-
Python爬虫之Urllib(内置库)
活动地址:CSDN21天学习挑战赛
以下是关于Python~Urllib内置库的使用
🥧 续Python入门点击跳转到Python入门文章
🥧快,跟我一起爬起来💪
🕷🐍💀🐗🐛
🐜🐶😺🕷🐿
🦄🐆🐯🐅🐘
🐐🐐🐊🐵🐒提示:以下是本篇文章正文内容爬虫🐛

什么是爬虫❓
- 网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 通俗来讲,假如你需要互联网上的信息,如商品价格,图片视频资源等,但你又不想或者不能自己一个一个自己去打开网页收集,这时候你便写了一个程序,让程序按照你指定好的规则去互联网上收集信息,这便是爬虫,我们熟知的 百度,谷歌 等搜索引擎背后其实也是一个巨大的 爬虫 。
- 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据
解释1:通过一个程序,根据Url(https://www.baidu.com/)进行爬取网页,获取有用信息
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息爬虫核心❓
- 爬取网页:爬取整个网页 包含了网页中所有得内容
- 解析数据:将网页中你得到的数据 进行解析
- 难点:爬虫和反爬虫之间的博弈
- 反爬策略:
1、以浏览器的形式访问
2、部署多个应用分别抓取,降低单节点频繁访问
……
爬虫的用途❓
- 12306抢票,网络投票等
- 通过爬虫爬取数据
- 去免费的数据网站爬取数据
……
爬虫分类❓
- 通用爬虫:
-
功能:
访问网页👉抓取数据👉数据存储👉数据处理👉获取数据
-
缺点
- 抓取的数据大多是无用的
- 不能根据用户的需求来精准获取数据
- 聚焦爬虫:
-
功能:
根据需求👉实现爬虫程序👉抓取需要的数据
-
设计思路
- 确定要爬取的url
如何获取Url❓ - 模拟浏览器通过http协议访问url,获取服务器返回的html代码
如何访问❓ - 解析html字符串(根据一定规则提取需要的数据)
如何解析❓
- 确定要爬取的url
- 增量式爬虫 (爬取更新的页面,新的信息)
- 深层网络爬虫(简而言之,提交表单的深层页面 构成:url列表,LVS列表,爬行控制器等)也是一些纲领性的内容,一定要有个底。
反爬的几种手段❓
-
User‐Agent:
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
-
代理IP:
- 简单的说,通过购买或使用免费(一般失败)ip代理,从不同的ip进行访问,这样就不会被封掉ip了。
- 什么是高匿名、匿名和透明代理?它们有什么区别?
1、使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
2、使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
3、使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。
-
验证码:
1、打码平台
2、云打码平台 -
JavaScript 参与运算,返回的是js数据 并不是网页的真实数据
- 解决方法:使用PhantomJS
- PhantomJS是一个可编程的无头浏览器.
- PhantomJS是一个Python包,他可以在没有图形界面的情况下,完全模拟一个浏览器,js脚本验证什么的再也不是问题了。
-
职业选手级别(代码混淆、动态加密方案、假数据,混淆数据等方式)
- 解决方法:持续对抗,直到对方放弃😀
-
赶紧爬起来👇🕷🕷🕷🕷🕷🕷
爬虫之Urllib的使用🐊
Python库的使用方法
使用Uellib爬取🔎源码
📰
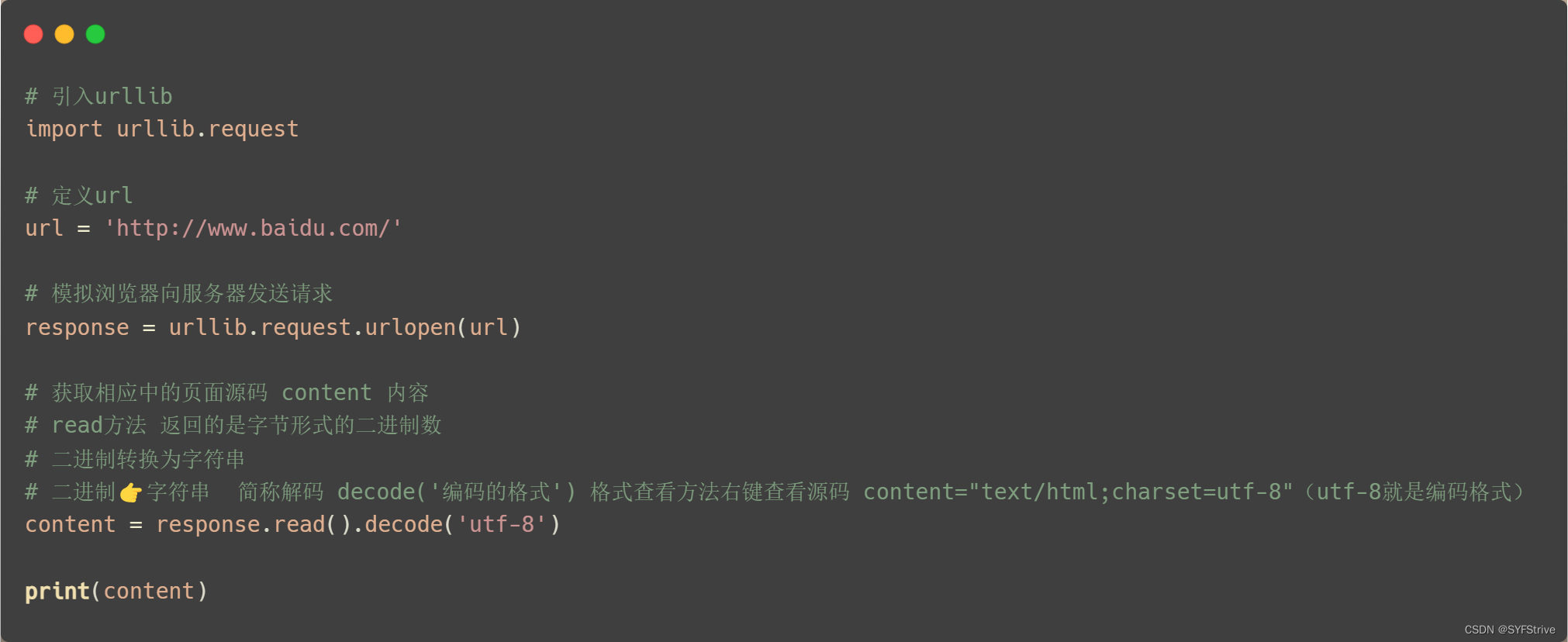
如👇图所示爬取成功

这时ctrl+a 👉 ctrl+c 👉 ctrl+v 👉 如下所示😁


Response响应(一个类型 六个方法)
- Response相应(一个类型 六个方法)
- 类型:HTTPResponse
- 方法:read readline readlines getcode geturl getheaders
使用如下:

使用Urllib简单爬取图片、视频和🔎源码 (保存到本地)
📰
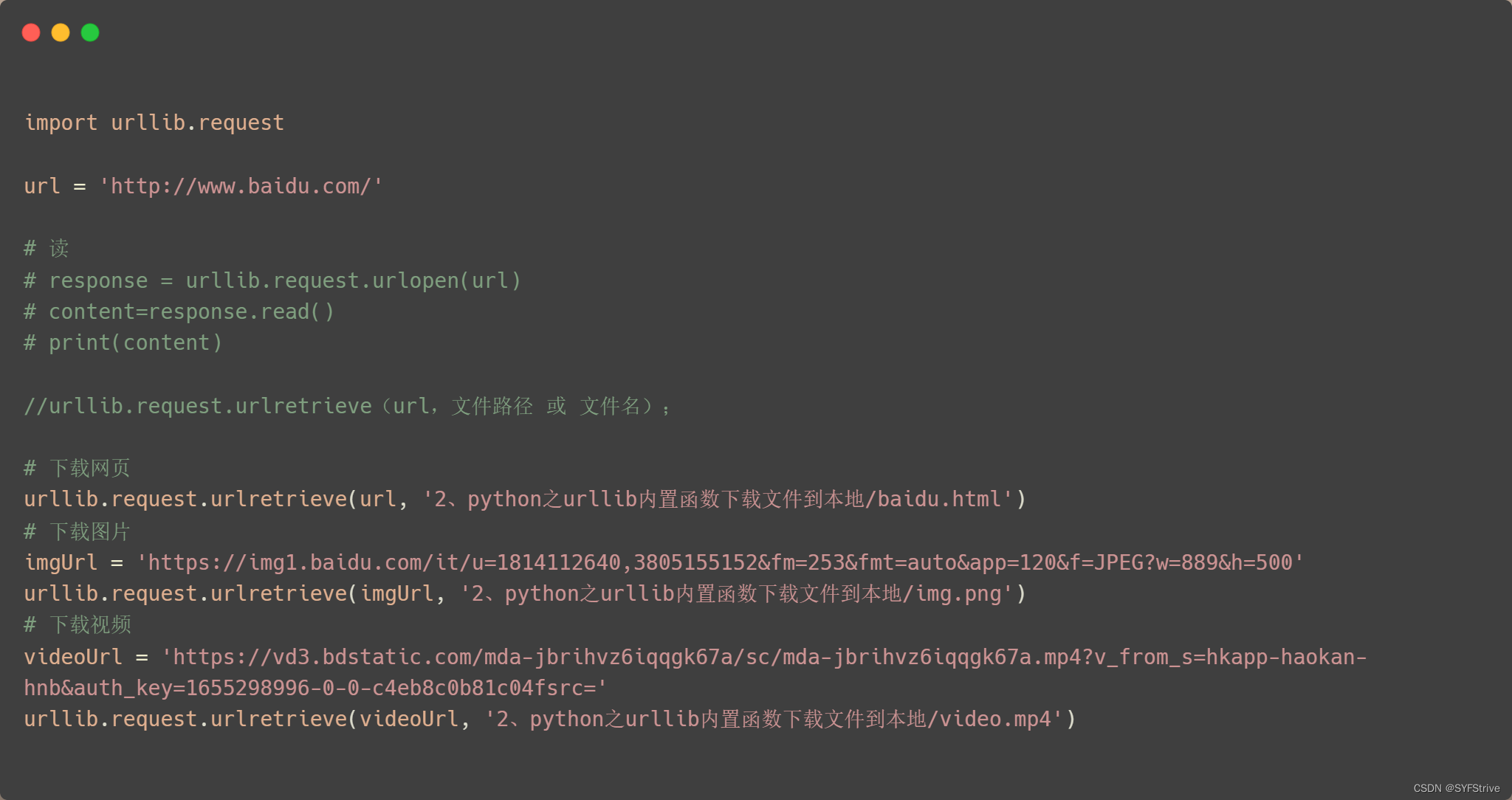
如下图(下载保存到本地):
爬虫之Urllib~UA反爬(定制对象)🐍

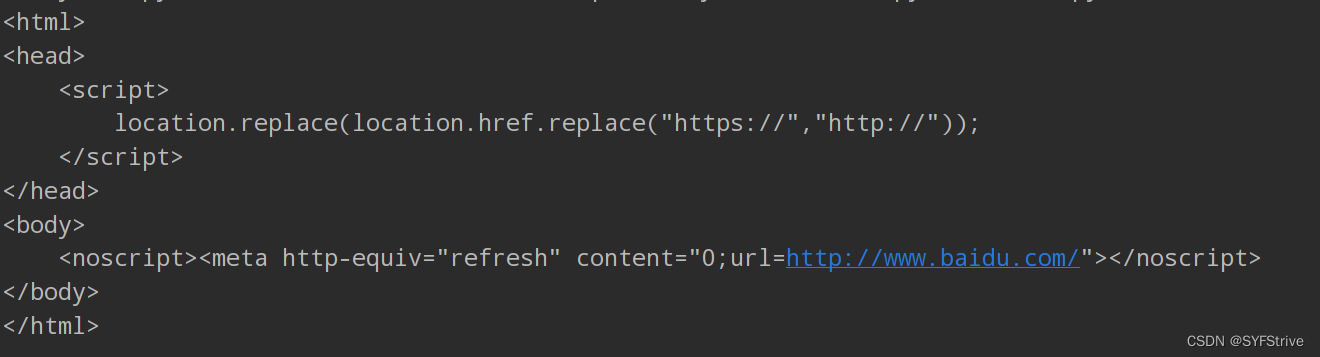
语法:request = urllib.request.Request()
📰演示:
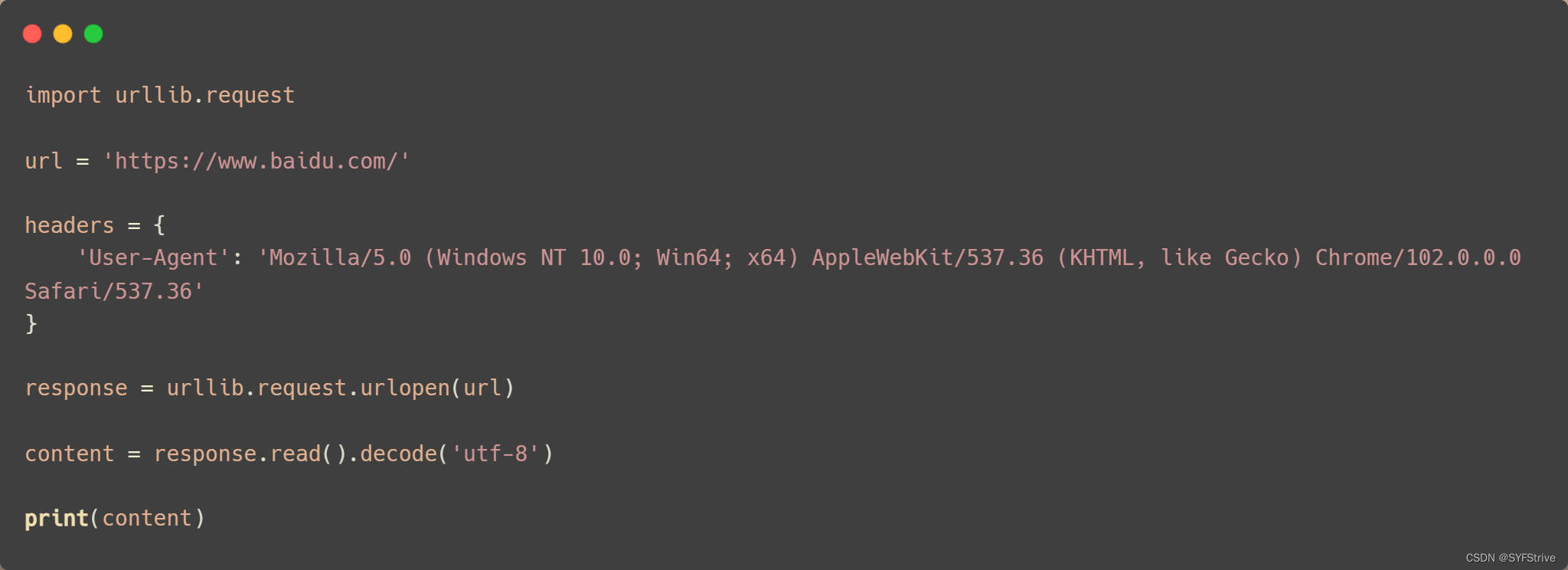
如👇图(遇到了UA反爬):
解决获得UA:
方法一:🔎跳转
方法二:开发工具找如 👇 图
得UA 👉 定制 👉 再次爬取
📰演示:
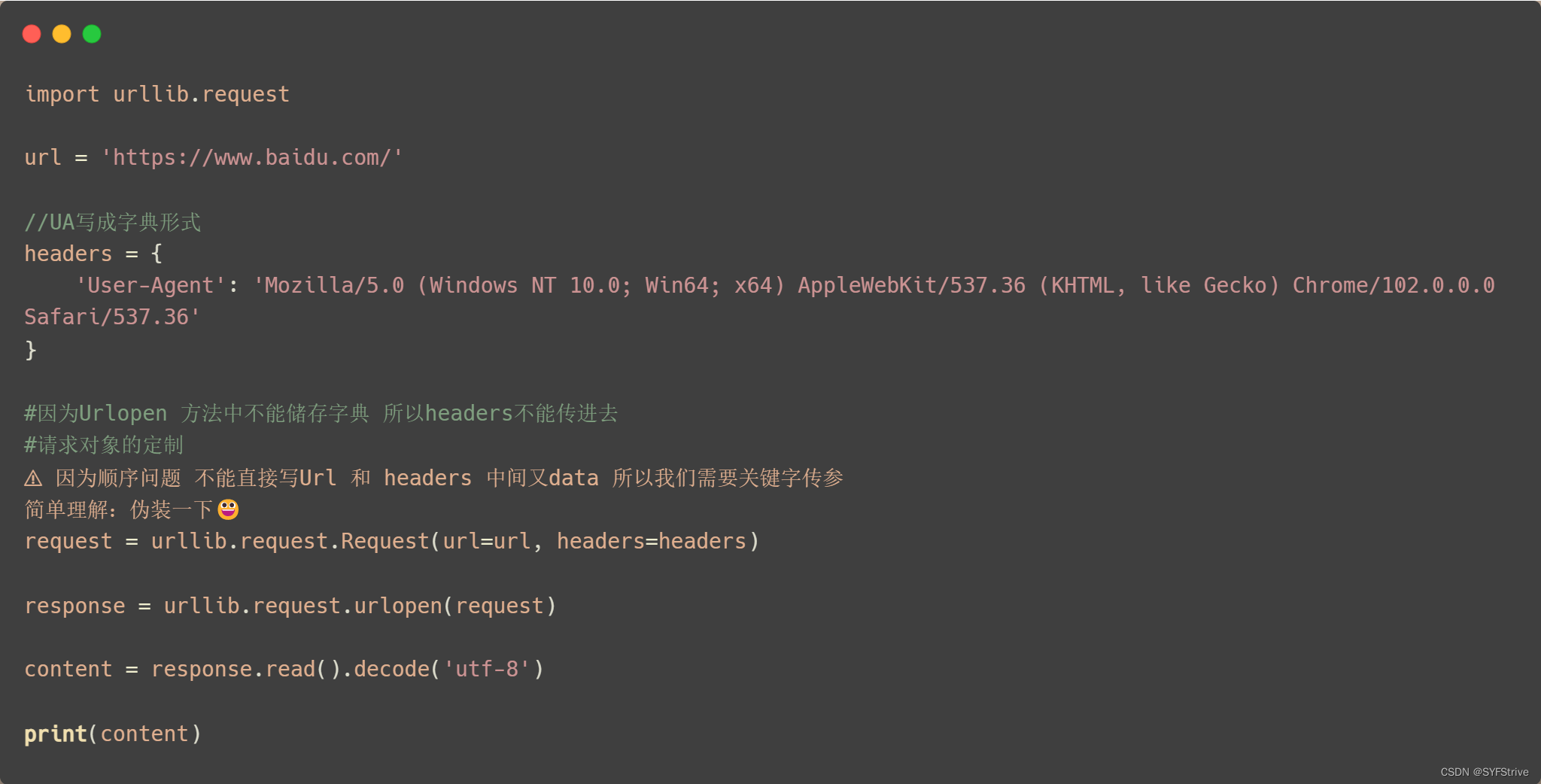
如下图(爬取成功🆗):
爬虫之Unicode编解码🐒
get请求方式☞单个参数
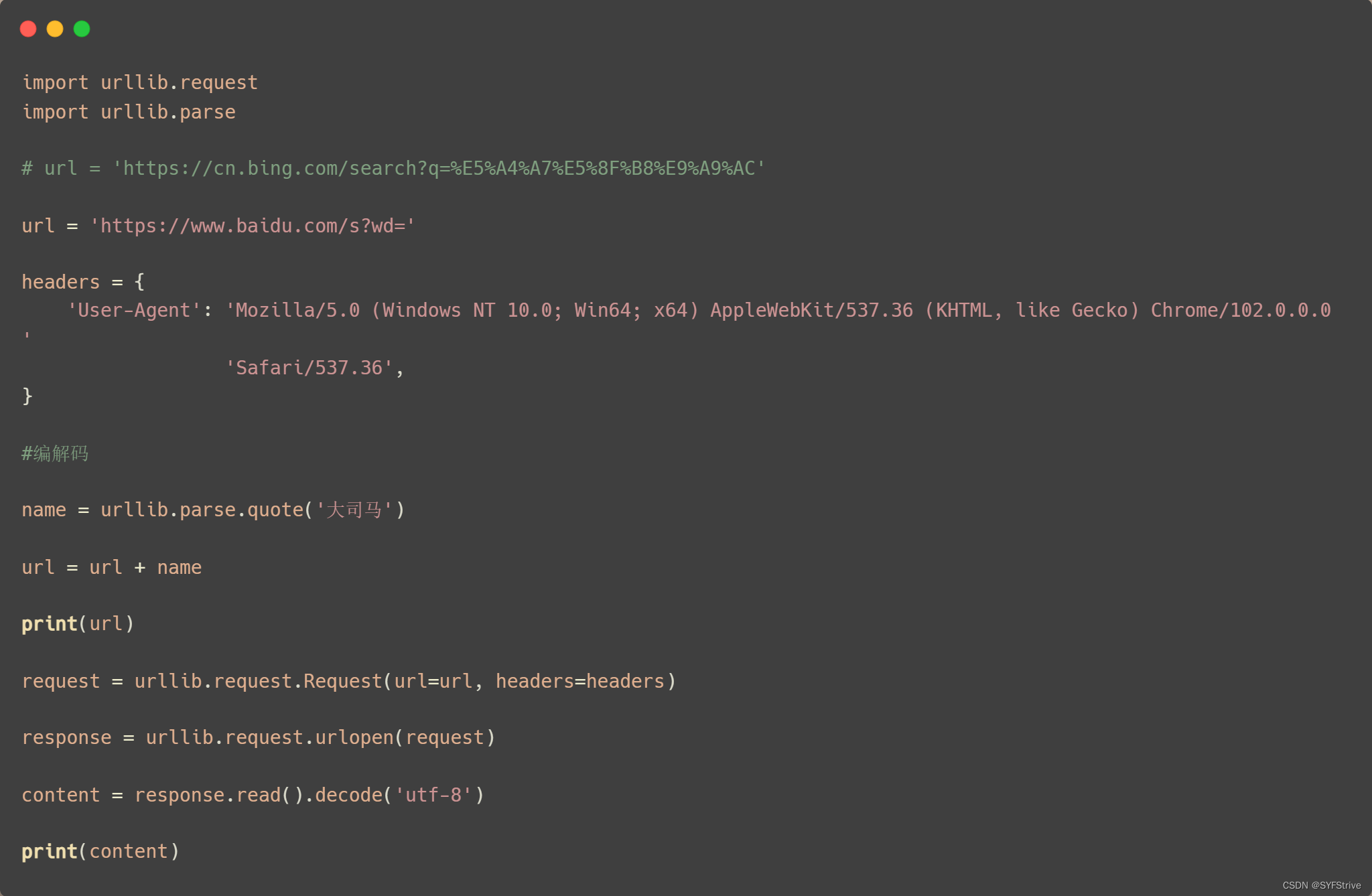
引入 import urllib.parse
语法::urllib.parse.quote()爬取链接:https://cn.bing.com/search?q=%E5%A4%A7%E5%8F%B8%E9%A9%AC
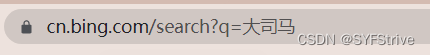
📰演示:

如👇图所示(我们已经爬取成功了):
url = ‘https://cn.bing.com/search?q=%E5%A4%A7%E5%8F%B8%E9%A9%AC’
但是url后面的%E5%91%A8%E6%9D%B0%E4%BC%A6(Unicode编码)让我们很难受(我们怎么才能直接把url变成 👉 url = 'https://cn.bing.com/search?q=大司马’❓)
这时就要用到编解码
📰编解码演示:
如下图所示(也是爬取成功的):


get请求方式☞多个参数
引入 import urllib.parse
语法:urllib.parse.urlencode(data)📰演示:
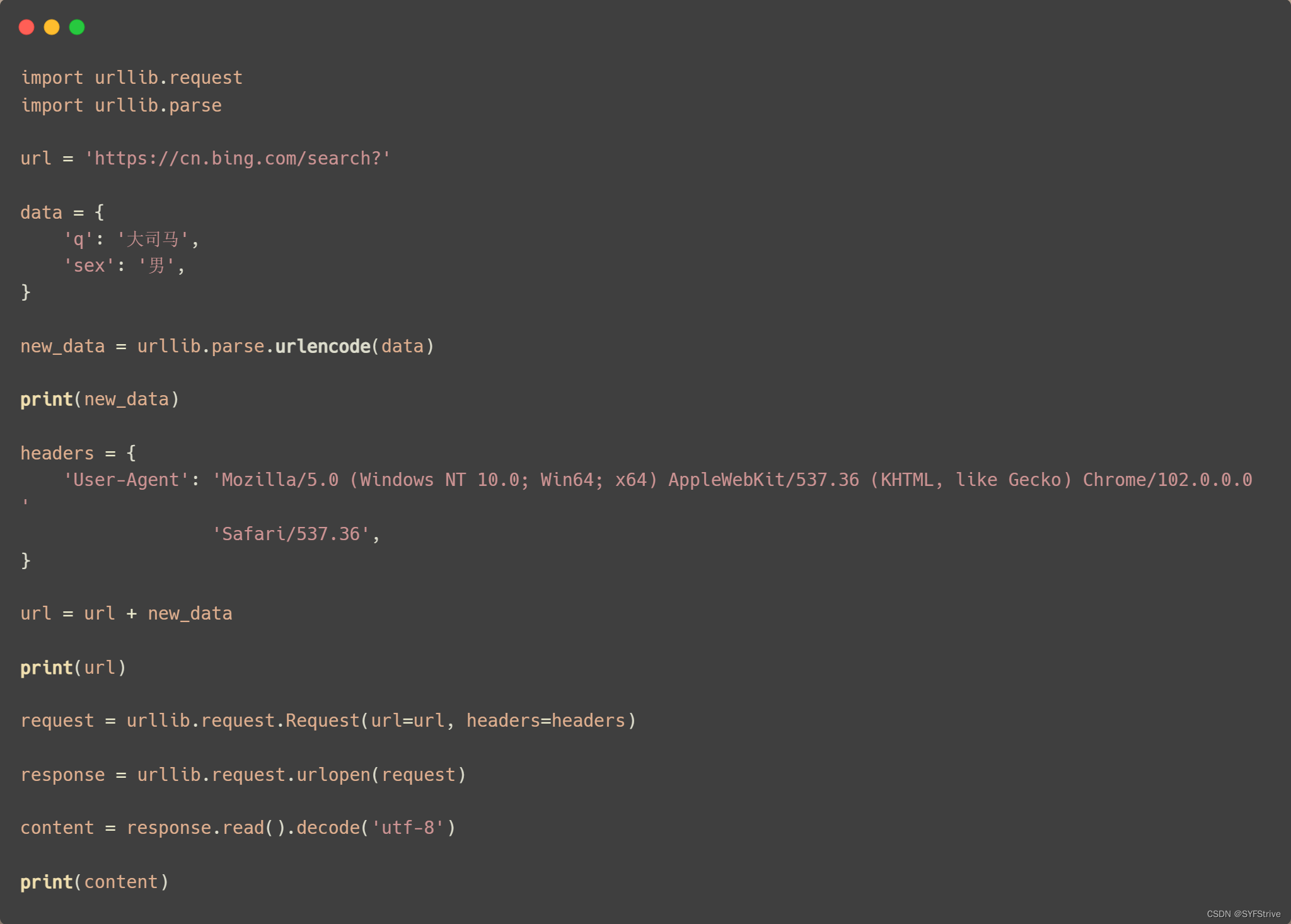
如下图所示(爬取成功):


爬虫之爬取🔎翻译(post请求)🐜
🔎翻译之Errno解析
- rrno:997 cookie失效
- errno:998 sign参数错误
- errno:999 post未提交from,to参数
- error:1000 需要翻译的字符串为空 # 记住,这个是error,也许是🔎发现自己的errno拼错了吧
爬虫之post 对比于 get
post VS get
- post请求的参数 必须要进行编码
- 编码后 必须调用encode方法
- post请求的参数是放在请求对象定制的参数中
import json
- Python json.loads()用法
- 参数:它接受一个字符串,字节或字节数组实例,该实例包含JSON文档作为参数。
- 返回:它返回一个Python对象。
普通的爬
普通爬如👇:

- 找规律
- 爬虫起始难度就在于找规律
- 如🔎翻译,当你输入每个字母时他都会发送一个参数到后台返回数据
- 这个参数就是kw,最终把kw当作参数就可以爬了😀( 其他类似)
- 接口URL如👇
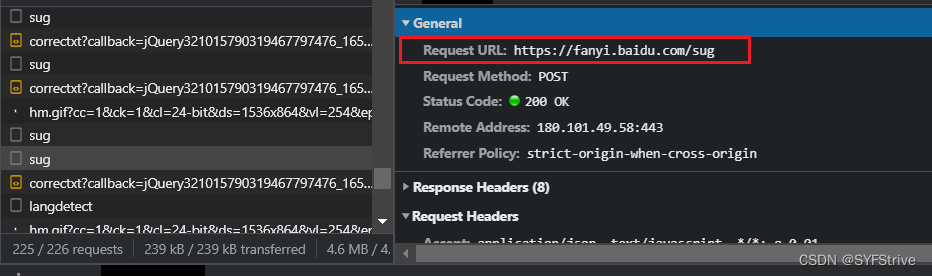


📰演示:

如下图所示(爬取成功):

详细爬(Cookie反爬)
详细爬如👇:

- 接口&&参数
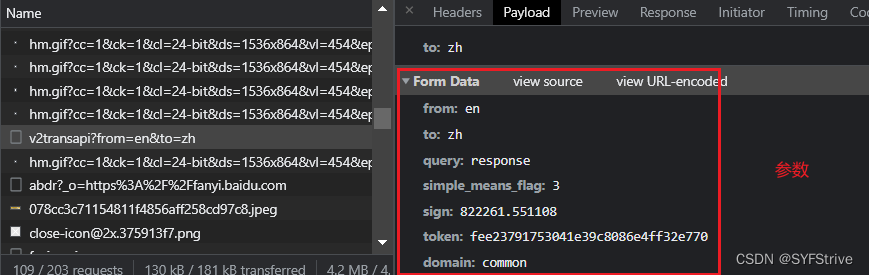
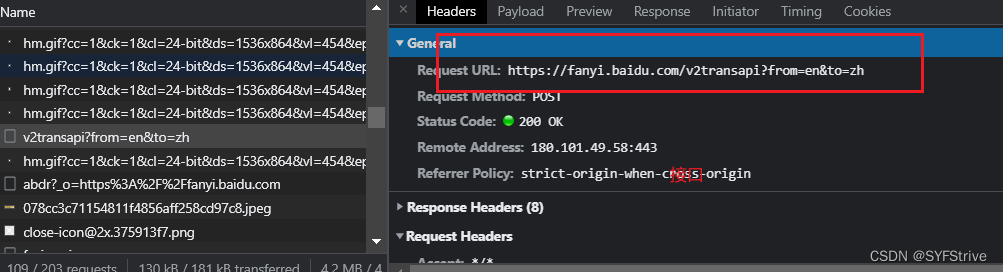
- 遇到Cookie反爬反扒(解决方法如👇):
-
手动处理
在开发手动捕获cookie,将其封装在headers中
应用场景:cookie没有有效时长且不是动态变化 -
自动处理
使用session机制
使用场景:动态变化的cookie
session对象:该对象和requests模块用法几乎一致.如果在请求的过程中产生了cookie,如果该请求使用session发起的,则cookie会被自动存储到session中
📰演示:
如下图所示(爬取成功):


最后
本文章到这里就结束了,觉得不错的请给我专栏点点订阅,你的支持是我们更新的动力,感谢大家的支持,希望这篇文章能帮到大家

下篇文章再见ヾ( ̄▽ ̄)ByeBye

-
相关阅读:
诚信型性格分析,诚信型人格的职业发展
UCOSII
Python代码写好了怎么运行
ubuntu在PowerShell的vi编辑器蓝色注释看不见
【数据结构】顺序表实现通讯录
CPT203-Software Engineering
Web3钱包和身份验证:安全和去中心化的新标准
STM32正点原子TFT-LCD1.3寸(240x240)液晶显示屏移植
医学图像匹配,c++计算归一化互相关
58.【c/c++优先级详解】
- 原文地址:https://blog.csdn.net/m0_61490399/article/details/126118270

