-
网络安全(5)
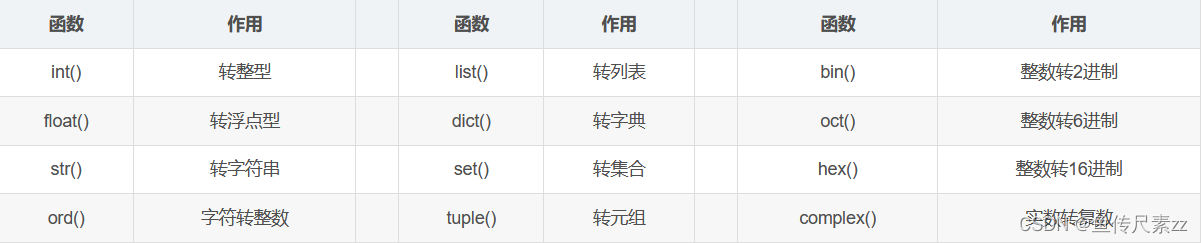
Python中的类型转换
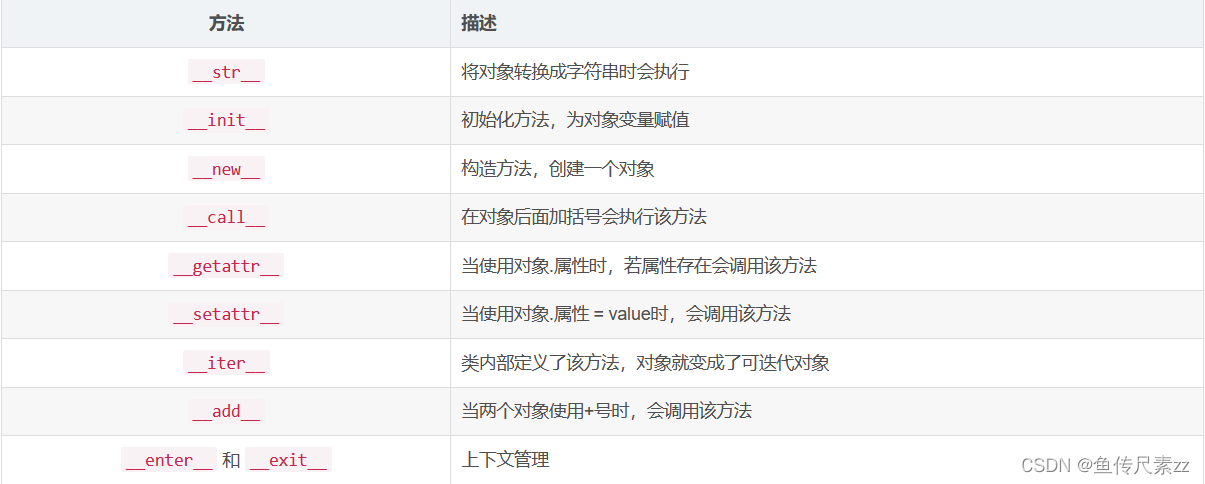
new 和 __init__的区别
__new__是一个静态方法,而__init__是一个实例方法
__new__方法会返回一个创建的实例,而__init__什么都不返回
只有在__new__返回一个cls的实例时,后面的__init__才能被调用
创建一个新实例时调用__new__方法,初始化一个实例时调用__init__方法迭代器和生成器
迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身。对于string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调用iter()函数,iter()是python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个StopIteration异常。
生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数据的时候使用yield语句,生成器使用yield语句返回一个值,yield语句挂起该生成器函数的状态,保留足够的信息,以便之后从它离开的地方继续执行。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)。生成器需要注意:只能遍历一次。
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了__iter__()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出StopIteration异常。
GIL全局解释器锁
要理解GIL的含义,我们需要从Python的基础讲起。像C++这样的语言是编译型语言,所谓编译型语言,是指程序输入到编译器,编译器再根据语言的语法进行解析,然后翻译成语言独立的中间表示,最终链接成具有高度优化的机器码的可执行程序。编译器之所以可以深层次的对代码进行优化,是因为它可以看到整个程序(或者一大块独立的部分)。这使得它可以对不同的语言指令之间的交互进行推理,从而给出更有效的优化手段。
与此相反,Python是解释型语言。程序被输入到解释器来运行。解释器在程序执行之前对其并不了解;它所知道的只是Python的规则,以及在执行过程中怎样去动态的应用这些规则。它也有一些优化,但是这基本上只是另一个级别的优化。由于解释器没法很好的对程序进行推导,Python的大部分优化其实是解释器自身的优化。更快的解释器自然意味着程序的运行也能“免费”的更快。也就是说,解释器优化后,Python程序不用做修改就可以享受优化后的好处。
要想利用多核系统,Python必须支持多线程运行。作为解释型语言,Python的解释器必须做到既安全又高效,但多线程编程会遇到问题,解释器要留意的是避免在不同的线程操作内部共享的数据,同时它还要保证在管理用户线程时保证总是有最大化的计算资源。这时,为了不同线程同时访问时保护数据,当一个线程运行python程序的时候会霸占整个python解释器,也就是给解释器加了一把全局锁,这使得对于任何python程序,不管有多少处理器,多少线程,任何时候都自由一个线程在执行,其他线程在等待正在运行的线程完成才能运行。
如果线程运行过程中遇到耗时操作,超时时间超过一个固定值,则单线线程将会解开全局解释器锁,使其他线程运行。所以在多线程中是有先后顺序的,并不是同时运行的。多进程因每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程同时运行,缺点就是系统资源开销大。
返回函数
高阶函数出了可以接受函数作为参数外,还可以把函数作为结果值返回。
嵌套函数,内层函数返回值是函数对象
def lazy_sum(*args): def sum(): x = 0 for i in args: x += i return x return sum res = lazy_sum(1, 3, 5, 7, 9) # 这里调用的是求和函数,而非求和结果 print(res) print(res()) # 结果 '''.sum at 0x000001A4B6E55488> 25 ''' - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
匿名函数
python中使用关键字lambda来创建匿名函数,没有函数名字;
lambda只是一个表达式,函数体比def简单很多;
lambda的主体是一个表达式,而不是一个代码块,所以在表达式中只能封装有限的简单的逻辑表达式,复杂的需要函数来实现;
lambda函数拥有自己的命名空间,且不能范围自有列表之外或者全局命名空间里的参数;
**注意:**虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,内联函数的目的是调用小函数时不占用栈内存从而增加运行效率。
lambda函数语法:lambda [arg1 [,arg2,…,argn]]: expression
lambda是python关键字,[arg…]和expression由用户自定义
[arg…]是参数列表,形参可以为多个,逗号隔开
expression是个参数表达式,且表达式只能是单行的,只能有一个表达式,且逻辑结束后直接返回数据
返回值在冒号之后设置,返回值和正常的函数一样,可以是任意数据类型。(但是想要返回多个元素要以容器的形式返回)# 将lambda函数赋值给一个变量,通过这个变量间接调用该lambda函数 add = lambda x, y: x + y res = add(1, 2) print(res) # 结果 ''' 3 ''' # 将lambda函数赋值给其他函数,从而将其他函数用该lambda函数替换 import time time.sleep = lambda x: None t = time.sleep(3) print(t) # 结果 ''' None ''' # 列表推导式 s = [lambda : i for i in range(5)] print(s) # 结果 ''' [0, 1, 2, 3, 4] ''' # 嵌套的lambda表达式 f = (lambda x: (lambda y: x + y)) res = f(10) print(res(5)) # 结果 ''' 15 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
随机函数
random.random()用于生成一个0到1的随机浮点数: 0 <= n < 1.0 。
random.uniform(a, b),用于生成一个指定范围内的随机浮点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成的随机数n: a <= n <= b。如果 a < b, 则 b <= n <= a 。
random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b。
random.randrange([start], stop[, step]),从指定范围内,按指定基数递增的集合中获取一个随机数。如random.randrange(10, 10, 2),结果相当于从[10, 12, 14, 16, …, 96, 98]序列中获取一个随机数。
random.choice(sequence)从序列中获取一个随机元素,参数sequence表示一个有序类型,list、tuple、字符串等。如random.choice([“Python”, “C++”, “java”]),随机在列表中选取一个元素。
random.shuffle(x[, random]),用于将一个列表中的元素打乱。如random.shuffle([“Python”, “C++”, “java”]),每次结果是随机排序的。
random.sample(sequence, k),从指定序列中随机获取指定长度的片断,sample函数不会修改原有序列。如random.sample([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 2),结果是从列表10个数字中随机选两个元素。
Python中单下划线和双下划线
单下划线开头
一种约定,一般来说,_object被看作“私有的”,在模块或类外不可以使用,不能用from module import *导入,当变量是私有的时候,用_object来表示变量是很好的习惯。双下划线开头
双下划线开头,__object表示私有成员,只有类对象自己能访问,连子类对象也不能访问到这个数据。双下划线开头和结尾
"object"指的是python中的一些特殊方法,前后双下划线是专用标识,它们是python的魔法函数,编程是不要用这种方式命名自己的变量和函数。
编码与解码
基本概念:
比特 / bit:计算机中最小的数据单位,是单个的二进制数值 0 或 1
字节 / byte:计算机存储数据的单元,1 个字节由 8 个比特组成
字符:人类能够识别的符号
编码:将人类可识别的字符转换为机器可识别的字节码 / 字节序列
解码:将机器可识别的字节码 / 字节序列转换为人类可识别的字符
编码格式;
Python2 的默认编码是ASCII,不能识别中文字符,需要显示指定字符编码。
Python3 的默认编码是Unicode,可以识别中文。
计算机内存的数据,统一使用Unicode编码;数据传输或保存在硬盘上,是哟还能UTF-8编码。
编码和解码
编码(encode):将Unicode字符串转换为特定编码格式对应的字节码的过程。s = "学习python" print(s.encode()) # encode()函数里参数默认为utf-8 print(s.encode('gbk')) # 结果 ''' b'\xe5\xad\xa6\xe4\xb9\xa0python' b'\xd1\xa7\xcf\xb0python' '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
解码(decode):将特定编码格式的字节码转换为对应的Unicode字符串的过程。
# encode和decode的编码格式必须一致,如gbk编码,必须用gbk解码 s1 = b'\xe5\xad\xa6\xe4\xb9\xa0python' s2 = b'\xd1\xa7\xcf\xb0python' print(s1.decode()) # 用默认的utf-8解码 print(s2.decode('gbk')) # 用gbk解码 # 结果 ''' 学习python 学习python '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
编码表和适用性

增量赋值
+=操作首先会尝试调用对象的__iadd__方法,如果没有该方法,那么尝试调用__add__方法,所以 += 与 +的区别实质是__iadd__和__add__的区别。
__add__方法接收两个参数,返回它们的和,两个参数的值均不会改变。
__iadd__方法同样接收两个参数,但它是属于in-place操作,即会改变第一个参数的值,所以__iadd__方法的对象只能是可变对象,如list对象提供了__iadd__方法,而int对象是没有。*=操作首先会尝试调用对象的__imul__方法,如果没有该方法,那么尝试调用__mul__方法,所以 *= 与 *的区别实质是__imul__和__mul__的区别。
对不可变序列进行重复拼接操作,效率会很低,因为每次都要新建一个序列,然后把原序列中的元素复制到新的序列里面,然后再追加新的元素。 不要把可变对象放在元组里。 增量赋值不是一个原子操作,出现异常时,仍然进行了操作。- 1
- 2
- 3
- 4
- 5
exec对字符串执行和eval对字符串求值
exec
exec函数主要用于动态地执行代码字符串,exec 返回值永远为 None。exec()不仅可以执行python代码,还可以共享上下文,但需要注意尽量不要在全局作用域下用exec()函数执行python代码,以免发生命名空间冲突。
为了解决这个问题,可以在执行之前创建一个空字典scope = {},作为exec()函数的第二个参数,这样通过exec执行python代码时创建的变量就会存储在字典scope中。
如果exec()函数执行的python代码中含有参数,且要传参,则可以在exec()中 以字典形式进行传参,这时exec就有了第三个参数args。当说要执行的代码是多行时,可以用"“” “”"引起来.
args = {'x': 1, 'y': 2} scope = {} print(exec('print(x + y)', scope, args)) print(scope.keys()) # 结果 ''' 3 dict_keys(['__builtins__']) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
eval
eval()函数来执行一个字符串表达式,实现一个可以计算表达式的计算器,并返回表达式的值。
eval()函数的语法:eval(expression[, globals[, locals]]),expression是表达式;globals是变量作用域,全局命名空间,如果被提供,这必须是一个字典对象;locals是变量作用域,局部变量命名空间,如果被提供,可以是任何映射对象。
python中查找变量的顺序是:局部 --> 全局 --> 内置
a = 1 # 当前变量 b = 2 # 当前变量 c = 3 # 当前变量 globals = {'a': 10, 'b': 20} # 全局变量 locals = {'b': 200, 'c': 300} # 局部变量 print(eval('a + b + c')) # 后两个参数省略,默认在当前作用域下,即a+b+c = 1+2+3 = 6 print(eval('a + b + c', globals, locals)) # 指定globals、locals参数,优先局部,再全局,最后当前作用域,即a+b+c = 10+200+300 = 510 # 结果 ''' 6 510 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
协程与生成器
从句法上看,协程与生成器类似,都是定义体中包含 yield 关键字的函数。可是,在协 程中,yield 通常出现在表达式的右边(例如,datum = yield),可以产出值,也可 以不产出——如果 yield 关键字后面没有表达式,那么生成器产出 None。协程可能会从 调用方接收数据,不过调用方把数据提供给协程使用的是 .send(datum) 方法,而不是 next(…) 函数。通常,调用方会把值推送给协程,通过.send()双向交换数据的生成器就是协程。
yield 关键字甚至还可以不接收或传出数据。不管数据如何流动,yield 都是一种流程控 制工具,使用它可以实现协作式多任务:协程可以把控制器让步给中心调度程序,从而激活其他的协程。
# 产生两个值的协程 >>> from inspect import getgeneratorstate >>> def simple_coro2(a): ... print('-> Started: a =', a) ... b = yield a ... print('-> Received: b =', b) ... c = yield a + b ... print('-> Received: c =', c) >>> my_coro2 = simple_coro2(14) >>> getgeneratorstate(my_coro2) # (1) 'GEN_CREATED' >>> next(my_coro2) # (2) -> Started: a = 14 14 >>> getgeneratorstate(my_coro2) # (3) 'GEN_SUSPENDED' >>> my_coro2.send(28) # (4) -> Received: b = 28 42 >>> my_coro2.send(99) # (5) -> Received: c = 99 Traceback (most recent call last): File "", line 1, in StopIteration >>> getgeneratorstate(my_coro2) # (6) 'GEN_CLOSED' - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
(1) inspect.getgeneratorstate函数指明,处于GEN_CREATED 状态(即协程未启动)。
(2) 向前执行协程到以第一个yield表达式,打印 -> Started: a = 14 消息,然后产出a的值,并且暂停,等待为b赋值。
(3) getgeneratorstate 函数指明,处于 GEN_SUSPENDED 状态(即协程在yield表达式处暂停)。
(4) 把数字28发给暂停的协程;就算yield表达式,得到28,然后把那个数按定给b。打印 -> Received: b = 28 消息,产出 a + b 的值(42),然后协程暂停,等待为 c 赋值。
(5) 把数字 99 发给暂停的协程;计算 yield 表达式,得到 99,然后把那个数绑定给 c。打印 -> Received: c = 99 消息,然后协程终止,导致生成器对象抛出StopIteration异常。
(6) getgeneratorstate 函数指明,处于 GEN_CLOSED 状态(即协程执行结束)。
-
相关阅读:
金仓数据库KingbaseES客户端编程开发框架-Hibernate(4. Hibernate编程指南)
【American English】美式发音,英语发音,美国音音标列表及发音
PreparedStatement
js高级知识点
线性预测和自回归建模
StringBuffer解析
web自动化测试
十月3倍销量于特斯拉的比亚迪,新增量在何处?
【批处理DOS-CMD命令-汇总和小结】-cmd的内部命令和外部命令怎么区分,CMD命令和运行(win+r)命令的区别,
明势资本黄明明:创新与世界,下一代基础软件的中国突围之路
- 原文地址:https://blog.csdn.net/weixin_52776876/article/details/125992504
