-
http2流分片data数据合并-linux xxd方法
首先如果http2的stream分片了,但是能够decode识别为http2 protocol,这种情况是最理想的情况:
- 通过follow http2 stream得到http2的stream,这样就不用在tcp stream中去寻找目标http2 stream了,这样也能比较快得到http2 stream。用上篇文章(http2分片流内容整合呈现方法)的方法是可以的。
- 当然这种情况也可以使用这篇文章介绍的方法
使用tcp follow方式比较直观,但是如果http2 stream所在的tcp流包较多的话,follow需要的时间可能较长,这篇文章介绍借用Linux xxd命令合并tcp或者http2 data部分内容
1. 过滤目标http2 stream
- 如果tcp分片可以识别http2 stream
filter syntax:
tcp.stream == XX&&http2.streamid==XX- 如果tcp分片已不能识别成是http2 protocol,需要想办法过滤出http2 stream的所有相应分片
filter syntax:
(ipv6.src == 2409:804b:5003:1105::d:101) && (tcp.stream == 53)&&(frame.number>=13853 && frame.number <=13888 )
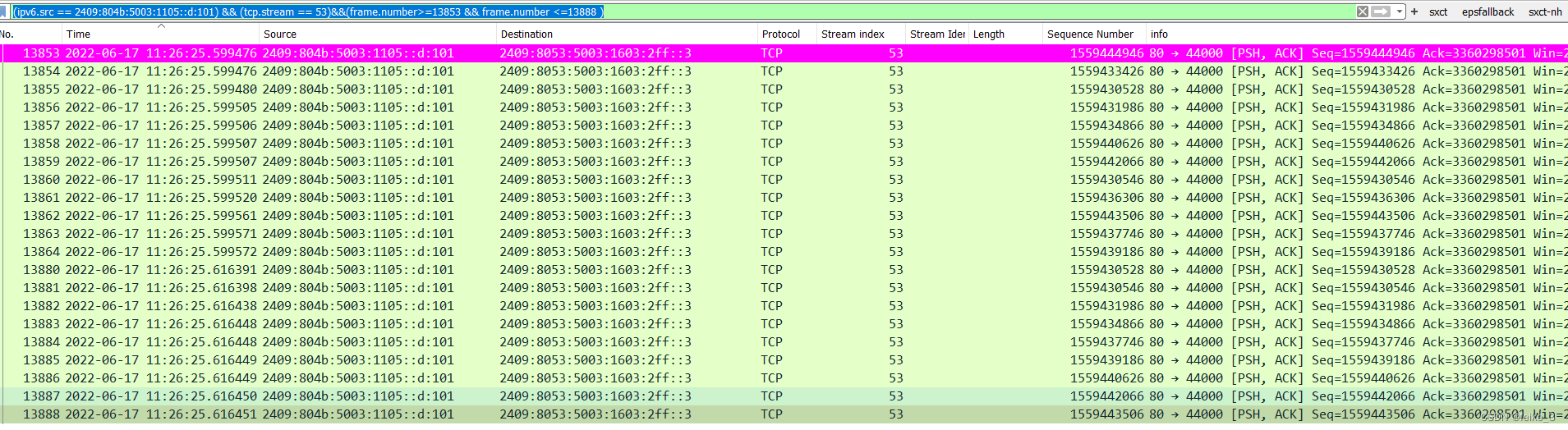
2. 过滤目出的目标包处理
两个原因可能需要再次进行处理:
- 包的顺序是乱的,不处理的话,xxd显示的结果也是乱的
- 抓包原因可能抓了重复的包,或者真的出现了重传。
如我上面的截图每个序列号都重复了,这可能是抓包原因。
包处理:
tshark -r “HN_AMF08_0617_0320-udm-ipv6-unreachable.pcap” -o tcp.reassemble_out_of_order:false -o tcp.analyze_sequence_numbers:false -Y “(ipv6.src == 2409:804b:5003:1105::d:101) && (tcp.stream == 53)&&(frame.number>=13853 && frame.number <=13888 )” -T fields -e tcp.seq -e tcp.payload | sort | uniq | more
tshark: The file “HN_AMF08_0617_0320-udm-ipv6-unreachable.pcap” appears to have been cut short in the middle of a packet.
1559430528 00000901040000e03d88be0f0d840b6cb8f7
1559430546 00200000000000e03d7b2276616c6964697479506572696f64223a333630302c226e66496e7374616e636573223a5b7b226e66496e7374616e63654964223a226165666
4373834312d336430392d346132332d623638632d303431303030303030303032222c226e6654797065223a2241555346222c226e66537461747573223a2252454749535445524544222c22
68656172744265617454696d6572223a31302c22706c6d6e4c697374223a5b7b226d6363223a2234**说明:** 1. -r "HN_AMF08_0617_0320-udm-ipv6-unreachable.pcap" 读取pcap抓包 2. -o tcp.reassemble_out_of_order:false -o tcp.analyze_sequence_numbers:false 关闭tcp乱序和序列号分析 3. (ipv6.src == 2409:804b:5003:1105::d:101) && (tcp.stream == 53)&&(frame.number>=13853 && frame.number <=13888 ) 过滤的目标http2 stream 4. -T fields -e tcp.seq -e tcp.payload 显示2个字段,tcp.seq排序用,tcp.payload目标字段。 5. sort | uniq linux指令,排序然后去重- 1
- 2
- 3
- 4
- 5
- 6
3.tcp payload目标字段合并
tshark -r “HN_AMF08_0617_0320-udm-ipv6-unreachable.pcap” -o tcp.reassemble_out_of_order:false -o tcp.analyze_sequence_numbers:false -Y “(ipv6.src == 2409:804b:5003:1105::d:101) && (tcp.stream == 53)&&(frame.number>=13853 && frame.number <=13888 )” -T fields -e tcp.seq -e tcp.payload | sort | uniq | awk -F " " ‘{print $2}’ | xxd -r -p
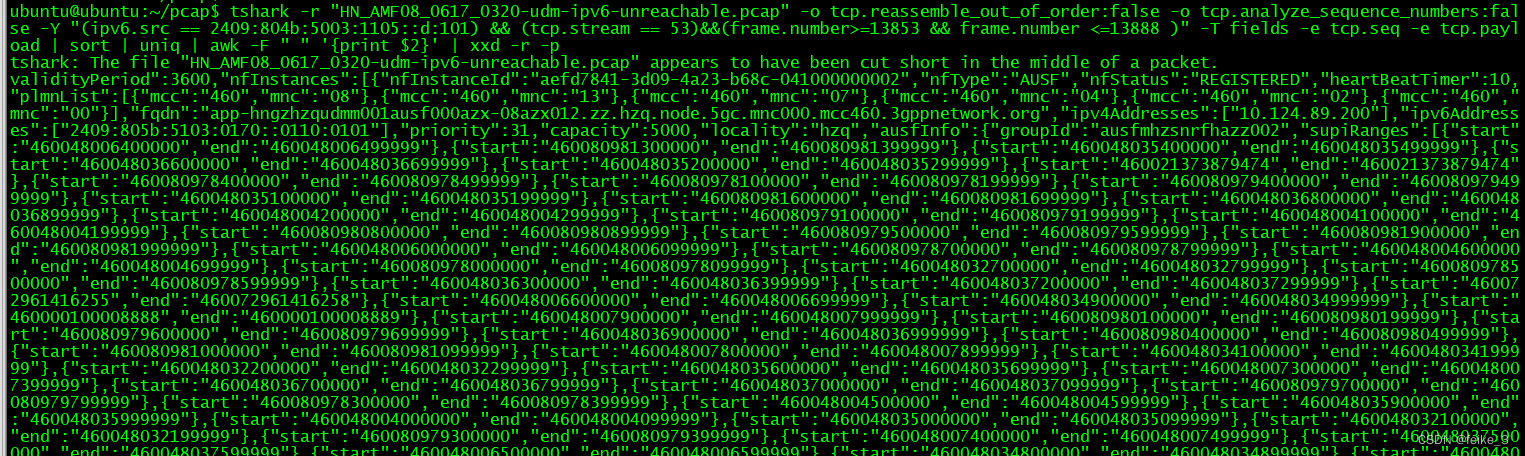
**说明:** 1. awk之前是上面的过滤条件 2. awk -F " " '{print $2}' 只保留data部分 3. 使用xxd合并解码显示data部分- 1
- 2
- 3
- 4
4. 用json工具转换格式
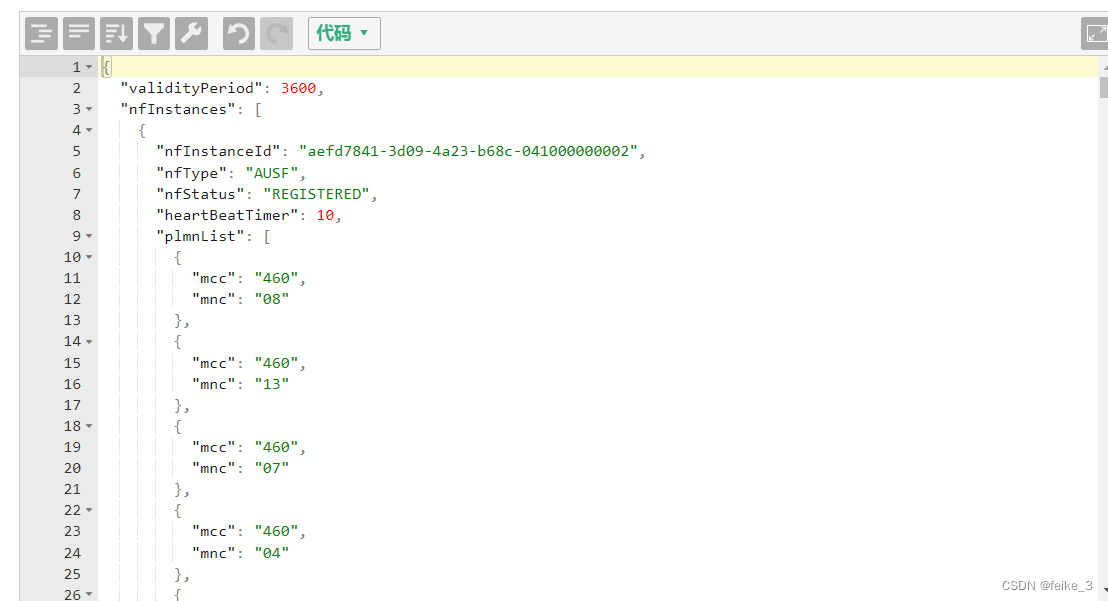
上篇文章(http2分片流内容整合呈现方法)介绍过,copy出大括号的部分,用tool工具或者notepad++ plugin。
copy出来转换前:

转换后:
-
相关阅读:
Lua数据文件
【插槽】Vue中插槽Slot基本使用和具名插槽
【LeetCode】多数元素 II [M](摩尔投票)
Qt开发之串口通信(三)
教资-10月21日
服务器白名单
常见的C语言类型转换
基于SSH开发在线问卷调查系统
面向对象之抽象类的认识 - (java语法)
三星泄露微软 Copilot 新功能:用自然语言操控各种功能
- 原文地址:https://blog.csdn.net/weixin_45617372/article/details/125603107