-
【ML】机器学习数据集:sklearn中分类数据集介绍
在机器学习的教程中,我们会看到很多的demo,这些demo都是基于python中自带的数据集。今天我们将介绍sklearn中几个常用的分类预测数据集。本教程使用的sklearn版本是1.0.2。1.乳腺癌分类数据集(二分类)
数据集加载代码:
from sklearn.datasets import load_breast_cancer data = load_breast_cancer() X = data.data y = data.target- 1
- 2
- 3
- 4
- 5
为了便于方便查看加载的数据集,我们可以使用jupyter notebook或者spyder编辑器。我们以spyder编辑器为例:
运行加载数据集的代码,右侧会出现变量;

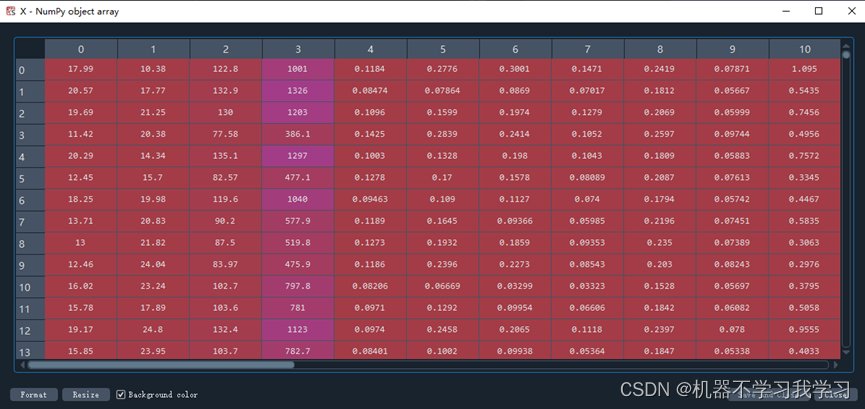
X是输入模型的数据:
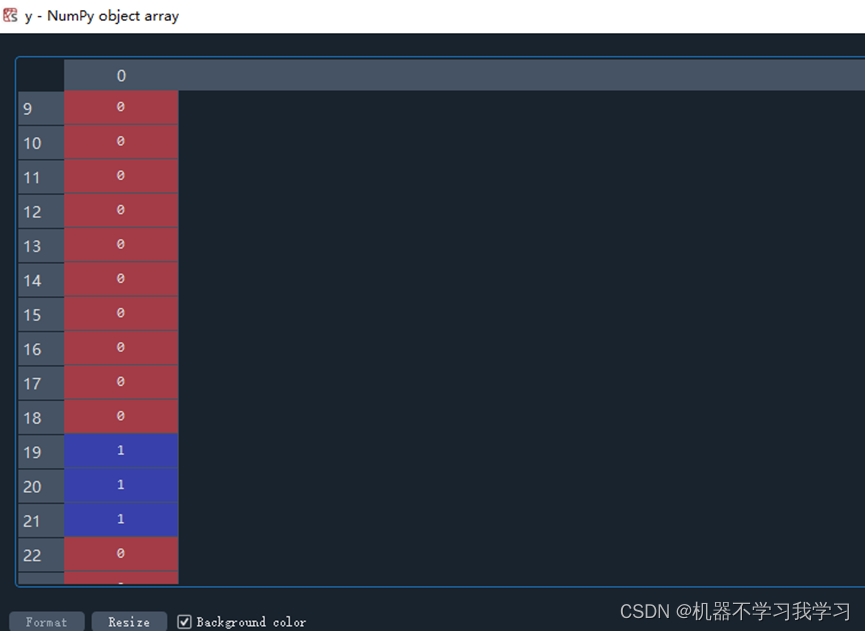
y是数据对应的标签:
双击点开变量“data”:
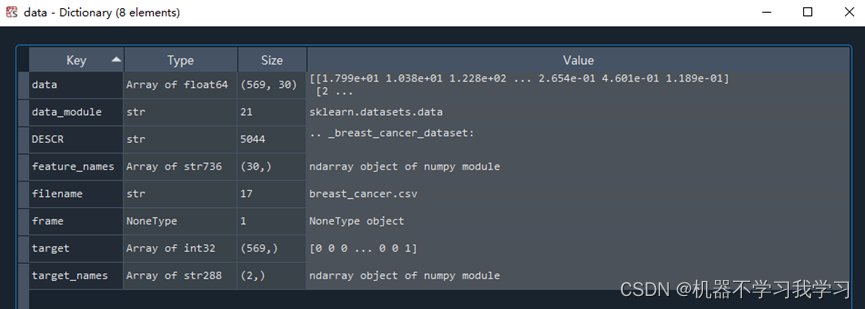
data: 569条数据,每条数据30维,即每条数据30个特征,这30个特征的名称存储在feature_names变量中,分别为[‘mean radius’, ‘mean texture’, ‘mean perimeter’, ‘mean area’, ‘mean smoothness’, ‘mean compactness’, ‘mean concavity’, ‘mean concave points’, ‘mean symmetry’, ‘mean fractal dimension’, ‘radius error’, ‘texture error’, ‘perimeter error’, ‘area error’, ‘smoothness error’, ‘compactness error’, ‘concavity error’, ‘concave points error’, ‘symmetry error’, ‘fractal dimension error’, ‘worst radius’, ‘worst texture’, ‘worst perimeter’, ‘worst area’, ‘worst smoothness’, ‘worst compactness’, ‘worst concavity’, ‘worst concave points’, ‘worst symmetry’, ‘worst fractal dimension’]
2.鸢尾花分类数据集(三分类)
数据集加载代码:
from sklearn.datasets import load_iris data = load_iris() X = data.data y = data.target- 1
- 2
- 3
- 4
- 5
为了便于方便查看加载的数据集,我们可以使用jupyter notebook或者spyder编辑器。我们以spyder编辑器为例:

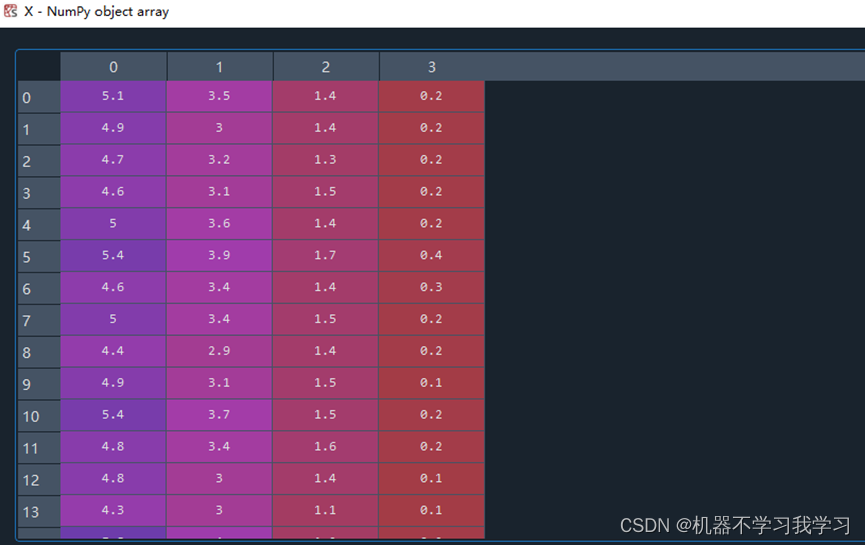
X是输入模型的数据:
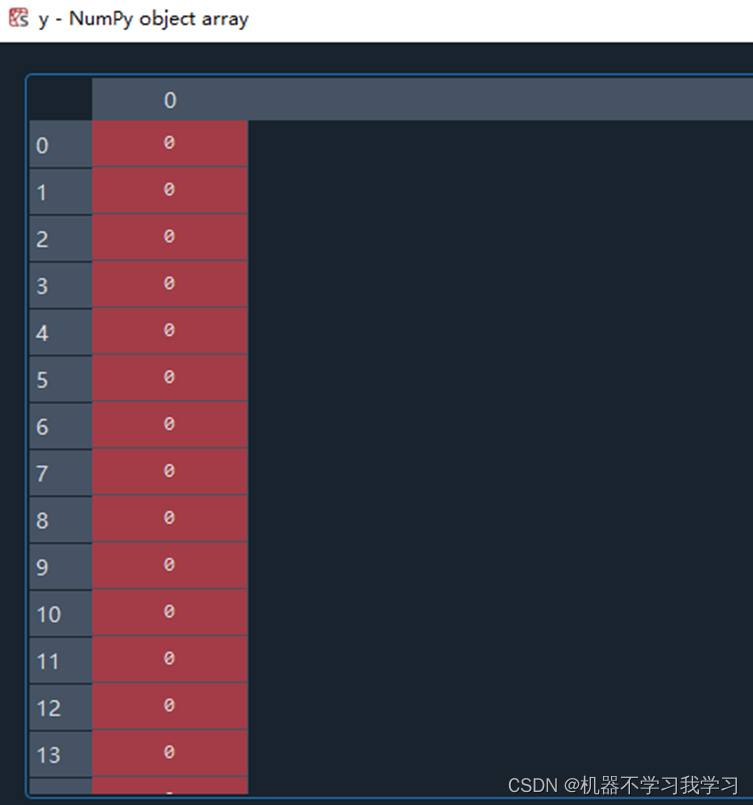
y是数据对应的标签:
双击点开变量“data”:
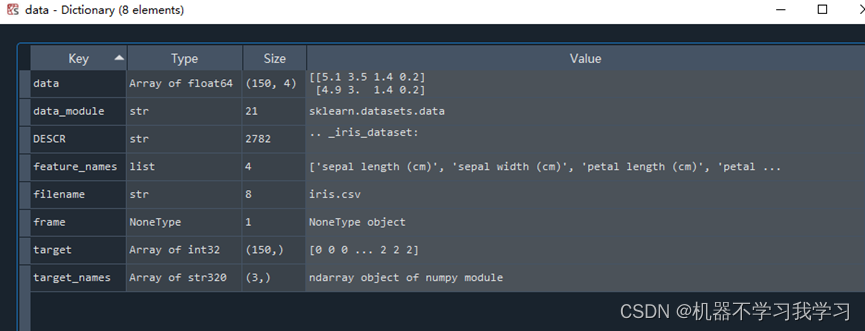
data: 150条数据,每条数据4维,即每条数据4个特征,这4个特征的名称存储在feature_names变量中,分别为[‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’]3.葡萄酒分类数据集(三分类)
数据集加载代码:
from sklearn.datasets import load_wine data = load_wine() X = data.data y = data.target- 1
- 2
- 3
- 4
- 5
为了方便查看加载的数据集,我们可以使用jupyter notebook或者spyder编辑器。我们以spyder编辑器为例:
运行加载数据集的代码,右侧会出现变量;

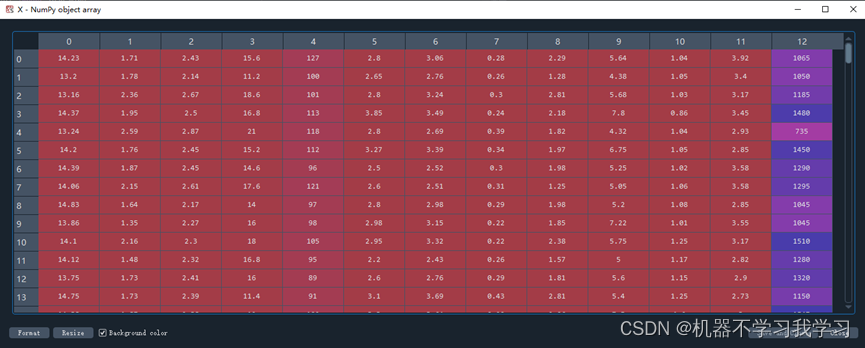
X是输入模型的数据:
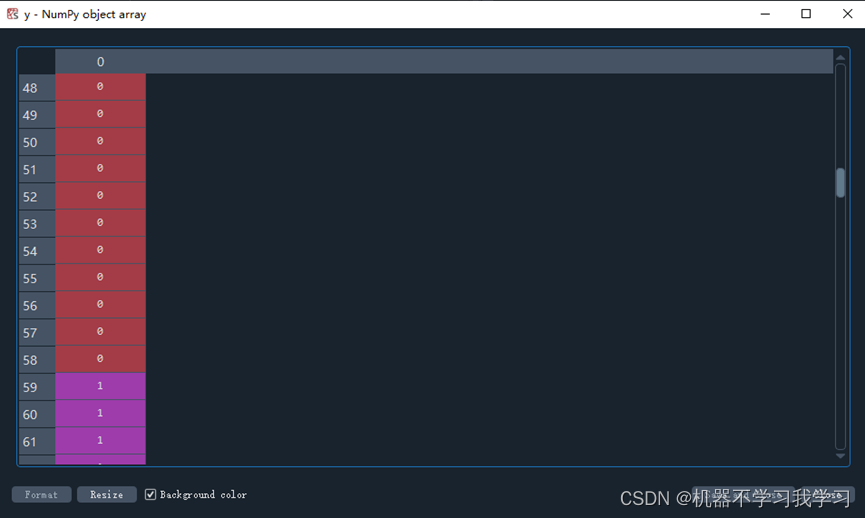
y是数据对应的标签:
双击点开变量“data”:
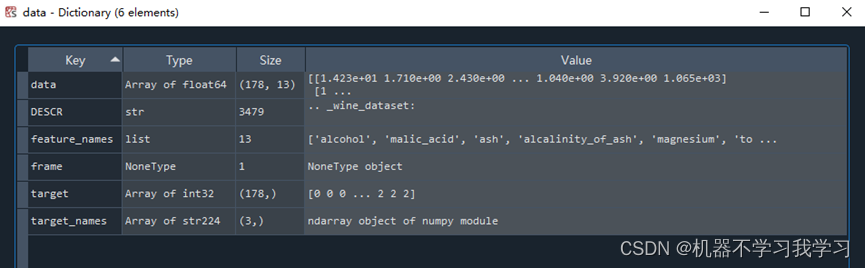
data: 178条数据,每条数据13维,即每条数据13个特征,这13个特征的名称存储在feature_names变量中,分别为[‘alcohol’, ‘malic_acid’, ‘ash’, ‘alcalinity_of_ash’, ‘magnesium’, ‘total_phenols’, ‘flavanoids’, ‘nonflavanoid_phenols’, ‘proanthocyanins’, ‘color_intensity’, ‘hue’, ‘od280/od315_of_diluted_wines’, ‘proline’]
4.手写数字分类数据集(十分类)
数据集加载代码:
from sklearn.datasets import load_digits data = load_digits() X = data.data y = data.target- 1
- 2
- 3
- 4
- 5
为了方便查看加载的数据集,我们可以使用jupyter notebook或者spyder编辑器。我们以spyder编辑器为例:
运行加载数据集的代码,右侧会出现变量;

X是输入模型的数据:
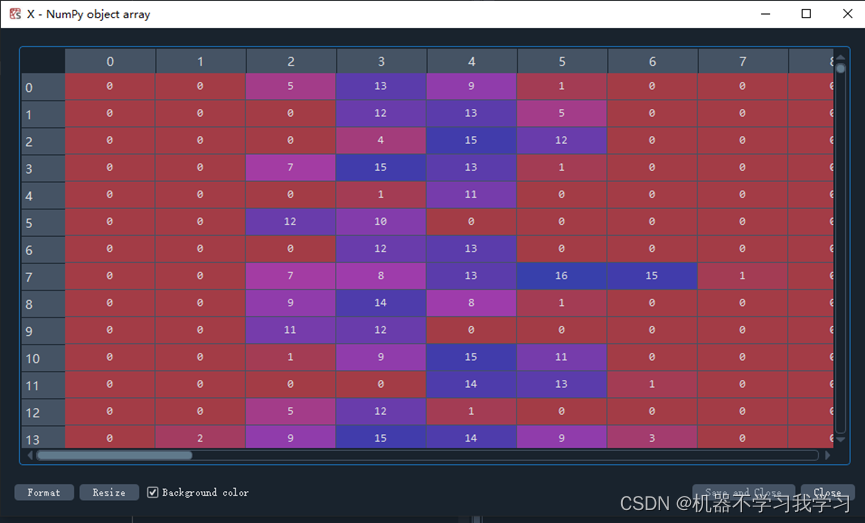
y是数据对应的标签: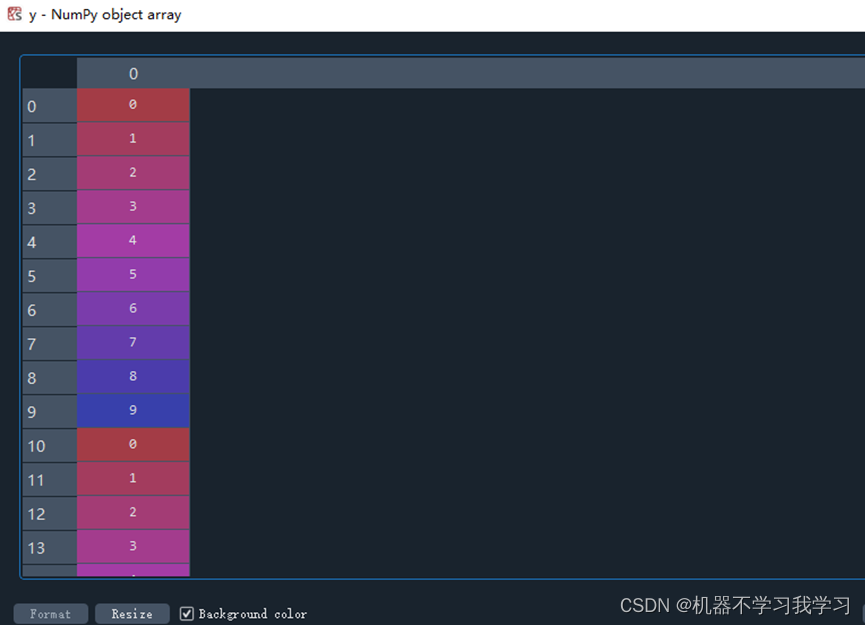
双击点开变量“data”:

data: 1797条数据,每条数据64维,即每条数据64个特征,这64个特征的名称存储在feature_names变量中,分别为[‘pixel_0_0’, ‘pixel_0_1’, ‘pixel_0_2’, ‘pixel_0_3’, ‘pixel_0_4’, ‘pixel_0_5’, ‘pixel_0_6’, ‘pixel_0_7’, ‘pixel_1_0’, ‘pixel_1_1’, ‘pixel_1_2’, ‘pixel_1_3’, ‘pixel_1_4’, ‘pixel_1_5’, ‘pixel_1_6’, ‘pixel_1_7’, ‘pixel_2_0’, ‘pixel_2_1’, ‘pixel_2_2’, ‘pixel_2_3’, ‘pixel_2_4’, ‘pixel_2_5’, ‘pixel_2_6’, ‘pixel_2_7’, ‘pixel_3_0’, ‘pixel_3_1’, ‘pixel_3_2’, ‘pixel_3_3’, ‘pixel_3_4’, ‘pixel_3_5’, ‘pixel_3_6’, ‘pixel_3_7’, ‘pixel_4_0’, ‘pixel_4_1’, ‘pixel_4_2’, ‘pixel_4_3’, ‘pixel_4_4’, ‘pixel_4_5’, ‘pixel_4_6’, ‘pixel_4_7’, ‘pixel_5_0’, ‘pixel_5_1’, ‘pixel_5_2’, ‘pixel_5_3’, ‘pixel_5_4’, ‘pixel_5_5’, ‘pixel_5_6’, ‘pixel_5_7’, ‘pixel_6_0’, ‘pixel_6_1’, ‘pixel_6_2’, ‘pixel_6_3’, ‘pixel_6_4’, ‘pixel_6_5’, ‘pixel_6_6’, ‘pixel_6_7’, ‘pixel_7_0’, ‘pixel_7_1’, ‘pixel_7_2’, ‘pixel_7_3’, ‘pixel_7_4’, ‘pixel_7_5’, ‘pixel_7_6’, ‘pixel_7_7’]
5.其他数据集
当然,除了上述介绍的分类数据集,sklearn.datasets还有其他的分类数据集,例如,新闻文本分类数据集(datasets.fetch_20newsgroups、datasets.fetch_20newsgroups_vectorized,二十分类),森林植被类型数据集(datasets.fetch_covtype,七分类),入侵检测数据集(datasets.fetch_kddcup99,二十三分类),人脸数据集分类(datasets.fetch_lfw_pair、datasets.fetch_lfw_people、datasets.fetch_lfw_people)等等。
参考资料
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
https://blog.csdn.net/weixin_39652646/article/details/109939004 -
相关阅读:
即将开幕!阿里云飞天技术峰会邀您一同探秘云原生最佳实践
C18-PEG- ALD批发_C18-PEG-CHO_C18-PEG-醛基
如何成为一名高级数字 IC 设计工程师(1-6)Verilog 编码语法篇:经典数字 IC 设计
【C++】C++ 引用详解 ⑥ ( 普通变量 / 一级指针 / 二级指针 做函数参数的作用 )
Spring Cloud项目(二)——集成Nacos作为配置中心
【日常】爬虫技巧进阶:textarea的value修改与提交问题(以智谱清言为例)
LabVIEW中PID控制的的高级功能
J2EE基础-自定义MVC(上)
中英文拼写检测纠正开源项目使用入门 word-checker 1.1.0
【无百度智能云与实体经济“双向奔赴”: 一场1+1>2的双赢 标题】
- 原文地址:https://blog.csdn.net/AugustMe/article/details/126261457