-
kafka基本原理以及快速实战
一,kafka
传统定义:一个分布式的基于发布订阅模式的消息队列,主要应用于大数据实时处理领域
发布订阅:消息的发布者不会直接将消息发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
最新定义:开源的分布式事件流平台,被用于高性能数据管道,流分析,数据集成和关键人物应用1.1,kafka的应用场景
缓冲/消峰:类似于rabbitMq的流量削峰,对数据进行限流操作
解耦:允许独立的扩展或修改两边的处理过程,只要确保他们遵守同样的接口约束
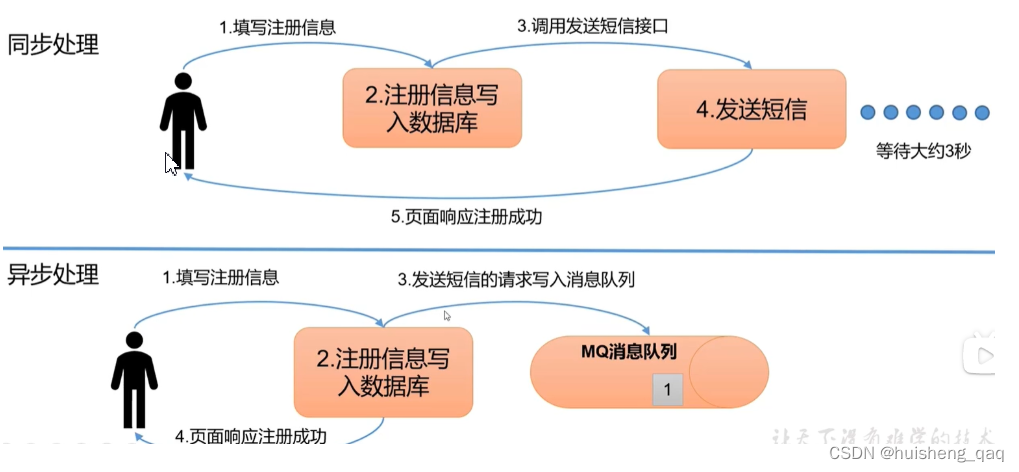
异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候处理它
1.2,消息队列的两种模式
1,点对点模式
生产者会向队列中发送消息,消费者会主动的去拉取消息,并且会有一个确认消费的信号,在确认收到这个消息之后,会将队列中存在的这条消息给删除掉。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZJGLdASQ-1658945369363)(C:\Users\HULOUBO\AppData\Roaming\Typora\typora-user-images\1657041406897.png)]](https://1000bd.com/contentImg/2022/07/31/164410960.png)
2,发布订阅模式
可以存在多个主题,如浏览,点赞,评论,收藏等。每个消费者在消费数据之后,不会将队列中的数据删掉,每个消费者都是相互独立的,都可以消费到数据。

1.3,kafka基础架构
会对整体架构进行分区分块。会对生产者这边进行分区,也会对消费者这边进行分组和分区。并且增加了这个副本,防止这个生产者出现宕机的问题,Zookeeper会记录谁是leader和follow,当然在2.8之后,也可以不采用这个zookeeper。

1.4,kafka的安装
下载地址:https://kafka.apache.org/downloads,版本最好选择2.4.x版本
1,上传到服务器里面,并对这个kafka进行解压tar -zxvf kafka-2.4.1-src.tgz- 1
2,对这个kafka进行名称的修改
mv kafka-2.4.1-src/ kafka- 1
3,进入这个bin目录下面,可以看到他一些启动脚本

kafka-server-start.sh: kafka集群的启动脚本 kafka-server-stop.sh: kafka集群的关闭脚本 kafka-console-consumer.sh: kafka生产者脚本 kafka-console-producer.sh: kafka消费者脚本 kafka-topics.sh: kafka的topic主题脚本- 1
- 2
- 3
- 4
- 5
4,在进入这个主目录下面的config配置文件

接下来配置这个kafka的server.properties集群配置环境,对里面的配置做出修改#每个集群的brokerid都要不一样,要成为每个集群的唯一标识 broker.id=0 #0表示可接任何ip listeners=PLAINTEXT://0.0.0.0:9092 advertised.host.name=175.178.75.153 advertised.port=9092 #这个可以解决一个zookeeper访问失败的bug,可选 advertised.listeners=PLAINTEXT://175.178.75.153:9092 #修改这个日志文件的存储地址,这里只需要放在安装目录下面的datas文件下,datas需要创建 log.dirs=/opt/software/kafka/kafka-logs #设置这个连接参数,如果集群的话逗号分开,多写几个zk连接地址 zookeeper.connect=175.178.75.153:2181- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5,配置kafka的环境变量
进入到目录 ,里面新建一个my_evn.sh脚本
cd /etc/profile.d vim my_evn.sh- 1
- 2
编写环境变量
export KAFKA_HOME=/opt/software/kafka export PATH=$PATH:$KAFKA_HOME/bin- 1
- 2
退出后,在source一下
source /etc/profile- 1
6,主机和ip映射
hostname查看主机名

切换到/etc/hosts,增加这个对应的映射关系vim /etc/hosts #增加下面两个映射关系,前面是服务器外网ip,后面是主机名 175.178.75.153 zhs 175.178.75.153 localhost- 1
- 2
- 3
- 4

7,启动命令1,启动zookeeper
#进入zookeeper的安装目录的bin目录下面 ./zkCli.sh- 1
- 2
2,启动kafka
#在kafka的安装目录下面,启动一下命令 # -daemon :后台的方式启动 bin/kafka-server-start.sh -daemon config/server.properties # 也可以再开一个窗口,直接启动 bin/kafka-server-start.sh config/server.properties- 1
- 2
- 3
- 4
- 5
jps命令查看进程是否启动成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uygSjOcq-1658945369374)(C:\Users\HULOUBO\AppData\Roaming\Typora\typora-user-images\1658751416048.png)]](https://1000bd.com/contentImg/2022/07/31/164412290.png)
也可以使用ps -aux | grep server.properties,查看这个kafka是否开启成功,这个配置文件是否被启用同时zookeeper服务端那边也增加了很多东西,这里记得说一下就是zookeeper和kafka的端口一定要在服务器那边开一下。

zookeeper那边也可以看到这个/brokers/ids里面也有这个id为0的结点

8,创建主题创建一个名字为zhs的topic主题,
bin/kafka‐topics.sh ‐‐create ‐‐zookeeper 175.178.75.153:2181 ‐‐replication‐factor 1 ‐‐partitions 1 ‐‐topic zhs-topic #‐‐zookeeper 192.168.65.60:2181: 连接这个zookeeper #‐‐replication‐factor 1: 设置分区副本 #‐‐partitions 1:设置分区数- 1
- 2
- 3
- 4
查看创建的主题
bin/kafka‐topics.sh ‐‐list ‐‐zookeeper 175.178.75.153:2181- 1
查看指定主题的信息
bin/kafka‐topics.sh ‐‐describe ‐‐zookeeper 175.178.75.153:2181 ‐‐topic zhs-topic- 1
删除指定的主题
bin/kafka‐topics.sh ‐‐delete ‐‐topic zhs-topic‐‐zookeeper 175.178.75.153:2181- 1
其他相关参数如下
--bootstrap-server : 连接kafka broker主机名称和端口号 --alter : 修改主题 --describe : 查看主题信息详细描述- 1
- 2
- 3
可以在zookeeper中查看被创建的主题
ls /brokers/topics- 1

1.5,kafka基本概念

Broker:相当于消息的中间件,处理消息的结点,并且这个Broker也可以做集群。
Producer:生产者,消息的生产者,向Broker发送消息的客户端
consumer:消费者,消息的消费者,从Broker中读取消息 的客户端
Topic:根据topic对消息进行一个归类,发布到kafka集群的每个消息都要指定一个topic
Partition:物理的概念,就是用于分区,一个topic可以分很多个partition,并且内部消息时有序的
consumerGroup:每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,一个Consumer Group中只有一个Consumer可以去消费消息。1.6,主题Topic和消息日志Log
1.6.1,topic基本信息

Partition是一个有序的message序列,这些message按顺序添加到一个叫做commit log的文件中。每个partition中的 消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
每个partition,都对应一个commit log文件。一个partition中的message的offset都是唯一的,但是不同的partition 中的message的offset可能是相同的。
kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多 久被删除,默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,因此保存大量的数据消息日 志信息不会有什么影响。1.6.2,查看topic的基本情况

第一行是所有分区的概要信息,之后的每一行表示每一个partition的信息。
leader节点负责给定partition的所有读写请求。
replicas 表示某个partition在哪几个broker上存在备份
isr 是replicas的一个子集,它只列出当前还存活着的1.6.3,Topic,Partition和Broker的关系
Broker就是相当于一个消息中间件。消息中间件里面有一个topic的逻辑的概念,就是相当于有多种集合的信息,比如说有订单信息,用户信息等,每一种信息就是一种partition分片。这样将一整个Broker拆分成多个Broker,即将一台机器上面的数据拆分成多台机器,这样就可以实现不同的partition可以位于不同的机器上面,每台机器都运行着kafka的进程Broker。
Topic下数据进行分区存储的原因
commit log文件会受到所在机器文件系统大小的限制,分区之后可以将不同的分区分布在不同的机器上面,相当于一个分布式的存储。二,kafka集群实战
2.1,增加两个broker结点
在config目录里面,复制两分配置文件
cp config/server.properties config/server‐1.properties cp config/server.properties config/server‐2.properties- 1
- 2
修改两个配置文件中的brokerid和log-dir
#唯一标识 broker.id=1 log.dir=/opt/software/kafka/kafka-logs-1 broker.id=2 log.dir=/opt/software/kafka/kafka-logs-2- 1
- 2
- 3
- 4
- 5
- 6
启动这两个broker
bin/kafka‐server‐start.sh ‐daemon config/server‐1.properties bin/kafka‐server‐start.sh ‐daemon config/server‐2.properties- 1
- 2
然后在zookeeper中通过 ls /brokers/id 查看id的个数

最后可以启动jps命令,可以看到有三个kafka进程。
创建一个新的topic,副本数设置为3,分区数设置为2bin/kafka‐topics.sh ‐‐create ‐‐zookeeper 175.178.75.153:2181 ‐‐replication‐factor 3 ‐‐partitions 2 ‐‐topic zhs‐topic01- 1
查看topic的情况
bin/kafka‐topics.sh ‐‐describe ‐‐zookeeper 192.168.65.60:2181 ‐‐topic zhs‐topic01- 1

leader节点负责给定partition的所有读写请求,同一个主题不同分区leader副本一般不一样(为了容灾)
replicas 表示某个partition在哪几个broker上存在备份。不管这个几点是不是”leader“,甚至这个节点挂了,也会列出。
isr 是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点2.2,kafka顺序消费问题
一个partition同一个时刻在一个consumer group中只能有一个consumer instance在消费,从而保证消费顺序。
consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多,否则,多出来的consumer消费不到消息。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。如果有在总体上保证消费顺序的需求,那么我们可以通过将topic的partition数量设置为1,将consumer group中的 consumer instance数量也设置为1,但是这样会影响性能,所以kafka的顺序消费很少用。
三,代码实现
3.1,java代码实现
1,需要的依赖
<dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.4.1</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.1.41</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> <version>1.1.3</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.1.1</version> </dependency> </dependencies>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2,编写一个Order 实体类
public class Order { private Integer orderId; private Integer productId; private Integer productNum; private Double orderAmount; public Order() { } public Order(Integer orderId, Integer productId, Integer productNum, Double orderAmount) { super(); this.orderId = orderId; this.productId = productId; this.productNum = productNum; this.orderAmount = orderAmount; } public Integer getOrderId() { return orderId; } public void setOrderId(Integer orderId) { this.orderId = orderId; } public Integer getProductId() { return productId; } public void setProductId(Integer productId) { this.productId = productId; } public Integer getProductNum() { return productNum; } public void setProductNum(Integer productNum) { this.productNum = productNum; } public Double getOrderAmount() { return orderAmount; } public void setOrderAmount(Double orderAmount) { this.orderAmount = orderAmount; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
3,kafka生产者MsgProducer 实体类
注释的比较全,可以看注释,可以知道具体的实现public class MsgProducer { //topic分区,可以命令行创建,如果不先创建,后台会自动创建 private final static String TOPIC_NAME = "zhs-topic"; public static void main(String[] args) throws InterruptedException, ExecutionException { //配置文件 Properties props = new Properties(); //BOOTSTRAP_SERVERS_CONFIG:集群环境 也可以是选择zookeeper props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "175.178.75.153:9092"); //props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "175.178.75.153:9092,175.178.75.153:9093,175.178.75.153:9094"); /* 发出消息持久化机制参数 (1)acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。 (2)acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一 条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。 (3)acks=-1或all: 需要等待 min.insync.replicas(默认为1,推荐配置大于等于2) 这个参数配置的副本个数都成功写入日志,这种策略 会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。 */ props.put(ProducerConfig.ACKS_CONFIG, "1"); /* 发送失败会重试,默认重试间隔100ms,重试能保证消息发送的可靠性,但是也可能造成消息重复发送,比如网络抖动,所以需要在 接收者那边做好消息接收的幂等性处理 */ props.put(ProducerConfig.RETRIES_CONFIG, 3); //重试间隔设置 props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300); //设置发送消息的本地缓冲区,如果设置了该缓冲区,消息会先发送到本地缓冲区,可以提高消息发送性能,默认值是33554432,即32MB props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); /* kafka本地线程会从缓冲区取数据,批量发送到broker, 设置批量发送消息的大小,默认值是16384,即16kb,就是说一个batch满了16kb就发送出去 */ props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); /* 默认值是0,意思就是消息必须立即被发送,但这样会影响性能 一般设置10毫秒左右,就是说这个消息发送完后会进入本地的一个batch,如果10毫秒内,这个batch满了16kb就会随batch一起被发送出去 如果10毫秒内,batch没满,那么也必须把消息发送出去,不能让消息的发送延迟时间太长 */ props.put(ProducerConfig.LINGER_MS_CONFIG, 10); //把发送的key从字符串序列化为字节数组 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //把发送消息value从字符串序列化为字节数组 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); Producer<String, String> producer = new KafkaProducer<String, String>(props); int msgNum = 5; final CountDownLatch countDownLatch = new CountDownLatch(msgNum); for (int i = 1; i <= msgNum; i++) { Order order = new Order(i, 100 + i, 1, 1000.00); //指定发送分区 /*ProducerRecord- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
4,kafka消费端编写
public class MsgConsumer { private final static String TOPIC_NAME = "zhs-topic"; private final static String CONSUMER_GROUP_NAME = "testGroup"; public static void main(String[] args) throws Exception { Properties props = new Properties(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "175.178.75.153:9092") // 消费分组名 props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME); // 是否自动提交offset,默认就是true /*props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); // 自动提交offset的间隔时间 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");*/ props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); /* 当消费主题的是一个新的消费组,或者指定offset的消费方式,offset不存在,那么应该如何消费 latest(默认) :只消费自己启动之后发送到主题的消息 earliest:第一次从头开始消费,以后按照消费offset记录继续消费,这个需要区别于consumer.seekToBeginning(每次都从头开始消费) */ //props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); /* consumer给broker发送心跳的间隔时间,broker接收到心跳如果此时有rebalance发生会通过心跳响应将 rebalance方案下发给consumer,这个时间可以稍微短一点 */ props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000); /* 服务端broker多久感知不到一个consumer心跳就认为他故障了,会将其踢出消费组, 对应的Partition也会被重新分配给其他consumer,默认是10秒 */ props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000); //一次poll最大拉取消息的条数,如果消费者处理速度很快,可以设置大点,如果处理速度一般,可以设置小点 props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50); /* 如果两次poll操作间隔超过了这个时间,broker就会认为这个consumer处理能力太弱, 会将其踢出消费组,将分区分配给别的consumer消费 */ props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList(TOPIC_NAME)); // 消费指定分区 //consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0))); //消息回溯消费 /*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0))); consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));*/ //指定offset消费 /*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0))); consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);*/ //从指定时间点开始消费 /*ListtopicPartitions = consumer.partitionsFor(TOPIC_NAME); //从1小时前开始消费 long fetchDataTime = new Date().getTime() - 1000 * 60 * 60; Map while (true) { /* * poll() API 是拉取消息的长轮询 */ ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n", record.partition(), record.offset(), record.key(), record.value()); } if (records.count() > 0) { // 手动同步提交offset,当前线程会阻塞直到offset提交成功 // 一般使用同步提交,因为提交之后一般也没有什么逻辑代码了 //consumer.commitSync(); // 手动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后面的程序逻辑 /*consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
3.2查看分区的业务逻辑
#如果指定分区,就用指定的分区 #如果没有指定分区,那就partition方法实现 private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) { Integer partition = record.partition(); return partition != null ? partition : this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果没有指定分区,则通过一个hash算法进行取模运算来确定哪个分区
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { if (keyBytes == null) { return this.stickyPartitionCache.partition(topic, cluster); } else { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); //hash运算取模 return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
相关阅读:
亚马逊、速卖通自养号测评技术:快速提升店铺产品转化率的权重和销量
共轭梯度法(CG)详解
2022了你还不会『低代码』?数据科学也能玩转Low-Code啦! ⛵
配置Webpack Dev Server 实战操作方法步骤
算法 旋转数组最小数字-(二分查找+反向双指针)
Intel汇编-CALL调用
【云原生 | Kubernetes 系列】K8s 实战 如何给应用注入数据
PyTorch项目源码学习(3)——Module类初步学习
nginx降权及匹配php
Python: 每日一题之第几个幸运数字
- 原文地址:https://blog.csdn.net/zhenghuishengq/article/details/126026401
