-
对象内存布局
目录
在HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
一、对象头
Java对象的对象头由三部分组成:
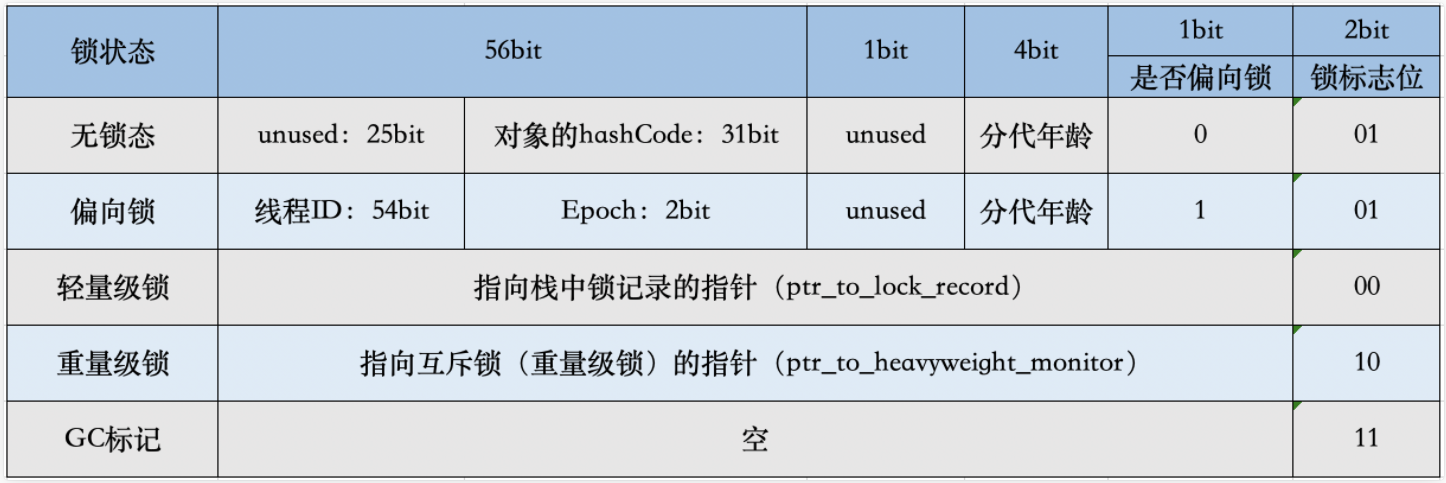
1)、Mark Word
MarkWord用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、同步锁信息、偏向锁标识等等。Mark Word在32位JVM中的长度是32bit,在64位JVM中长度是64bit。
通常我们都是使用的64位的JVM,Mark Word 在64位 JVM 中内部结构如下图:
2)、类型指针
类型指针指向对象的类元数据,虚拟机通过这个指针确定该对象是哪个类的实例。Java对象的类数据保存在方法区。
3)、数组长度(只有数组对象才有)
如果对象是一个数组,那么对象头还需要有额外的空间用于存储数组的长度。如果对象是数组类型,因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度。
二、实例数据
实例数据部分存放类的属性数据信息,包括父类的属性信息。
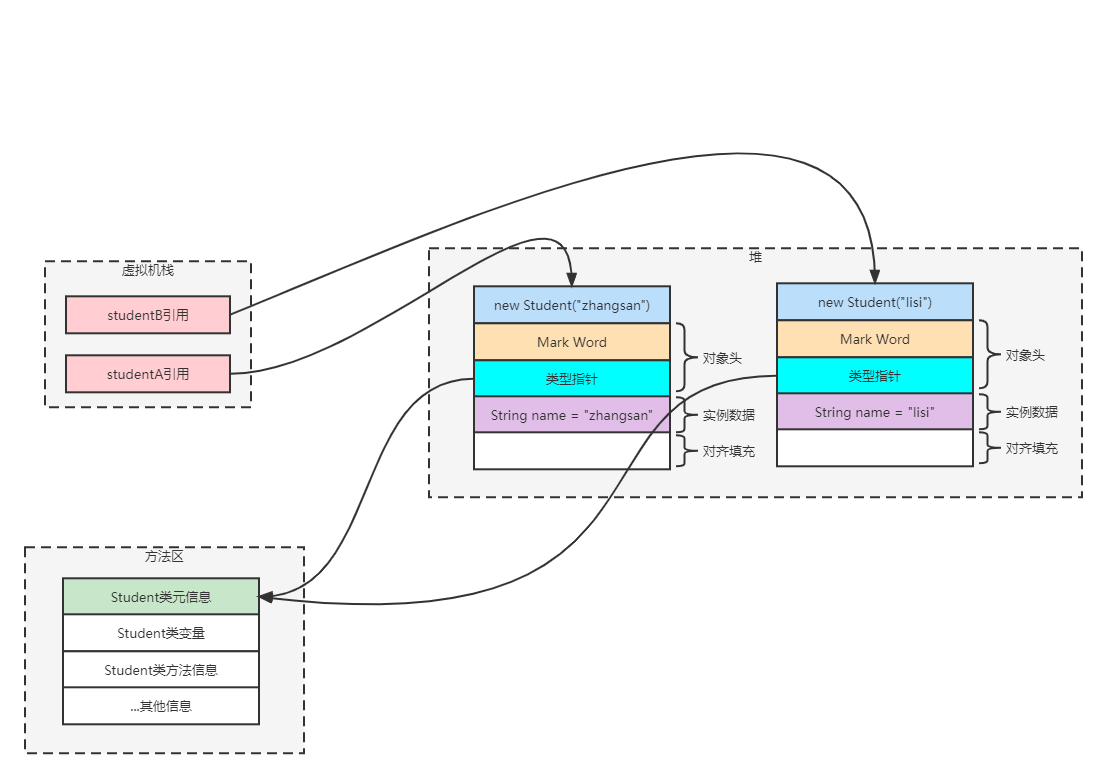
通过示例说明每个区域具体存放哪些内容:
- class Student {
- private String name;
- public Student(String name) {
- this.name = name;
- }
- }
- public class Demo {
- public static void main(String[] args) {
- Student studentA = new Student("zhangsan");
- Student studentB = new Student("lisi");
- }
- }
JVM结构图如下所示:
三、对齐填充
由于虚拟机要求对象起始地址必须是8字节的整数倍,所以后面有几个字节用于把对象的大小补齐至8字节的整数倍,没有特别的功能,对齐填充不是必须存在的,仅仅是为了字节对齐。
为什么必须是8个字节?
根据“计算机组成原理”,8个字节是计算机读取和存储的最佳实践。
四、使用JOL工具分析对象内存布局
接下来我们使用JOL(Java Object Layout)工具,它是一个用来分析JVM中Object布局的小工具。包括Object在内存中的占用情况,实例对象的引用情况等等。
直接在maven工程中加入对应的依赖:
- <dependency>
- <groupId>org.openjdk.jolgroupId>
- <artifactId>jol-coreartifactId>
- <version>0.9version>
- dependency>
通过JOL查看new Object()的对象布局信息:
- public class JOLDemo {
- public static void main(String[] args) {
- Object obj = new Object();
- System.out.println("十进制hashCode = " + obj.hashCode());
- System.out.println("十六进制hashCode = " + Integer.toHexString(obj.hashCode()));
- System.out.println("二进制hashCode = " + Integer.toBinaryString(obj.hashCode()));
- String str = ClassLayout.parseInstance(obj).toPrintable();
- System.out.println(str);
- }
- }
运行结果如下:
- 十进制hashCode = 1956725890
- 十六进制hashCode = 74a14482
- 二进制hashCode = 1110100101000010100010010000010
- java.lang.Object object internals:
- OFFSET SIZE TYPE DESCRIPTION VALUE
- 0 4 (object header) 01 82 44 a1 (00000001 10000010 01000100 10100001) (-1589345791)
- 4 4 (object header) 74 00 00 00 (01110100 00000000 00000000 00000000) (116)
- 8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
- 12 4 (loss due to the next object alignment)
- Instance size: 16 bytes
- Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
解释下各个字段的含义:
●OFFSET是偏移量,也就是到这个字段位置所占用的字节数;
●SIZE是后面类型的大小;
●TYPE是Class中定义的类型;
●DESCRIPTION是类型的描述;
●VALUE是TYPE在内存中的值;从上图可以看出Object obj = new Object();在内存中占16个字节,注意最后面的(loss due to the next object alignment)其实就是对齐填充的字节数,这里由于Object obj = new Object();没有实例数据,对象头总共占用了12个字节(默认开启了指针压缩-XX:+UseCompressedOops),由于虚拟机要求对象起始地址必须是8字节的整数倍,所以还需要对齐填充4个字节,达到2倍的8bit。

-
相关阅读:
数字货币swap交易所逻辑系统开发分析方案
视频封面:从视频中提取封面,轻松制作吸引人的视频
野火A7学习第十次(状态机相关)
算法试题——每日一练
SOLIDWORKS参数化设计之干涉检查
Python UI自动化测试详解
多任务学习(MTL)--学习笔记
谷粒商城实战笔记-142-性能压测-压力测试-Apache JMeter安装使用
devops-5-jenkins
异步 PHP — 多进程、多线程和协程
- 原文地址:https://blog.csdn.net/Weixiaohuai/article/details/126281978

