-
AcWing 831. KMP字符串
分析:
前置
字符串匹配问题中,给出两个字符串 text 和 pattern (本题中 text 为 S, pattern 为 P),需要判断 pattern 是否是 text 的子串。一般把 text 称为文本串,pattern 称为模式串。暴力的解法为:
枚举文本串 text 的起始位置 i ,然后从该位开始逐位与模式串 pattern 进行匹配。如果匹配过程中每一位都相同,则匹配成功;否则,只要出现某位不同,就让文本串 text 的起始位置变为 i + 1,并从头开始模式串 pattern 的匹配。假设 m 为文本串的长度,n 为模式串的长度。时间复杂度为 O ( n m ) O(nm) O(nm)。显然,当 n 和 m 都达到 1 0 5 10^5 105 级别时无法承受。那我们应该怎么做呢?这里先题前剧透一些 kmp 的优化步骤,但不会太深入,只是让我们有个直观的认识,找到前进的方向。对于 text 和 pattern 若存在一个 i(i << n, i << m),使得 text[i + 1] != pattern[i + 1] 说明当前匹配失败,我们肯定不会使用上面暴力解的做法,我们可以想:
能否在 text[i] 和 pattern[i] 中找到一个变量,记成什么? length 如何?使得 pattern[0…length] == pattern[i - length…i] == text[i - length…i] 这三部分相等,这样 pattern 就不用从头开始匹配(因为 pattern 前缀和 text 后缀相等,立即推!一定能匹配成功)。而是从 pattern[length+ 1] 与 text[i] 匹配,成功的话就接着往下走呗,不成功再说~
好的,我们点到为止。上面的小剧透想不清楚也没有关系,接下来我们将循序渐进地来思考这个步骤如何实现。
偶遇 next
面对 KMP 这种复杂的算法,我们必须要将其拆解,逐个击破。假设有一个字符串 s (下标从 0 开始),那么它以 i 号位作为结尾的子串就是 s[0…i]。对该子串来说,长度为 k + 1 的前缀与后缀分别是 s[0…k] 与 s[i-k…i]。我们构造一个 int 型数组(叫啥无所谓,就叫它 next吧)。其中,next[i] 表示使字串 s[0…i] 中前缀 s[0…k] 等于后缀 s[i-k…i] 的最大的 k。(注意相等的前缀、后缀在原字串中不能是 s[0…i] 本身。这点很重要,在后面感性分析时会用到);如果找不到相等的前后缀,就令 next[i] = -1。显然,next[i] 就是所求最长相等前后缀中前缀最后一位的下标。
接下来通过一个例子,给出 next 数组的变化过程。s = “abababc”。对每个 next[i] 的计算都给出两种阅读方式。建议先看一下第一种并搞清楚第二种。
第一种方法直接画线画出子串 s[0…i] 的最长相等前后缀:

第二种方法在上面的行提供后缀,下面的行提供前缀,再将相等的最长前后缀框起来。
我们对这两种方法进行一个感性的分析 (如果上面两图能够完全理解,此部分可以跳过):- i = 0:子串 s[0…i] 为 “a”,由于找不到相等的前后缀(前后缀均不能是子串 s[0…i] 本身),因此令 next[0] = -1。
- i = 1:子串 s[0…i] 为 “ab”,由于找不到相等的前后缀(前后缀均不能是子串 s[0…i] 本身),因此令 next[1] = -1。
- i = 2:子串 s[0…i] 为 “aba”,能使前后缀相等的最大的 k 等于 0,此时后缀 s[i-k…i] 为 “a”,前缀 s[0…k] 也为 “a”;而当 k = 1 时,后缀 [i-k…i] 为 “ba”,前缀 s[0…k]为"ab",它们不相等,因此 next[2] = 0。
- i = 3:子串 s[0…i] 为 “abab”,能使前后缀相等的最大的 k 等于 1,此时后缀 s[i-k…i] 为 “ab”,前缀 s[0…k] 也为 “ab”;而当 k = 2 时后缀 s[i-k…i] 为 “bab”,前缀 s[0…k] 为 “aba”,它们不相等,因此 next[3] = 1。
- i = 4:子串 s[0…i] 为 “ababa”,能使前后缀相等的最大的 k 等于 2,此时后缀 s[i-k…i] 为 “aba”,前缀 s[0…k] 也为 “aba”;而当 k = 3 时后缀 s[i-k…i] 为"baba",前缀 s[0…k] 为 “abab”,它们不相等,因此 next[4] = 2。
- i = 5:子串 s[0…i] 为 “ababaa”,能使前后缀相等的最大的 k 等于 0,此时后缀 s[i-k…i] 为 “aba”,前缀 s[0…k] 也为 “a”;而当 k = 1 时后缀 s[i-k…i] 为 “aa”,前缀 s[0…k] 为 “ab”,它们不相等,因此 next[5] = 0。
- i = 6:子串 s[0…i] 为 “ababaab”,能使前后缀相等的最大的 k 等于 1,此时后缀 s[i-k…i] 为 “ab”,前缀 s[0…k] 也为 “ab”;而当 k = 2 时后缀 s[i-k…i] 为 “aab”,前缀 s[0…k] 为 “aba”,它们不相等,因此 next[6] = 1。
这里再次强调一下:next[i] 就是使子串 s[0…i] 有最长相等前后缀的前缀的最后一位的下标。
这句话初读会有些绕,但请务必搞清楚,我们将其命名为至尊概念,在后面会用到。与 next 一决胜负
那么怎么求解 next 呢?暴力做法是可行的,但需要遍历太多次了。下面用 “递推” 的方式来高效求解 next 数组,也就是说我们假设已经求出了 next[0] ~ next[i-1],用它们来推算出 next[i]。
还是用我们刚刚感性认识的 s = “abababc” 作为例子。假设已经有了 next[0] = -1、next[1] = -1、next[2] = 0、next[3] = 1,现在来求解 next[4]。如下图所示,当已经得到 next[3] = 1 时,最长相等前后缀为 “ab”,之后计算 next[4] 时,由于 s[4] == s[next[3] + 1] (这里的为什么要用 next[3]?想想至尊概念),因此可以把最长相等前后缀 “ab” 扩展为 “aba”,因此 next[4] = next[3] + 1,并令 j 指向 next[4]。

接着在此基础上求解 next[5]。如下图所示,当已经得到 next[4] = 2 时,最长相等前后缀为 “aba”,之后计算 next[5] 时,由于 s[5] != s[next[4] + 1],因此不能扩展当前相等前后缀,即不能直接通过 next[4] + 1 的方法得到 next[5]。既然相等前后缀没办法达到那么长,那不妨缩短一点!此时希望找到找到一个 j,使得 s[5] == s[j + 1] 成立,同时使得图中的波浪线 ~,也就是 s[0…j] 是 s[0…2] = “aba” 的后缀,而 s[0…j] 是 s[0…2] 的前缀是显然的。同时为了找到相等前后缀尽可能长,找到这个 j 应尽可能大。
实际上我们上图要求解的 ~ 部分,即 s[0…j] 既是 s[0…2] = “aba” 的前缀,又是 s[0…2] = “aba” 的后缀,同时又希望其长度尽可能长,那么 s[0…j] 就是 s[0…2] 的最长相等前后缀。也就是说,只需要令 j = next[2],然后再判断 s[5] == s[j + 1] 是否成立:如果成立,说明 s[0…j + 1] 是 s[0…5] 的最长相等前后缀,令 next[5] = j + 1 即可;如果不成立,就不断让 j = next[j],直到 j 回到了 -1,或是途中 s[5] == s[j + 1] 成立。
如上图所示,j 从 2 回退到 next[2] = 0,发现 s[5] == s[j + 1] 不成立,就继续让 j 从 0 回退到 next[0] = -1;由于 j 已经回退到了 -1,因此不再继续回退。这是发现 s[i] == s[j + 1] 成立,说明 s[0…j + 1] 是 s[0…5] 的最长相等前后缀,于是令 next[5] = j + 1 = -1 + 1 = 0,并令 j 指向 next[5]。下面总结 next 数组的求解过程,并给出代码:
- 初始化 next 数组,令 j = next[0] = -1。
- 让 i 在 1 ~ len - 1范围内遍历,对每个 i ,执行 3、4,以求解 next[i]。
- 直到 j 回退为 -1,或是 s[i] == s[j + 1] 成立,否则不断令 j = next[j]。
- 如果 s[i] == s[j + 1],则 next[i] = j + 1;否则 next[i] = j。
next[0] = -1; for (int i = 1, j = -1; i < len; i ++) { while (j != -1 && s[i] != s[j + 1]) // 前后缀匹配不成功 { // 反复令 j 回退到 -1,或是 s[i] == s[j + 1] j = next[j]; } if (s[i] == s[j + 1]) // 匹配成功 { j ++; // 最长相等前后缀变长 } next[i] = j; // 令 next[i] = j }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
还请搞清楚:我们刚刚只是对一个字符串进行的 next 数组处理!!!
hello, kmp!
在此基础上我们进入 kmp,有了上面求 next 数组的基础,kmp 算法就是在照葫芦画瓢,给定一个文本串 text 和一个模式串 pattern,然后判断模式串 pattern 是否是文本串 text 的子串。
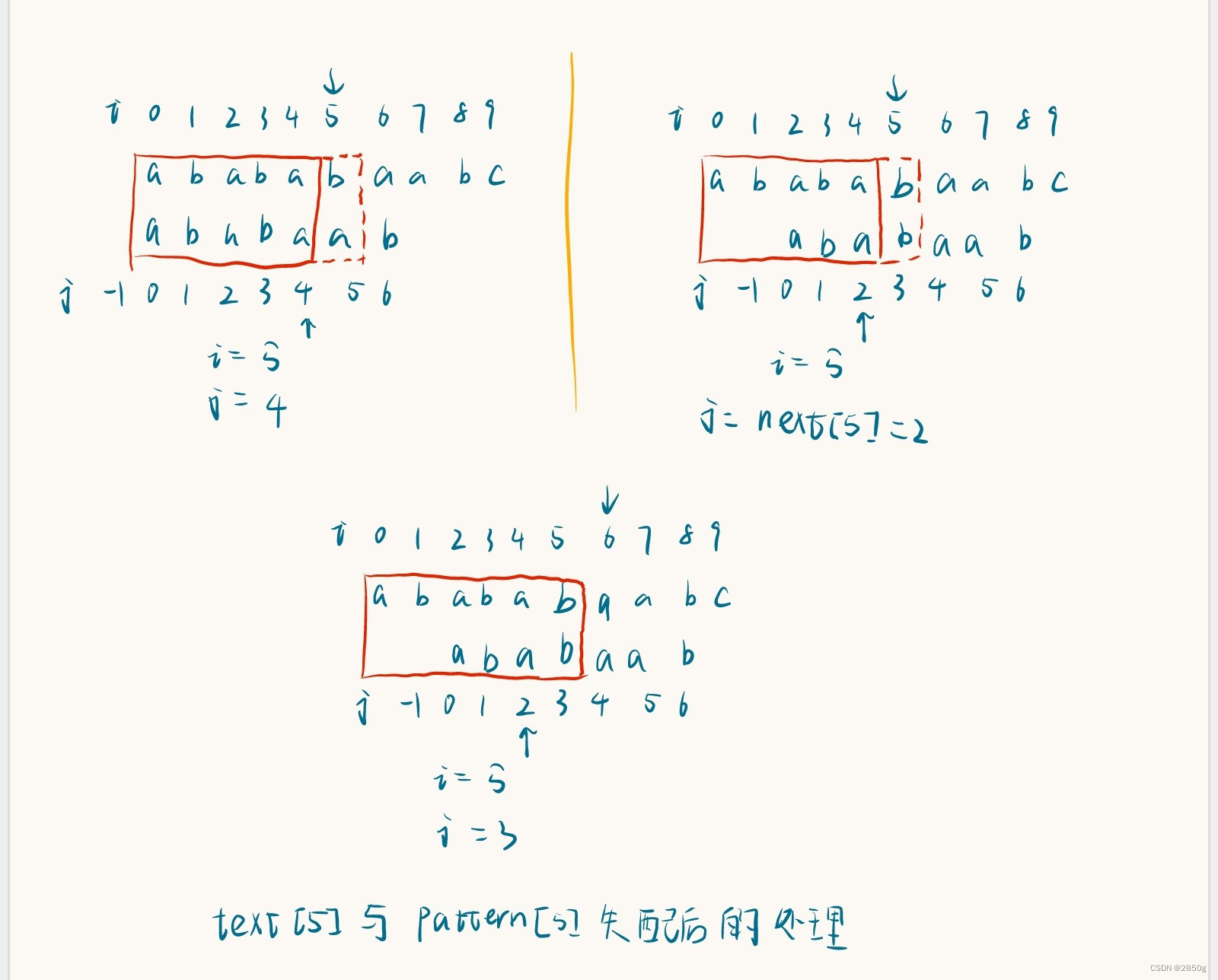
以 text = “abababaabc”、pattern = “ababaab” 为例。令 i 指向 text 的当前欲比较位,令 j 指向 pattern 中当前已被匹配的最后位,这样只要 text[i] == pattern[j + 1] 成立,就说明 pattern[j + 1] 也被成功匹配,此时让 i、j 加 1 继续比较,直到 j 达到 m - 1(m 为 pattern 长度) 时说明 pattern 是 text 的子串。在这个例子中,i 指向 text[4]、j 指向 pattern[3],表明 pattern[0…3] 已经全部匹配成功了,此时发现 text[i] == pattern[j + 1] 成立,这说明 pattern[4] 成功匹配,于是令 i、j 加 1。
接着继续匹配,此时 i 指向 text[5]、j 指向 pattern[4],表明 pattern[0…4] 已经全部匹配成功。于是试着判断 text[i] == pattern[j + 1] 是否成立:如果成立,那么就有 pattern[0…5] 被成功匹配,可以令 i、j 加 1 以继续匹配下一位。但此处 text[5] != pattern[4 + 1],匹配失败。那么我们这里该怎么做?放弃之前 pattern[0…4] 的成功匹配成果,让 j 回退到 -1 开始重新匹配吗?那是暴力解的方法,我们来看一下 kmp 的处理。
为了不让 j 直接回退到 -1,应寻求回退到一个离当前的 j 最近的 j’,使得 text[i] == pattern[j’ + 1] 能够成立,并且 pattern[0…j’] 仍然与 text 的相应位置处于匹配状态,即 pattern[0…j’] 是 pattern[0…j] 的后缀。这很容易令人想到之前的求 text 数组时碰到的类似问题。答案是 pattern[0…j’] 是 pattern[0…j] 的最长相等前后缀。也就是说,只需要不断令 j = next[j],直到 j 回退到 -1 或者是 text[i] == pattern[j + 1] 成立,然后继续匹配即可。**next 数组的含义就是当 j + 1 位失配时,j 应该回退到的位置。**对于刚刚的例子,当 text[5] 与 pattern[5] 失配时,令 j = next[4] = 2,然后我们会发现 text[i] == pattern[j + 1] 能够成立,因此就让它继续匹配,直到 j == 6 也匹配成功,这就意味着 pattern 是 text 的子串。
kmp 算法的一般思路如下:- 初始化 j = -1,表示 pattern 当前已被匹配的最后位。
- 让 i 遍历文本串 text,对每个 i,执行 3、4来试图匹配 text[i] 和 pattern[j + 1]。
- 直到 j 回退到 -1 或者是 text[i] == pattern[j + 1],否则不断令 j = next[j]。
- 如果 text[i] == pattern[j + 1],则令 j++。如果 j 达到 pattern_len - 1,说明 pattern 是 text 的子串。
// 省略求 next 数组的步骤 int j = -1; // 表示当前还没有任意一位被匹配 for (int i = 0; i < text_len; i ++) { while (j != -1 && text[i] != pattern[j + 1]) { j = next[j]; // text[i] 与 pattern[j + 1] 匹配成功,令 j + 1 } if (text[i] == pattern[j + 1]) { j ++; } if (j == pattern_len - 1) // 是子串,按题目要求处理 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们观察上面的分析,能否发现:求解 next 数组的过程其实就是模式串 pattern 进行自我匹配的过程。
考虑如何统计 pattern 在 text 中出现的起始下标:
当 j = m - 1 时表示 pattern 完全匹配,此时可以输出 i - j (text 的结束位置减去 pattern 的长度就是 pattern 在 text 中出现的下标)。但问题在于:之后应该从 pattern 的哪个位置开始进行下一次匹配? 由于 pattern 在 text 的多次出现可能是重叠的,因此不能什么都不做就让 i 加 1继续进行比较,而是必须先让 j 回退一段距离。此时 next[j] 代表着整个 pattern 的最长相等前后缀,从这个位置开始让 j 最大,即让已经匹配的部分最长,这样能保证既不漏解,又使下一次匹配省去许多无意义的比较。why O ( n + m ) O(n+m) O(n+m)?
我们看到 for 循环中每一个 i 都有一个 while 循环,这样 j 回退的次数可能不可预计,为什么 KMP 的时间复杂度为 O ( n + m ) O(n+m) O(n+m) 呢?
首先,在 kmp 整个 for 循环中 i 是不断加 1 的,所以在整个过程中 i 的变化次数是 O ( m ) O(m) O(m) 级别,接下来考虑 j 的变化,我们注意到 j 只会在一行中增加,并且每次只加 1,这样在整个过程中 j 最多增加;而其它情况 j 都是不断减小的,由于 j 最小不会小于 -1,因此在整个过程中,j 最多只能减少 n 次。也就是说 while 循环对整个过程来说最多只会执行 m 次,因此 j 在整个过程中变化次数是 O(m) 级别的。由于 i 和 j 在整个过程中的变化次数都是 O(m),因此 for 循环部分的整体复杂度就是 O(m)。考虑到计算 next 数组需要 O(n) 的时间复杂度(分析方法与上同),因此 kmp 算法总共需要 O(n + m) 的时间复杂度。
代码(C++)
#includeusing namespace std; const int N = 1000010; char p[N], s[N]; // 用 p 来匹配 s // “next” 数组,若第 i 位存储值为 k // 说明 p[0...i] 内最长相等前后缀的前缀的最后一位下标为 k // 即 p[0...k] == p[i-k...i] int ne[N]; int n, m; // n 是模板串长度 m 是模式串长度 int main() { cin >> n >> p >> m >> s; // p[0...0] 的区间内一定没有相等前后缀 ne[0] = -1; // 构造模板串的 next 数组 for (int i = 1, j = -1; i < n; i ++) { while (j != -1 && p[i] != p[j + 1]) { // 若前后缀匹配不成功 // 反复令 j 回退,直至到 -1 或是 s[i] == s[j + 1] j = ne[j]; } if (p[i] == p[j + 1]) { j ++; // 匹配成功时,最长相等前后缀变长,最长相等前后缀最后一位变大 } ne[i] = j; // 令 ne[i] = j,以方便计算 next[i + 1] } // kmp start ! for (int i = 0, j = -1; i < m; i ++) { while (j != -1 && s[i] != p[j + 1]) { j = ne[j]; } if (s[i] == p[j + 1]) { j ++; // 匹配成功时,模板串指向下一位 } if (j == n - 1) // 模板串匹配完成,第一个匹配字符下标为 0,故到 m - 1 { // 匹配成功时,文本串结束位置减去模式串长度即为起始位置 cout << i - j << ' '; // 模板串在模式串中出现的位置可能是重叠的 // 需要让 j 回退到一定位置,再让 i 加 1 继续进行比较 // 回退到 ne[j] 可以保证 j 最大,即已经成功匹配的部分最长 j = ne[j]; } } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
-
相关阅读:
贪心算法:寻找最优方案,分配问题、区间覆盖问题、最大子列和问题等
Docker创建算法环境
基于51单片机水位监测控制报警仿真设计( proteus仿真+程序+设计报告+讲解视频)
Spring Boot 实现跨域的五种方式,总有一种适合你
Maven系列第8篇:大型Maven项目,快速按需任意构建
Docker 部署
事务的隔离级别
三维大场景管理-3Dtiles规范
金九银十秋招总结
学生HTML个人网页作业作品 使用HTML+CSS+JavaScript个人介绍博客网站 web前端课程设计 web前端课程设计代码 web课程设计
- 原文地址:https://blog.csdn.net/qq_52127701/article/details/126057058
