-
油田勘探问题
一 原题链接
Oil Deposits - UVA 572 - Virtual Judge
 https://vjudge.net/problem/UVA-572
https://vjudge.net/problem/UVA-572二 输入与输出
1 输入
输入文件包含一个或多个长方形地域。每个地域的第1行都有两个整数 m 和 n,表示地域的行数和列数。如果 m=0,则表示输入结束;否则此后有 m 行,每行都有 n 个字符。每个字符都对应一个正方形区域,字符 * 表示没有油,字符 @ 表示有油。
2 输出
对于每个长方形的地域,都单行输出油藏的个数。
3 输入样例
1 1
*
3 5
*@*@*
**@**
*@*@*
1 8
@@****@*
5 5
****@
*@@*@
*@**@
@@@*@
@@**@
0 0
4 输出样例
0
1
2
2
三 算法分析
对这样的油田进行遍历,从每个 @ 格子出发,寻找它周围所有的 @ 格子,同时将这些格子标记一个连通分量号,最后输出连通分量数。使用图的深度优先搜索即可。
例如,针对下面这个用例
5 5
****@
*@@*@
*@**@
@@@*@
@@**@
0 0
它的油藏个数就是连通分量的个数,如下图所示。

根据问题描述,水平、垂直或对角线都认为是相邻,因此搜索时,可以从8 个方向进行深度优先搜索,如下图所示。
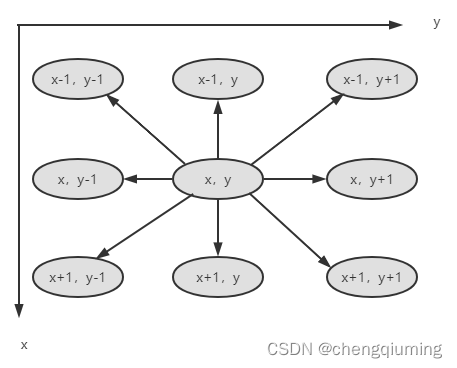
四 算法设计
1 对字符矩阵中的每个位置都进行判断,如果未标记连通分量号且为 @,则从该位置出发进行深度优先搜索。
2 搜素时需要判断是否出界,是否已有连通分量号或不是 @,否则将该位置标记连通分量为 id,从该位置出发,沿 8 个方向继续进行深度优先搜索。
3 因为有可能包含多个连通分量,因此需要从每个未标记的 @ 进行深度优先搜索。
五 代码
- package graph;
- import java.util.Scanner;
- public class UVA572 {
- static int maxn = 100 + 5;
- static String str[] = new String[maxn]; // 存储字符矩阵
- static int m; // 行
- static int n; // 列
- static int setid[][];
- /**
- * 功能描述:深度优先搜索
- *
- * @param x 行
- * @param y 列
- * @param id 连通分量号
- * @author cakin
- * @date 2022/6/26
- */
- static void dfs(int x, int y, int id) {
- // 出界
- if (x < 0 || x >= m || y < 0 || y >= n) {
- return;
- }
- // 已有连通分量号或不是'@'
- if (setid[x][y] > 0 || str[x].charAt(y) != '@') {
- return;
- }
- setid[x][y] = id;
- for (int dx = -1; dx <= 1; dx++)
- for (int dy = -1; dy <= 1; dy++) {
- if (dx != 0 || dy != 0)
- // 八个方向深搜
- dfs(x + dx, y + dy, id);
- }
- }
- public static void main(String[] args) {
- Scanner scanner = new Scanner(System.in);
- while (true) {
- m = scanner.nextInt();
- n = scanner.nextInt();
- if (m == 0 && n == 0) {
- return;
- }
- for (int i = 0; i <= m - 1; i++) {
- str[i] = scanner.next();
- }
- // 初始化连通分量
- setid = new int[maxn][maxn];
- int cnt = 0;
- for (int i = 0; i <= m - 1; i++) {
- for (int j = 0; j <= n - 1; j++) {
- if (setid[i][j] == 0 && str[i].charAt(j) == '@')
- dfs(i, j, ++cnt);
- }
- }
- System.out.println(cnt);
- }
- }
- }
六 测试

-
相关阅读:
Python条件语句的用法
区块链学姐:8月9日以太持续破新高,空头能量是否还存在?
AI 生成的唯美头像也太好看了吧!附好说 AI 一秒出图技巧
详解单例模式
【Vue 路由(route) 一】介绍、基本使用、嵌套路由
QT6不支持QDesktopWidget包含头文件报错Qt 获取设备屏幕大小
leetcode872. 叶子相似的树(java)
SpringBoot3正式版将于11月24日发布:都有哪些新特性?
Jenkins pipline集成发布到K8s
修复 Windows 上的 PyTorch 1.1 github 模型加载权限错误
- 原文地址:https://blog.csdn.net/chengqiuming/article/details/125466617