Minsky建造了第一台神经网络机,称为SNARCO
- Rosenblatt[l958]最早提出可以模拟人类感知能力的神经网络模型,并称之为感知器(Perceptron),并提出了一种接近于人类学习过程(迭代、试错)的学习算法。
第二阶段:冰河期
- 1969年,Marvin Minsky出版《感知器》一书,书中论断直接将神经网络打入冷宫,导致神经网络十多年的“冰河期”。他们发现了神经网络的两个关键问题:
- 1)基本感知器无法处理异或回路。
- 2)电脑没有足够的算力来处理大型神经网络所需要的很长的计算时间。
- 1974年,哈佛大学的Paul Webos发明反向传播算法,但当时未受到应有的重视。
- 1980年,Kunihiko Fukushima(福岛邦彦)提出了一种带卷积和子采样操作的多层神经网络:新知机(Neocognitron)[卷积神经网络前身]
第三阶段:反向传播算法引起的复兴
- 1983年,物理学家John Hopfield对神经网络引入能量函数的概念,并提出了用于联想记忆和优化计算的网络(称为Hopfield网络),在旅行商问题上获得当时最好结果,引起轰动。
- 1984年,Geoffrey Hinton提出一种随机化版本的Hopfield网络,即玻尔兹曼机。
- 1986年,David Rumelhart和James McClelland对于联结主义在计算机模拟神经活动中的应用提供了全面的论述,并重新发明了反向传播算法。
- 1986年,Geoffrey Hinton等人将引入反向传播算法到多层感知器。[前馈神经网络]
- 1989年,LeCun等人将反向传播算法引入了卷积神经网络,并在手写体数字识别上取得了很大的成功。
第四阶段:流行度降低
- 在20世纪90年代中期,统计学习理论和以支持向量机为代表的机器学习模型开始兴起。
- 相比之下,神经网络的理论基础不清晰、优化困难、可解释性差等缺点更加凸显,神经网络的研究又一次陷入低潮。
第五阶段:深度学习的崛起
- 2006年,Hinton等人发现多层前馈神经网络可以先通过逐层预训练,再用反向传播算法进行精调的方式进行有效学习。
- 深度神经网络在语音识别和图像分类等任务上的巨大成功。
- 2013年,AlexNet:第一个现代深度卷积网络模型,是深度学习技术
- 在图像分类上取得真正突破的开端。[第一个真正意义现代神经网络]
- AlexNet不用预训练和逐层训练,首次使用了很多现代深度网络的技术
- 随着大规模并行计算以及GPU设备的普及,计算机的计算能力得以大幅提高。此外,可供机器学习的数据规模也越来越大。在计算能力和数据规模的支持下,计算机已经可以训练大规模的人工神经网络。
教程视频传送门:https://aistudio.baidu.com/aistudio/course/introduce/25876?directly=1&shared=1
原创作者:孤飞-博客园
原文地址:https://www.cnblogs.com/ranxi169/p/16582854.html