-
数据库的建立、增、删、改、查
前言:一名计算机专业的在读大学生,博客主要对自己所学习的计算机专业基础进行总结,希望在加强自身基础的同时可以帮到你们!
目录
(2)统计一列中的元素个数count([dietinct] 列名)
一、模式定义与删除
1、定义模式
数据库的组成:
1)数据类文件:管理数据
1、 主数据文件 有且唯一 .mdf
2、 辅助数据文件 可以有,可以没有,可以有多个 .ndf
2)日志类文件:备份数据 至少一个 .ldf
每一个文件有五个属性:
1 name:逻辑名称,字符型数据 name=’aaaa111’
标准化命名:数据库名字+_+data(log)+序号(类型)
2 filename:路径
标准化命名:盘符(例如d:\zs\)+逻辑名称+文件类型名
3 size:文件初始大小 size=5mb,
4 maxsize:最大大小 maxsize=20mb或maxsize=unlimited
5 filegrowth:文件增长方式filegrowth=5%或filegrowth=2mb
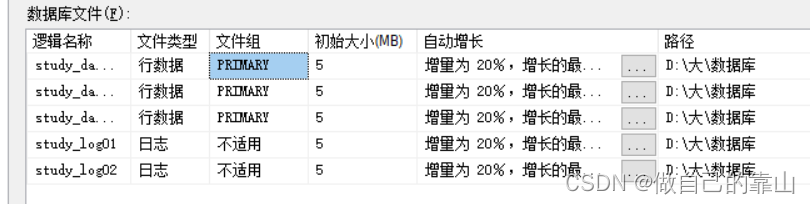
示例:建立名叫study的数据库如下
- create database study
- on
- (name='study_data01',
- filename='D:\大\数据库\study_data01.mdf',
- size=5MB,
- maxsize=20Mb,
- filegrowth=20%),
- (name='study_data02',
- filename='D:\大\数据库\study_data02.ndf',
- size=5MB,
- maxsize=20Mb,
- filegrowth=20%),
- (name='study_data03',
- filename='D:\大\数据库\study_data01.ndf',
- size=5MB,
- maxsize=20Mb,
- filegrowth=20%)
- log on
- (name='study_log01',
- filename='D:\大\数据库\study_log01.ldf',
- size=5MB,
- maxsize=20Mb,
- filegrowth=20%),
- (name='study_log02',
- filename='D:\大\数据库\study_log02.ldf',
- size=5MB,
- maxsize=20Mb,
- filegrowth=20%)

2、向数据库中添加文件或删除文件
主数据文件有且唯一,固不可添加,不可删除
- 添加数据类文件:管理数据
- alter database study
- add file
- (name='study_data04',
- filename='D:\大\数据库\study_data04.ndf',
- size=5MB,
- maxsize=20Mb,
- filegrowth=20%),
- (name='study_data05',
- filename='D:\大\数据库\study_data05.ndf',
- size=5MB,
- maxsize=20Mb,
- filegrowth=20%)
- 添加日志类文件:备份数据
- alter database study
- add log file
- (name='study_log03',
- filename='D:\大\数据库\study_log03.ldf',
- size=5MB,
- maxsize=20Mb,
- filegrowth=20%)

- 删除辅数据文件:
- alter database study
- remove file study_data05
- 删除日志文件:
- alter database study
- remove file study_log03

3、删除模式
drop schema<模式名> <cascade|restrict>其中cascade(级联)和restrict(限制)两者必选其一。
cascade 表示删除模式的同时把该模式中所有的数据库对象全部删除;选择了restrict表示如果该模式中已经定义了下属数据库对象(如表、视图),则拒绝该删除语句的执行
二、基本表的定义、删除与修改
1、定义基本表结构
- CREATE TABLE <表名>
- (<列名> <数据类型>[ <列级完整性约束条件> ]
- [,<列名> <数据类型>[ <列级完整性约束条件>] ] …
- [,<表级完整性约束条件> ] );
六大约束
- 主码约束 primary key 唯一非空
- 唯一约束 unique 可以没有,也可以有多个
- 非空约束 not null 可以省略
- 默认约束 default 加了该约束则代表非空
- 外码约束 foreign key
- 表内外码
- 同表不同属性
- 其中一个属性取值来源另一个属性
-
foreign key (Cpno) reference Course(Cno)
- 表间外码
- 不同表之间的相同属性
- 一个来源另一个
- foreign key (Sno) references Student(Sno)
- 表内外码
- 检查约束 check (域,数据取值范围)
2、数据类型
-
常用字符型
- 定长字符串 char(n) character(n)
- 变长字符串 varchar(n) charactervarying(n)
-
常用整型
- 长整数 int integer
- 短整型 smallint
- 大整型 bigint
-
浮点数
- flot(n)
-
日期、时间类
- date YYYY-MM-DD 加 ' '
- time HH:MM:SS
示例:在数据库study下建立 Student表、Course表、SC表
- create table Student
- (Sno char(9) primary key,
- Sname char(12) unique,
- Ssex char(2) default('男'),
- Sage smallint not null,
- Sdept char(14) );
- create table Course
- (Cno char(6) primary key,
- Cname char(12)unique,
- Cpno char(6),
- Ccredit smallint not null,
- foreign key(Cpno) references Course(Cno));
- create table SC
- (Sno char(9),
- Cno char(6),
- Grade smallint,
- primary key(Sno,Cno),
- foreign key (Sno) references Student(Sno),
- foreign key (Cno) references Course(Cno));

3、模式与表
概念:每一个基本表都属于某一个模式,一个模式包含多个基本表;
当用户创建基本表时若没有指定模式,系统根据搜索路径(search path)来确定该对象所属的模式。 搜索路径包含一组模式列表,关系数据库管理系统会使用模式列表中第一个存在的模式作为数据库对象的模式名。若搜索路径中的模式名不存在,系统将会给出错误。
4、修改基本表
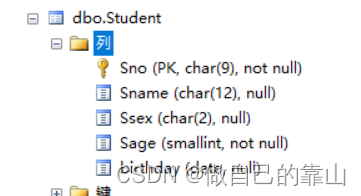
以修改数据库study下表Student为例:
(1)向表中添加元组
alter table 表名
add 列名 数据类型
- alter table Student
- add birthday date
修改前: 修改后:


注意:此时不能加非空约束
(2)删除表中的元组
alter table 表名
drop column 列名
删除Sdept
- alter table Student
- drop column Sdept
删除前: 删除后:

(3)添加约束
alter table Student
add constraint 约束名 <约束> for 元组给你年龄添加默认18岁的默认约束
- alter table Student
- add constraint Sage_1 default(18) for Sage
给年龄添加域,即检查属性
- alter table Student
- add constraint Sage_2 check(Sage>=15)
(4)修改约束
修改约束先删除约束,再重新添加约束即可
(5)删除约束
alter table Student
drop constraint <约束名>- alter table Student
- drop constraint Sage_2
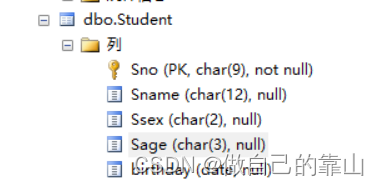
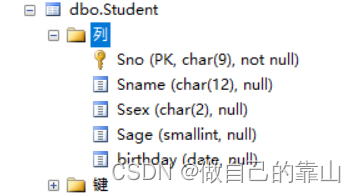
(6)修改数据类型
alter table 表名
alter column 列名 修改后的数据类型
- alter table Student
- alter column Sage smallint
修改前: 修改后:
注意:在修改类型长度时,只能改大不能改小(数据丢失)
5、删除基本表
drop table<表名>三、数据查询 select
1、单表查询
(1)、指定列 select sno,sname
- select Sno,Sname,Sage
- from Students
查询结果:

(2)、全部列
- select *
- from Students
查询结果:

(3)、计算列
- select Sname as '姓名','出生年份'=2022-Sage
- from Students
查询结果:

(4)、换名列
- select Sname as '姓名',Sage as '年龄',Ssex as '性别'
- from Students
查询结果:

(5)、指定显示多少元组
- select top 3 *
- from Students

(6)、带where 限制条件的查询
一、准确查找
eg:年龄小与21的
- select Sname as '姓名',sage as '年龄',Ssex as '性别'
- FROM Students
- WHERE Sage<21
查询结果:

(1)确定范围查找:要求有明显的上限和下限
eg:年龄在15~18之间的
- select Sno,Sage
- from Students
- where Sage between 15 and 18

(2)确定集合:没有明显的上限和下限
eg:查找地址在 金州,芝加哥,克利夫兰,工地 的
- select Sno,Sname,Faddress
- from Students
- where Faddress in ('金州','芝加哥','克利夫兰','工地')

注意:
二、 模糊查找
eg1:查询名字中带有 萌 的
- select Sname as '姓名',sage as '年龄',Ssex as '性别'
- FROM Students
- where Sname like '%萌%'

eg2:查询名字以杜开头的
- select Sname as '姓名',sage as '年龄',Ssex as '性别'
- FROM Students
- where Sname like '杜%'

eg3:查询名字中第二个字为 小 的
- select Sname as '姓名',sage as '年龄',Ssex as '性别'
- FROM Students
- where Sname like '_小_'

三,转义escape 后可接 \ # $
eg1:查询以名字以 凡_开头的
- select *
- from Student
- where Sname like '凡\_%'escape'\'
eg2:查询名字以 _ 结尾的
- select *
- from Student
- where Sname like '%\_'escape'\'
聚合函数的使用:
对原始列(属性)进行简单的数理统计
(1)count(*)查询表中元组个数
- select COUNT(*) as '学生人数'
- from Students

(2)统计一列中的元素个数count([dietinct] 列名)
- select COUNT(distinct Faddress) as '地区分布个数'
- from Students

(3)统计一列的总和 sum([dietinct] 列名)
此列必须时数值
(4)计算一列的平均值avg([dietinct] 列名)
此列必须时数值
(5)求一列的最大值max([dietinct] 列名)
(6)求一列的最小值min([dietinct] 列名)
- select sum(Sage) as '年龄总和'
- from Students
- select avg(Sage) as '平均年龄'
- from Students
- select max(Sage) as '最大年龄'
- from Students
- select min(Sage) as '最小年龄'
- from Students

order by、group by的使用:
group by 分组: 常见的按性别,所在系分组且和select语句原始列保持一致
eg:查找所有的年龄(按年龄分组)
- select sage
- from student
- group by sage
order by用来排序的:(查询结果按一个或多个属性进行升序asc,降序desc,排列输出)
order by 属性 desc 按‘属性’进行降序排列
order by 属性 asc 降序排列
order by、group by使用时机即注意事项总结:
- select后接只有属性时:
- order by后可接表中所有属性或属性组合
- group by后接属性要大于等于select后接的属性
- select后接只有聚集函数
- order by 后可接聚集函数也可接聚集别名(推荐接别名)
- group by后接表中的属性或属性组合
- select 后接的既有属性又有聚集
- order by不可单独存在必须和group by一起使用
- group by 后接属性要大于等于select后接的属性
注意:group by后不可接聚集函数
where子句和having短语
区别在于:作用对象不同
where子句作用于基本表或视图(视图下期会讲解视图学习)从中选择满足条件的元组。having短语作用于组,从中选择满足条件的组。having后自可接聚集函数
eg:选修课程超过4门的学生学号、名字、选修门数
- select Student.Sno as '学号', Sname as '姓名','选课门数'=COUNT(*)
- from Student,Course,SC
- where Course.Cno=SC.Cno and Student.Sno=SC.Sno
- group by Student.Sno,Sname
- having COUNT(*)>4
2、连接查询
连接查询:查询的结果或条件同时涉及多个表的查询
(1)谓词连接查询
from 后的表名通过 "," 连接, 表和表连接要保证两表有公共列
where 后跟连接条件
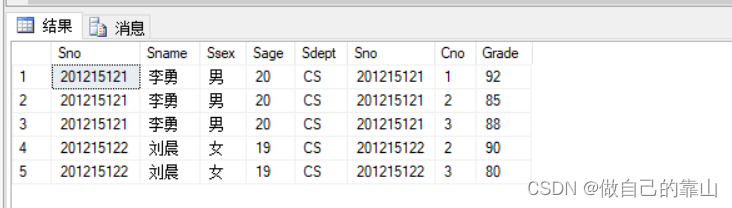
eg:查找学生的个人信息和选课信息
- select Student.*,SC.*
- from Student,SC
- where Student.Sno=SC.Sno
(2)内连接
from后表名通过 join 连接,中间表要放中间
接连接条件写在 on后面 一个on只可接一个条件
顺序要和from后中表名对应(先内后外)
格式:
select 属性
from 表名1 join 表名2 join 表名3
on 表三和表二的连接条件(公共列)
on 表一和表二的连接条件(公共列)
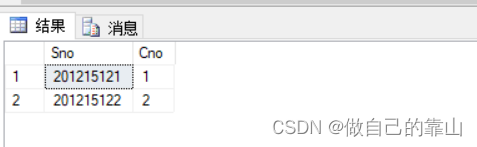
eg:查找选修课程总学分超过5的,学生学号,姓名
- select Student.Sno,Sname,'总学分'=SUM(Ccredit)
- from Student join SC join Course
- on Course.Cno=SC.Cno
- on Student.Sno=SC.Sno
- group by Student.Sno,Sname
- having SUM(Ccredit)>5
- order by '总学分' desc

(3)自身连接
同一个表中查两次,
from 后接同一表的不同别名
eg:查找和学生表中李勇一个系的学生学号、姓名
- select y.Sno,y.Sname
- from Student x,Student y
- where x.Sdept=y.Sdept
- and x.Sname='李勇'
- and y.Sname!='李勇'

(4)外连接
左外连接 (左表为主表,右表为辅表,列出左表中所有元组,右表中没有出现的左边元组会将属性值设为空出现在查询结果中如下面例子的6、7)
select 属性
from 表名1 left outer jion 表名2
on 表1和表2的连接条件
右外连接 (列出右边关系表中所有元组)
select 属性
from 表名1 left outer jion 表名2
on 表1和表2的连接条件
完全外连接 (列出两个表中所有元组,没有的属性设置为空)
select 属性
from 表名1 left outer jion 表名2
on 表1和表2的连接条件
eg:下面依次完全外连接查询、左外连接查询、右外连接查询
- select Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
- from Student full outer join SC
- on Student.Sno=SC.Sno
- select Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
- from Student left outer join SC
- on Student.Sno=SC.Sno
- select Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
- from Student right outer join SC
- on Student.Sno=SC.Sno

3、嵌套查询
概念:
一个SELECT-FROM-WHERE语句称为一个查询块
将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询
(1)带in谓词的子查询
用in 或=做查询的连接
Where 公共列 in (select 公共列
In 可以无限替代=,反之则不成立
子查询的结果有且唯一, in可以换成=,反之则不成立
eg:查询选修了数据库这门课程的的学生姓名
- select Sname
- from Student
- where Sno in
- (select Sno
- from SC
- where Cno in
- (
- select Cno
- from Course
- where Cname='数据库'
- )
- )

(2)带有运算符的子查询
eg:查询成绩大于所选课程平均成绩的学生学号和课程号
- select Sno,Cno
- from SC x
- where Grade>
- (
- select AVG(Grade)
- from SC y
- where y.Sno=x.Sno
- )
(3)带有ANY或ALL谓词的比较类子查询
any,all的选用
满足子查询块的结果中任意一个条件用any
满足所有条件则用all
(条件容易满足用any,不容易满足用all)
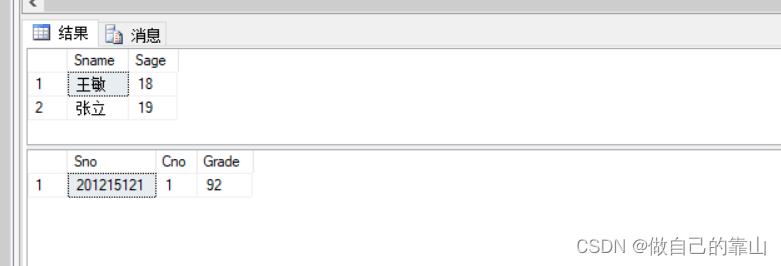
eg:1、查询年龄比cs系学生任意年龄小的非cs系得学生姓名、年纪
2、查询选修课程1中成绩比选修课程2的所有成绩都高的学生学号、课程号、成绩
- select Sname,Sage
- from Student
- where Sage<any(
- select Sage
- from Student
- where Sdept='CS'
- )
- and Sdept!='CS'
- select Sno,Cno,Grade
- from SC
- where Cno='1' and Grade>all
- (
- select Grade
- from SC
- where Cno='2'
- )
(4)带有exists 谓词的子查询
1、EXISTS谓词:行(元组)的连接存在量词
带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”。
若内层查询结果非空,则外层的WHERE子句返回真值
若内层查询结果为空,则外层的WHERE子句返回假值
由EXISTS引出的子查询,其目标列表达式通常都用* ,因为带EXISTS的子查询只返回真值或假值,给出列名无实际意义
2. NOT EXISTS谓词
若内层查询结果非空,则外层的WHERE子句返回假值
若内层查询结果为空,则外层的WHERE子句返回真值
Exists 连接:1不找公共列,2在最下层子查询块中写表之间的连接条件;3中间表要放最下层子查询块中
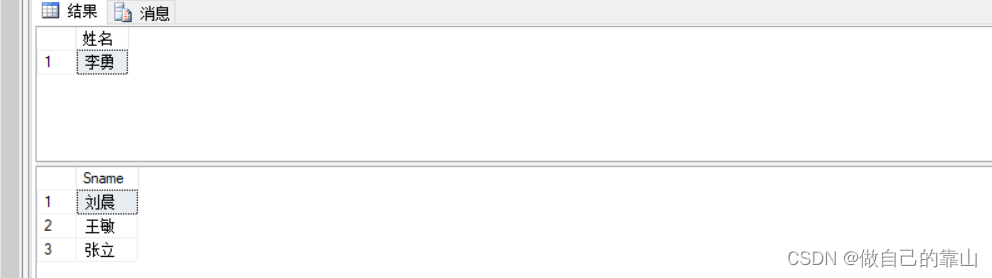
eg:1、选修了1号课程的同学学号和姓名
2、没有选修1号课程的学生学号和姓名
- select Sname as '姓名'
- from Student
- where exists(
- Select*
- from SC
- where Student.Sno=SC.Sno
- and Cno='1')
- select Sname
- from Student
- where not exists (
- select *
- from SC
- where Student.Sno=SC.Sno
- and Cno='1')
连接查询总结:几种查询方式可以相互转换,
例如:带any的子查询可以转换为最小,最大来解决
eg:小于cs系中任意年龄的学生姓名、年龄
- //带any谓词的查询
- select Sname,Sage
- from Student
- where Sage<any(
- select Sage
- from Student
- where Sdept='CS'
- )
- and Sdept!='CS'
- //转换为小于最大年龄
- select Sname,Sage
- from Student
- where Sage<(
- select max(Sage)
- from Student
- where Sdept='CS'
- )
- and Sdept!='CS'
本次学习总结就到这里了,下期一起来学习视图吧!加油追梦人!
-
相关阅读:
java基础学习-多线程笔记
基于SSM框架流浪猫救援网站的设计与实现毕业设计源码201502
Node.js 入门教程 6 V8 JavaScript 引擎
Django ORM 多表操作
排序算法-----快速排序(递归)
Python的pip换源详解
2.5 C#视觉程序开发实例1----CamManager实现模拟相机采集图片(Form_Vision部分代码)
docker-compose安装nacos
java接入烽火科技拾音器详细步骤
运动健身的一些心得经验
- 原文地址:https://blog.csdn.net/qq_43846797/article/details/124483932