-
单机高并发模型设计
背景
在微服务架构下,我们习惯使用多机器、分布式存储、缓存去支持一个高并发的请求模型,而忽略了单机高并发模型是如何工作的。这篇文章通过解构客户端与服务端的建立连接和数据传输过程,阐述下如何进行单机高并发模型设计。
经典C10K问题
如何在一台物理机上同时服务10K用户,及10000个用户,对于java程序员来说,这不是什么难事,使用netty就能构建出支持并发超过10000的服务端程序。那么netty是如何实现的?首先我们忘掉netty,从头开始分析。 每个用户一个连接,对于服务端就是两件事
-
管理这10000个连接
-
处理10000个连接的数据传输
TCP连接与数据传输
连接建立
我们以常见TCP连接为例。
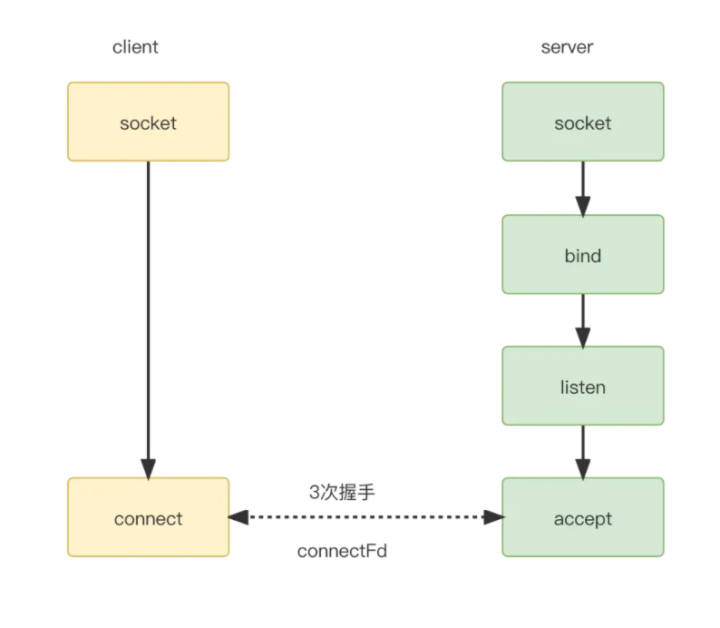
一张很熟悉的图。这篇重点在服务端分析,所以先忽略客户端细节。 服务器端通过创建socket,bind端口,listen准备好了。最后通过accept和客户端建立连接。得到一个connectFd,即连接套接字(在Linux都是文件描述符),用来唯一标识一个连接。之后数据传输都基于这个。 数据传输
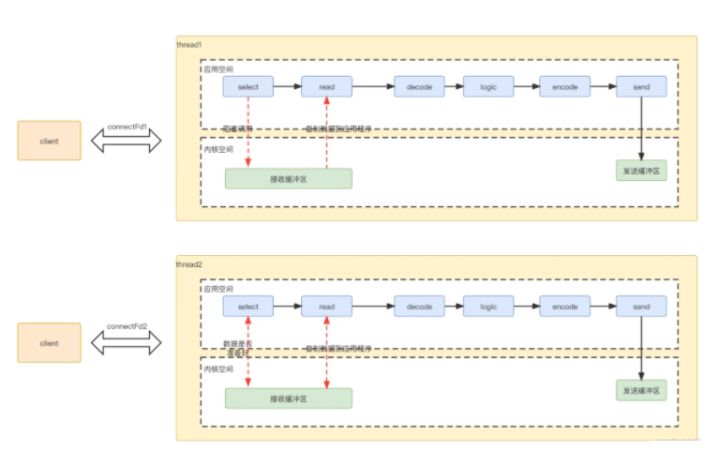
为了进行数据传输,服务端开辟一个线程处理数据。具体过程如下
-
select应用程序向系统内核空间,询问数据是否准备好(因为有窗口大小限制,不是有数据,就可以读),数据未准备好,应用程序一直阻塞,等待应答。
-
read内核判断数据准备好了,将数据从内核拷贝到应用程序,完成后,成功返回。
-
应用程序进行decode,业务逻辑处理,最后encode,再发送出去,返回给客户端
【文章福利】另外小编还整理了一些C++后台开发教学视频,相关面试题,后台学习路线图免费分享,需要的可以自行添加:Q群:720209036 点击加入~ 群文件共享
小编强力推荐C++后台开发免费学习地址:C/C++Linux服务器开发高级架构师/C++后台开发架构师
 https://ke.qq.com/course/417774?flowToken=1013189
https://ke.qq.com/course/417774?flowToken=1013189
因为是一个线程处理一个连接数据,对应的线程模型是这样
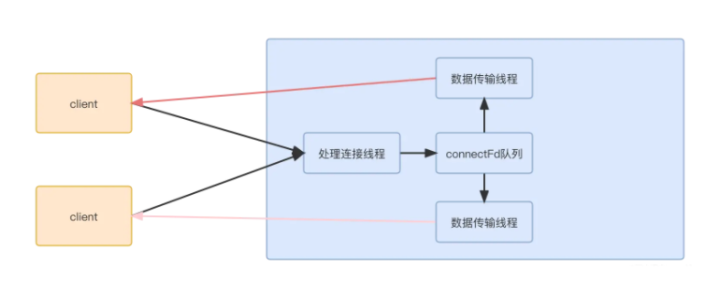
多路复用
阻塞vs非阻塞
因为一个连接传输,一个线程,需要的线程数太多,占用的资源比较多。同时连接结束,资源销毁。又得重新创建连接。所以一个自然而然的想法是复用线程。即多个连接使用同一个线程。这样就引发一个问题, 原本我们进行数据传输的入口处,,假设线程正在处理某个连接的数据,但是数据又一直没有好时,因为select是阻塞的,这样即使其他连接有数据可读,也读不到。所以不能是阻塞的,否则多个连接没法共用一个线程。所以必须是非阻塞的。
轮询 VS 事件通知
改成非阻塞后,应用程序就需要不断轮询内核空间,判断某个连接是否ready.
- for (connectfd fd: connectFds) {
- if (fd.ready) {
- process();
- }
- }
轮询这种方式效率比较低,非常耗CPU,所以一种常见的做法就是被调用方发事件通知告知调用方,而不是调用方一直轮询。这就是IO多路复用,一路指的就是标准输入和连接套接字。通过提前注册一批套接字到某个分组中,当这个分组中有任意一个IO事件时,就去通知阻塞对象准备好了。
select/poll/epoll
IO多路复用技术实现常见有select,poll。select与poll区别不大,主要就是poll没有最大文件描述符的限制。
从轮询变成事件通知,使用多路复用IO优化后,虽然应用程序不用一直轮询内核空间了。但是收到内核空间的事件通知后,应用程序并不知道是哪个对应的连接的事件,还得遍历一下
- onEvent() {
- // 监听到事件
- for (connectfd fd: registerConnectFds) {
- if (fd.ready) {
- process();
- }
- }
- }
可预见的,随着连接数增加,耗时在正比增加。相比较与poll返回的是事件个数,epoll返回是有事件发生的connectFd数组,这样就避免了应用程序的轮询。
- onEvent() {
- // 监听到事件
- for (connectfd fd: readyConnectFds) {
- process();
- }
- }
当然epoll的高性能不止是这个,还有边缘触发(edge-triggered),就不在本篇阐述了。
非阻塞IO+多路复用整理流程如下:
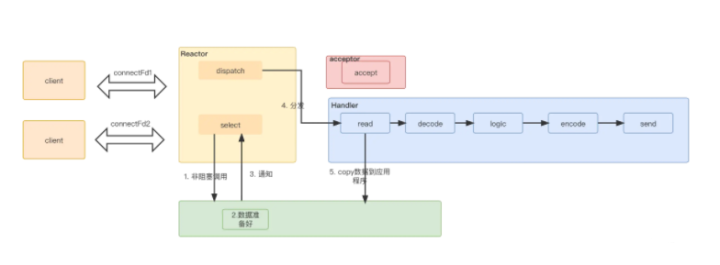
-
select应用程序向系统内核空间,询问数据是否准备好(因为有窗口大小限制,不是有数据,就可以读),直接返回,非阻塞调用。
-
内核空间中有数据准备好了,发送ready read给应用程序
-
应用程序读取数据,进行decode,业务逻辑处理,最后encode,再发送出去,返回给客户端
线程池分工
上面我们主要是通过非阻塞+多路复用IO来解决局部的select 和read问题。我们再重新梳理下整体流程,看下整个数据处理过程可以如何进行分组。这个每个阶段使用不同的线程池来处理,提高效率。 首先事件分两种
-
连接事件accept动作来处理
-
传输事件 select,read,send 动作来处理。
连接事件处理流程比较固定,无额外逻辑,不需要进一步拆分。传输事件 read,send是相对比较固定的,每个连接的处理逻辑相似,可以放在一个线程池处理。而具体逻辑decode,logic,encode 各个连接处理逻辑不同。整体可以放在一个线程池处理。
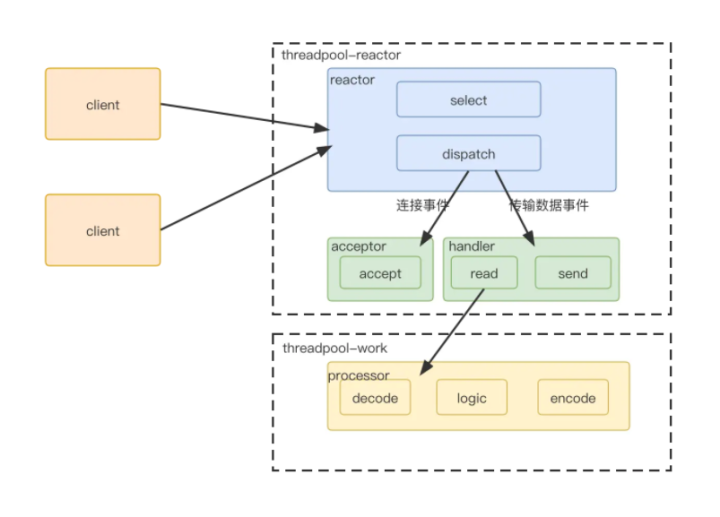
服务端拆分成3部分
-
reactor部分,统一处理事件,然后根据类型分发
-
连接事件分发给acceptor,数据传输事件分发给handler
-
如果是数据传输类型,handler read完再交给processorc处理
因为1,2处理都比较快,放在线程池处理,业务逻辑放在另外一个线程池处理。 以上就是大名鼎鼎的reactor高并发模型。
参考资料

推荐一个零声教育C/C++后台开发的免费公开课程,个人觉得老师讲得不错,分享给大家:C/C++后台开发高级架构师,内容包括Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习
-
-
相关阅读:
latex安装与使用
B/S端界面控件DevExtreme v22.1新版亮点 - HTML/Markdown编辑器升级
【总结】各层的校验和的特点
ASP.NET Core - 自定义中间件
DC电源模块的开发周期
不同类型的变量与零究竟是如何比较
前端的请求分析(get,post,put,delete,patch)
算法训练 第六周
14.7 Socket 循环结构体传输
Python的一些Pythnoic【我自己没读完,待看待再次整理】
- 原文地址:https://blog.csdn.net/Linuxhus/article/details/126013970