-
金融业信贷风控算法3-数据分析简介
一. 业务背景
数据分析是一项从自然环境、社会环境、网络环境中提取数据,实施分析,得出结论并验证的工作。

不是为了分析而做分析
针对特定的问题,用适当的学科知识从数据中提炼信息,形成结论


二. 数据的搜集与整理
数据搜集:

数据清洗:
做数据清洗的原因:脏数据;不满足分析要求

三. 数据可视化
3.1 可视化的意义
可视化数据包含的信息不会超过数据本身,但是能让使用者更加容易发掘数据的信息。在数据可视化下,信息的获取、加工、输出会变得更加简洁。
3.2 数据可视化的场景





3.3 在统计分析里的可视化案例
正态性检验:QQ-plot

相关性检验:scatter matrix

时间序列:ACF

3.4 数据可视化常用的工具
专业工具:
- Tableau:优秀的数据可视化展示工具,数据图表制作能力强,操作简单,上手快不需要写代码,数据的导入和加载都是向导式,内置美观的可视化图表,不用考虑配色,表格处理好格式即可。
- DataV:阿里云出品,付费(5元/月),拥有极其丰富的图表选择,编程简易,支持丰富的数据接入方式(其中有API接口),拥有动画效果
通用工具:
- Excel:entry level的“菜鸟”到骨灰级专家都能玩转
- R和Python:丰富的内嵌图表和海量的三方库,灵活性高
四. 分析方法
4.1 描述性统计量

4.2 有监督模型
在分析过程中,存在一个或多个“目标”变量,使得我们需要去研究其他变量(称为独立变量,或者特征)如何影响这(些)个目标变量。
例如下面的2个案例:
- 研究新生入学成绩、性别、第一学期平均学习时长是如何影响期末考试成绩
- 研究竞选中,选民的学历、收入、民族、职业等因素如何影响候选人竞选成功
单一目标变量占了绝大多数的场景。
4.3 回归和分类
当目标变量是连续型数值变量时,是回归模型,如案例1
当目标变量是取值为2或更多的类别型变量时,是分类模型,如案例2回归:线性回归,部分广义线性回归,神经网络/深度学习模型等
分类:SVM,分类树,朴素贝叶斯,逻辑回归,kNN,神经网络/深度学习模型
排序:page rank
有监督模型的损失函数
𝑙𝑜𝑠𝑠 𝑓𝑢𝑛𝑐𝑡𝑖𝑜𝑛=𝑒𝑟𝑟𝑜𝑟 𝑐𝑜𝑠𝑡+𝑐𝑜𝑚𝑝𝑙𝑒𝑥𝑖𝑡𝑦 𝑐𝑜𝑠𝑡
说明:
回归和分类,并没有本质的区别。部分模型同时适用于二者,如ANN,DL,CART等
除了上述的单一模型外,还有各种集成模型。例如基于bagging 的随机森林,基于boosting 的AdaBoost,GBDT,xgboost。又: GBDT,xgboost仅仅是集成框架,不表示具体的回归或者分类模型4.4 无监督模型
对特征:主成分分析、因子分析等
对样本:关联分析、部分聚类分析、复杂网络、生成模型(如自动编码机、GAN等)说明
除了有/无监督外,还有半监督模型
增强学习不认为是有/无监督模型

五. 数据分析工具
R:
面向统计分析的编程语言,丰富的作图功能,开源
CRAN
Rstudio
install.packages(), library()Python:
自由软件,胶水语言,免费的MATLAB
pip install yourPackage
import yourPackage as pkg
From yourPackage import yourFunction六.数据分析实例
数据源:
链接:https://pan.baidu.com/s/1B_7fPpYSt8fmSwSX0vNJqw
提取码:qjlf6.1 饼图
根据提供的数据,按照要求,生成如下图形:

首先使用sql进行预处理:
select concat(sum(case when NAME_CONTRACT_TYPE = 'Cash loans' then 1 else 0 end)*100/count(*),'%') as Cash_loans, concat(sum(case when NAME_CONTRACT_TYPE = 'Revolving loans' then 1 else 0 end)*100/count(*),'%') as Revolving_loans from application_train_small- 1
- 2
- 3
选中一行数据,插入->饼图->三维饼图的第一个

选择合适的图表布局 以及图表样式

6.2 柱形图
根据提供的数据,按照要求,生成如下图形:
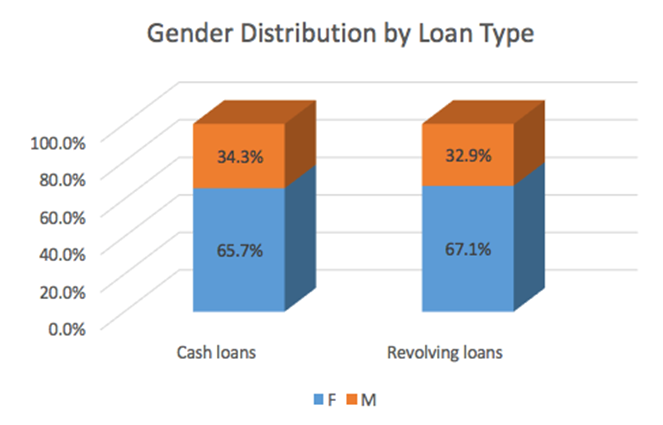
首先需要加工一下原数据:
select t.NAME_CONTRACT_TYPE, concat(round(sum(case when t.CODE_GENDER = 'F' then 1 else 0 end)*100/count(*),2),'%') F, concat(round(sum(case when t.CODE_GENDER = 'M' then 1 else 0 end)*100/count(*),2),'%') M from application_train_small t where t.NAME_CONTRACT_TYPE not in ('XNA') group by t.NAME_CONTRACT_TYPE- 1
- 2
- 3
- 4
- 5
- 6
选中一行数据,插入->柱形图->三维柱形图的第三个

出现如下图表:

先切换行和列,然后再选择第4个样例

最终出来的图表就是题目要求的

6.3 并排柱形图
根据提供的数据,按照要求,生成如下图形:

参考:
- http://www.dataguru.cn/mycourse.php?mod=intro&lessonid=1701
- https://blog.csdn.net/weixin_43851352/article/details/108325050
- https://blog.csdn.net/u014281392/article/details/81121122
-
相关阅读:
基于 dynamic-datasource 实现 DB 多数据源及事物控制、读写分离、负载均衡解决方案
如何将您的网站添加到百度站长工具
html当当书网站 html网上在线书城 html在线小说书籍网页 当当书城网页设计
算法通关村18关 | 回溯模板如何解决分割回文串问题
小白学习spring第二天
新一代分布式实时流处理引擎Flink入门实战之先导理论篇-上
git分支管理以及不同git工作流对比
部署Envoy
EasyRule源码:EasyRule框架源码分析
一百七十六、Kettle——Kettle配置HDFS输出控件能不能加GZIP等压缩方式?
- 原文地址:https://blog.csdn.net/u010520724/article/details/126288089