-
DBSCAN点云聚类
1、DBSCAN算法原理
DBSCAN是一种基于密度的聚类方法,其将点分为核心点与非核心点,后续采用类似区域增长方式进行处理。下图为DBSCAN聚类结果,可见其可以对任意类别的数据进行聚类,无需定义类别数量。
DBSCAN聚类说明
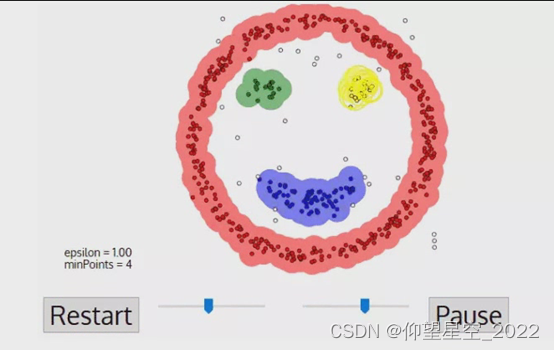
DBSCAN聚类过程如下:
1、首先,DBSCAN算法会以任何尚未访问过的任意起始数据点为核心点,并对该核心点进行扩充。这时我们给定一个半径/距离ε,任何和核心点的距离小于ε的点都是它的相邻点。
2、如果核心点附近有足够数量的点,则开始聚类,且选中的核心点会成为该聚类的第一个点。如果附近的点不够,那算法会把它标记为噪声(之后这个噪声可能会成为簇中的一部分)。在这两种情形下,选中的点都会被标记为“已访问”。
3、一旦聚类开始,核心点的相邻点,或者说以该点出发的所有密度相连的数据点(注意是密度相连)会被划分进同一聚类。然后我们再把这些新点作为核心点,向周围拓展ε,并把符合条件的点继续纳入这个聚类中。
4、重复步骤2和3,直到附近没有可以扩充的数据点为止,即簇的ε邻域内所有点都已被标记为“已访问”。
5、一旦我们完成了这个集群,算法又会开始检索未访问过的点,并发现更多的聚类和噪声。一旦数据检索完毕,每个点都被标记为属于一个聚类或是噪声。
与其他聚类算法相比,DBSCAN有一些很大的优势。首先,它不需要输入要划分的聚类个数。其次,即使数据点非常不同,它也会将它们纳入聚类中,DBSCAN能将异常值识别为噪声,这就意味着它可以在需要时输入过滤噪声的参数。第三,它对聚类的形状没有偏倚,可以找到任意大小和形状的簇。
DBSCAN的主要缺点是,当聚类的密度不同时,DBSCAN的性能会不如其他算法。这是因为当密度变化时,用于识别邻近点的距离阈值ε和核心点的设置会随着聚类发生变化。而这在高维数据中会特别明显,因为届时我们会很难估计ε。

从已有的聚类效果上来看,将一些点定义成噪声点,没有进行聚类。因此也可以理解成这样:先对点进行去噪处理,再使用距离聚类(如欧氏聚类)实现点的聚类。
对三维点云数据的聚类结果如下:2、源码下载
基于C++编写的源代码下载地址:
https://download.csdn.net/download/qq_32867925/86246799
只需要将三个头文件加载到工程中即可

DBSCAN核心代码:
DBSCANKdtreeCluster<pcl::PointXYZ> ec; ec.setCorePointMinPts(10); // test 4. uncomment the following line to test the EuclideanClusterExtraction // pcl::EuclideanClusterExtraction- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2、聚类效果


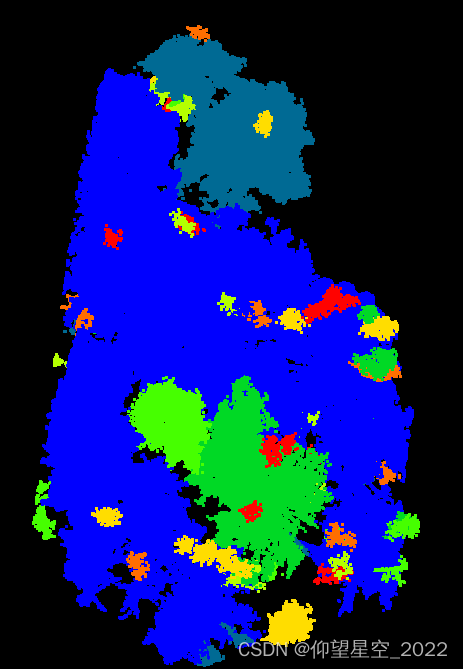
从另一个角度可见,DBSCAN是距离聚类的另一种形式,其相比较于常规距离聚类而言,多了核心点判别过程。 -
相关阅读:
【Hello,PyQt】最简单的一些pyqt5程序
20uec++多人游戏【小球与玩家互动】
消除两个inline-block元素之间的间隔
树莓派使用docker搭建owncloud私有云--外挂硬盘
MySQL索引详解及演进过程以及延申出面试题(别再死记硬背了,跟着我推演一遍吧)
vueRouter个人笔记
mysql如何创建添加索引?
Elasticsearch的配置学习笔记
echarts案例之仪表盘如何单独设置指针颜色?
JavaScript-HelloWorld、浏览器控制台使用、数据类型
- 原文地址:https://blog.csdn.net/qq_32867925/article/details/125899276
