[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (2)
0x00 摘要
在这篇文章中,我们介绍了 HugeCTR,这是一个面向行业的推荐系统训练框架,针对具有模型并行嵌入和数据并行密集网络的大规模 CTR 模型进行了优化。
本文以GitHub 源码文档 https://github.com/NVIDIA-Merlin/HugeCTR/blob/master/docs/python_interface.md 的翻译为基础,并且结合源码进行分析。其中借鉴了HugeCTR源码阅读 这篇大作,特此感谢。
为了更好的说明,下面类定义之中,只保留其成员变量,成员函数会等到分析时候才会给出。
本系列其他代码为:
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(1)
0x01 总体流程
1.1 概述
HugeCTR 训练的过程可以看作是数据并行+模型并行。
- 数据并行是:每张 GPU卡可以同时读取不同的数据来做训练。
- 模型并行是:Sparse 参数可以被分布式存储到不同 GPU,不同 Node 之上,每个 GPU 分配部分 Sparse 参数。
训练流程如下:
-
首先构建三级流水线,初始化模型网络。初始化参数和优化器状态。
-
Reader 会从数据集加载一个 batch 的数据,放入 Host 内存之中。
-
开始解析数据,得到 sparse 参数,dense 参数,label 等等。
-
嵌入层进行前向传播,即从参数服务器读取 embedding,进行处理。
-
对于网络层进行前向传播和后向传播,具体区分是多卡,单卡,多机,单机等。
-
嵌入层反向操作。
-
多卡之间交换 dense 参数的梯度。
-
嵌入层更新 sparse 参数。就是把反向计算得到的参数梯度推送到参数服务器,由参数服务器根据梯度更新参数。
1.2 如何调用
我们从一个例子中可以看到,总体逻辑和单机很像,就是解析配置,使用 session 来读取数据,训练等等,其中 vvgpu 是 device map。
# train.py
import sys
import hugectr
from mpi4py import MPI
def train(json_config_file):
solver_config = hugectr.solver_parser_helper(batchsize = 16384,
batchsize_eval = 16384,
vvgpu = [[0,1,2,3,4,5,6,7]],
repeat_dataset = True)
sess = hugectr.Session(solver_config, json_config_file)
sess.start_data_reading()
for i in range(10000):
sess.train()
if (i % 100 == 0):
loss = sess.get_current_loss()
if __name__ == "__main__":
json_config_file = sys.argv[1]
train(json_config_file)
0x02 Session
既然知道了 Session 是核心,我们就通过 Session 看看如何构建 HugeCTR。
2.1 Session 定义
我们首先看看Session的定义,只保留其成员变量,可以看到其主要是:
- networks_ :模型网络信息。
- embeddings_ :模型嵌入层信息。
- ExchangeWgrad :交换梯度的类。
- evaluate_data_reader_ : 读取 evalution。
- train_data_reader_ :读取训练数据到嵌入层。
- resource_manager_ :GPU 资源,比如 handle 和 Stream。
class Session {
public:
Session(const SolverParser& solver_config, const std::string& config_file);
Session(const Session&) = delete;
Session& operator=(const Session&) = delete;
private:
std::vector<std::shared_ptr<Network>> networks_; /**< networks (dense) used in training. */
std::vector<std::shared_ptr<IEmbedding>> embeddings_; /**< embedding */
std::shared_ptr<IDataReader> init_data_reader_;
std::shared_ptr<IDataReader>
train_data_reader_; /**< data reader to reading data from data set to embedding. */
std::shared_ptr<IDataReader> evaluate_data_reader_; /**< data reader for evaluation. */
std::shared_ptr<ResourceManager>
resource_manager_; /**< GPU resources include handles and streams etc.*/
std::shared_ptr<Parser> parser_;
std::shared_ptr<ExchangeWgrad> exchange_wgrad_;
metrics::Metrics metrics_;
SolverParser solver_config_;
struct HolisticCudaGraph {
std::vector<bool> initialized;
std::vector<cudaGraphExec_t> instance;
std::vector<cudaEvent_t> fork_event;
} train_graph_;
// TODO: these two variables for export_predictions.
// There may be a better place for them.
bool use_mixed_precision_;
size_t batchsize_eval_;
};
2.2 构造函数
构造函数大致分为以下步骤:
- 使用 create_pipeline 创建流水线。
- 初始化模型网络。
- 初始化参数和优化器状态。
Session::Session(const SolverParser& solver_config, const std::string& config_file)
: resource_manager_(ResourceManagerExt::create(solver_config.vvgpu, solver_config.seed,
solver_config.device_layout)),
solver_config_(solver_config) {
// 检查设备
for (auto dev : resource_manager_->get_local_gpu_device_id_list()) {
if (solver_config.use_mixed_precision) {
check_device(dev, 7,
0); // to support mixed precision training earliest supported device is CC=70
} else {
check_device(dev, 6, 0); // earliest supported device is CC=60
}
}
// 生成 Parser,用来解析配置
parser_.reset(new Parser(config_file, solver_config.batchsize, solver_config.batchsize_eval,
solver_config.num_epochs < 1, solver_config.i64_input_key,
solver_config.use_mixed_precision, solver_config.enable_tf32_compute,
solver_config.scaler, solver_config.use_algorithm_search,
solver_config.use_cuda_graph));
// 建立流水线
parser_->create_pipeline(init_data_reader_, train_data_reader_, evaluate_data_reader_,
embeddings_, networks_, resource_manager_, exchange_wgrad_);
#ifndef DATA_READING_TEST
#pragma omp parallel num_threads(networks_.size())
{
// 多线程并行初始化模型
size_t id = omp_get_thread_num();
networks_[id]->initialize();
if (solver_config.use_algorithm_search) {
networks_[id]->search_algorithm();
}
CK_CUDA_THROW_(cudaStreamSynchronize(resource_manager_->get_local_gpu(id)->get_stream()));
}
#endif
// 加载dense feature需要的参数
init_or_load_params_for_dense_(solver_config.model_file);
// 加载sparse feature需要的参数
init_or_load_params_for_sparse_(solver_config.embedding_files);
// 加载信息
load_opt_states_for_sparse_(solver_config.sparse_opt_states_files);
load_opt_states_for_dense_(solver_config.dense_opt_states_file);
int num_total_gpus = resource_manager_->get_global_gpu_count();
for (const auto& metric : solver_config.metrics_spec) {
metrics_.emplace_back(
std::move(metrics::Metric::Create(metric.first, solver_config.use_mixed_precision,
solver_config.batchsize_eval / num_total_gpus,
solver_config.max_eval_batches, resource_manager_)));
}
if (solver_config_.use_holistic_cuda_graph) {
train_graph_.initialized.resize(networks_.size(), false);
train_graph_.instance.resize(networks_.size());
for (size_t i = 0; i < resource_manager_->get_local_gpu_count(); i++) {
auto& gpu_resource = resource_manager_->get_local_gpu(i);
CudaCPUDeviceContext context(gpu_resource->get_device_id());
cudaEvent_t event;
CK_CUDA_THROW_(cudaEventCreateWithFlags(&event, cudaEventDisableTiming));
train_graph_.fork_event.push_back(event);
}
}
if (embeddings_.size() == 1) {
auto lr_scheds = embeddings_[0]->get_learning_rate_schedulers();
for (size_t i = 0; i < lr_scheds.size(); i++) {
networks_[i]->set_learning_rate_scheduler(lr_scheds[i]);
}
}
}
这里有几个相关类需要注意一下。
2.2.1 ResourceManager
我们首先看看 ResourceManager。
2.2.1.1 接口
首先是两个接口,ResourceManagerBase 是最顶层接口,ResourceManager 进行了扩展。
/**
* @brief Top-level ResourceManager interface
*
* The top level resource manager interface shared by various components
*/
class ResourceManagerBase {
public:
virtual void set_local_gpu(std::shared_ptr<GPUResource> gpu_resource, size_t local_gpu_id) = 0;
virtual const std::shared_ptr<GPUResource>& get_local_gpu(size_t local_gpu_id) const = 0;
virtual size_t get_local_gpu_count() const = 0;
virtual size_t get_global_gpu_count() const = 0;
};
/**
* @brief Second-level ResourceManager interface
*
* The second level resource manager interface shared by training and inference
*/
class ResourceManager : public ResourceManagerBase {
// 省略了函数定义
}
2.2.1.2 Core
然后是核心实现:ResourceManagerCore,这里记录了各种资源。
/**
* @brief GPU resources manager which holds the minimal, essential set of resources
*
* A core GPU Resource manager
*/
class ResourceManagerCore : public ResourceManager {
private:
int num_process_;
int process_id_;
DeviceMap device_map_;
std::shared_ptr<CPUResource> cpu_resource_;
std::vector<std::shared_ptr<GPUResource>> gpu_resources_; /**< GPU resource vector */
std::vector<std::vector<bool>> p2p_matrix_;
std::vector<std::shared_ptr<rmm::mr::device_memory_resource>> base_cuda_mr_;
std::vector<std::shared_ptr<rmm::mr::device_memory_resource>> memory_resource_;
}
2.2.1.3 拓展
ResourceManagerExt 是在 ResourceManagerCore 基础之上进行再次封装,其核心就是 core_,这是一个 ResourceManagerCore 类型。我们用 ResourceManagerExt 来分析。
/**
* @brief GPU resources manager which holds all the resources required by training
*
* An extended GPU Resource manager
*/
class ResourceManagerExt : public ResourceManager {
std::shared_ptr<ResourceManager> core_;
#ifdef ENABLE_MPI
std::unique_ptr<IbComm> ib_comm_ = NULL;
#endif
std::shared_ptr<AllReduceInPlaceComm> ar_comm_ = NULL;
};
其创建代码如下,可以看到其利用 MPI 做了一些通信上的配置:
std::shared_ptr<ResourceManager> ResourceManagerExt::create(
const std::vector<std::vector<int>>& visible_devices, unsigned long long seed,
DeviceMap::Layout layout) {
int size = 1, rank = 0;
#ifdef ENABLE_MPI
HCTR_MPI_THROW(MPI_Comm_size(MPI_COMM_WORLD, &size));
HCTR_MPI_THROW(MPI_Comm_rank(MPI_COMM_WORLD, &rank));
#endif
DeviceMap device_map(visible_devices, rank, layout);
std::random_device rd;
if (seed == 0) {
seed = rd();
}
#ifdef ENABLE_MPI
HCTR_MPI_THROW(MPI_Bcast(&seed, 1, MPI_UNSIGNED_LONG_LONG, 0, MPI_COMM_WORLD));
#endif
std::shared_ptr<ResourceManager> core(
new ResourceManagerCore(size, rank, std::move(device_map), seed));
return std::shared_ptr<ResourceManager>(new ResourceManagerExt(core));
}
ResourceManagerExt::ResourceManagerExt(std::shared_ptr<ResourceManager> core) : core_(core) {
#ifdef ENABLE_MPI
int num_process = get_num_process();
if (num_process > 1) {
int process_id = get_process_id();
ib_comm_ = std::make_unique<IbComm>();
ib_comm_->init(num_process, get_local_gpu_count(), process_id, get_local_gpu_device_id_list());
}
#endif
}
void ResourceManagerExt::set_ar_comm(AllReduceAlgo algo, bool use_mixed_precision) {
int num_process = get_num_process();
#ifdef ENABLE_MPI
ar_comm_ = AllReduceInPlaceComm::create(num_process, algo, use_mixed_precision, get_local_gpus(),
ib_comm_.get());
#else
ar_comm_ = AllReduceInPlaceComm::create(num_process, algo, use_mixed_precision, get_local_gpus());
#endif
}
具体资源上的配置还是调用了<ResourceManager> core_ 来完成。
// from ResourceManagerBase
void set_local_gpu(std::shared_ptr<GPUResource> gpu_resource, size_t local_gpu_id) override {
core_->set_local_gpu(gpu_resource, local_gpu_id);
}
const std::shared_ptr<GPUResource>& get_local_gpu(size_t local_gpu_id) const override {
return core_->get_local_gpu(local_gpu_id);
}
size_t get_local_gpu_count() const override { return core_->get_local_gpu_count(); }
size_t get_global_gpu_count() const override { return core_->get_global_gpu_count(); }
// from ResourceManager
int get_num_process() const override { return core_->get_num_process(); }
int get_process_id() const override { return core_->get_process_id(); }
0x03 Parser
前面提到了Parser,我们接下来就看看。Parser 负责解析配置文件,建立流水线。其类似的支撑文件还有 SolverParser,Solver,InferenceParser 等等。可以说,Parser 是自动化运作的关键,是支撑系统的灵魂。
3.1 定义
/**
* @brief The parser of configure file (in json format).
*
* The builder of each layer / optimizer in HugeCTR.
* Please see User Guide to learn how to write a configure file.
* @verbatim
* Some Restrictions:
* 1. Embedding should be the first element of layers.
* 2. layers should be listed from bottom to top.
* @endverbatim
*/
class Parser {
private:
nlohmann::json config_; /**< configure file. */
size_t batch_size_; /**< batch size. */
size_t batch_size_eval_; /**< batch size. */
const bool repeat_dataset_;
const bool i64_input_key_{false};
const bool use_mixed_precision_{false};
const bool enable_tf32_compute_{false};
const float scaler_{1.f};
const bool use_algorithm_search_;
const bool use_cuda_graph_;
bool grouped_all_reduce_ = false;
}
我们接下来的这些分析,其实都是调用了 Parser 或者其相关类。
3.2 如何组织网络
我们首先看看配置文件,看看其中是如何组织一个模型网络,这里以 test/scripts/deepfm_8gpu.json 为例。
这里需要说明一下 json 字段的作用:
bottom_names: 本层的输入张量名字。top_names: 本层的输出张量名字。
所以,模型就是通过 bottom 和 top 从下往上组织起来的。
3.2.1 输入
输入层如下,dense 是 slice 层的输入,Sparse 是sparse_embedding1 的输入,其中包含了 26 个 slots。
{
"name": "data",
"type": "Data",
"source": "./file_list.txt",
"eval_source": "./file_list_test.txt",
"check": "Sum",
"label": {
"top": "label",
"label_dim": 1
},
"dense": {
"top": "dense",
"dense_dim": 13
},
"sparse": [
{
"top": "data1",
"slot_num": 26,
"is_fixed_length": false,
"nnz_per_slot": 2
}
]
},
此时模型图如下:

3.2.2 嵌入层
我们看看其定义:
-
embedding_vec_size 是向量维度。
-
combiner :查找得到向量之后,如何做pooling,是做sum还是avg。
-
workspace_size_per_gpu_in_mb :每个GPU之上的内存大小。
{
"name": "sparse_embedding1",
"type": "DistributedSlotSparseEmbeddingHash",
"bottom": "data1",
"top": "sparse_embedding1",
"sparse_embedding_hparam": {
"embedding_vec_size": 11,
"combiner": "sum",
"workspace_size_per_gpu_in_mb": 10
}
},
此时模型如下:

3.2.3 其它层
这里我们把其它层也包括进来,就是目前输入数据和嵌入层的再上一层,我们省略了很多层,这里只是给大家一个大致的逻辑。
3.2.3.1 Reshape层
Reshape 层把一个 3D 输入转换为 2D 形状。此层是嵌入层的消费者。
{
"name": "reshape1",
"type": "Reshape",
"bottom": "sparse_embedding1",
"top": "reshape1",
"leading_dim": 11
},
3.2.3.2 Slice 层
Slice 层把一个bottom分解成多个top。
{
"name": "slice2",
"type": "Slice",
"bottom": "dense",
"ranges": [
[
0,
13
],
[
0,
13
]
],
"top": [
"slice21",
"slice22"
]
},
3.2.3.3 Loss
这就是我们最终的损失层,label直接会输出到这里。
{
"name": "loss",
"type": "BinaryCrossEntropyLoss",
"bottom": [
"add",
"label"
],
"top": "loss"
}
3.2.3.4 简略模型图
目前逻辑如下,是从下往上组织的模型,我们省略了其他部分:

3.3 全貌
我们对每个层进行精简,省略内部标签,把配置文件中所有层都整理出来,看看一个DeepFM在HugeCTR之中的整体架构。

0x04 建立流水线
我们接着看如何建立流水线。Create_pipeline 函数是用来构建流水线的,其就是转移给了create_pipeline_internal 方法。
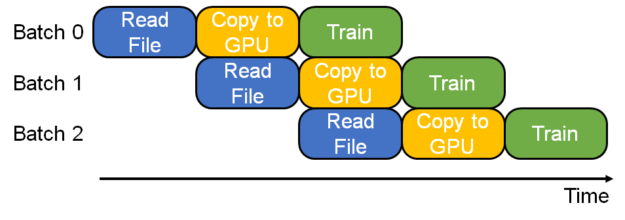
void Parser::create_pipeline(std::shared_ptr<IDataReader>& init_data_reader,
std::shared_ptr<IDataReader>& train_data_reader,
std::shared_ptr<IDataReader>& evaluate_data_reader,
std::vector<std::shared_ptr<IEmbedding>>& embeddings,
std::vector<std::shared_ptr<Network>>& networks,
const std::shared_ptr<ResourceManager>& resource_manager,
std::shared_ptr<ExchangeWgrad>& exchange_wgrad) {
if (i64_input_key_) {
create_pipeline_internal<long long>(init_data_reader, train_data_reader, evaluate_data_reader,
embeddings, networks, resource_manager, exchange_wgrad);
} else {
create_pipeline_internal<unsigned int>(init_data_reader, train_data_reader,
evaluate_data_reader, embeddings, networks,
resource_manager, exchange_wgrad);
}
}
4.3.1 create_pipeline_internal
create_pipeline_internal 主要包含了四步:
- create_allreduce_comm :建立allreduce通信相关机制。
- 建立 Data Reader。
- 建立 嵌入层相关机制。
- 建立 网络相关机制,在每张GPU卡之中构建一个network副本。
- 对梯度交换类进行分配。
template <typename TypeKey>
void Parser::create_pipeline_internal(std::shared_ptr<IDataReader>& init_data_reader,
std::shared_ptr<IDataReader>& train_data_reader,
std::shared_ptr<IDataReader>& evaluate_data_reader,
std::vector<std::shared_ptr<IEmbedding>>& embeddings,
std::vector<std::shared_ptr<Network>>& networks,
const std::shared_ptr<ResourceManager>& resource_manager,
std::shared_ptr<ExchangeWgrad>& exchange_wgrad) {
try {
// 建立allreduce通信相关
create_allreduce_comm(resource_manager, exchange_wgrad);
std::map<std::string, SparseInput<TypeKey>> sparse_input_map;
std::vector<TensorEntry> train_tensor_entries_list[resource_manager->get_local_gpu_count()];
std::vector<TensorEntry> evaluate_tensor_entries_list[resource_manager->get_local_gpu_count()];
{
if (!networks.empty()) {
CK_THROW_(Error_t::WrongInput, "vector network is not empty");
}
// 校验网络
auto j_layers_array = get_json(config_, "layers");
auto j_optimizer = get_json(config_, "optimizer");
check_graph(tensor_active_, j_layers_array);
// Create Data Reader
// 建立 Data Reader
{
// TODO: In using AsyncReader, if the overlap is disabled,
// scheduling the data reader should be off.
// THe scheduling needs to be generalized.
auto j_solver = get_json(config_, "solver");
auto enable_overlap = get_value_from_json_soft<bool>(j_solver, "enable_overlap", false);
const nlohmann::json& j = j_layers_array[0];
create_datareader<TypeKey>()(j, sparse_input_map, train_tensor_entries_list,
evaluate_tensor_entries_list, init_data_reader,
train_data_reader, evaluate_data_reader, batch_size_,
batch_size_eval_, use_mixed_precision_, repeat_dataset_,
enable_overlap, resource_manager);
} // Create Data Reader
// Create Embedding
{
for (unsigned int i = 1; i < j_layers_array.size(); i++) {
// 网路配置的每层是从底到上,因此只要遇到非嵌入层,就不检查其后的层了
// if not embedding then break
const nlohmann::json& j = j_layers_array[i];
auto embedding_name = get_value_from_json<std::string>(j, "type");
Embedding_t embedding_type;
if (!find_item_in_map(embedding_type, embedding_name, EMBEDDING_TYPE_MAP)) {
Layer_t layer_type;
if (!find_item_in_map(layer_type, embedding_name, LAYER_TYPE_MAP) &&
!find_item_in_map(layer_type, embedding_name, LAYER_TYPE_MAP_MP)) {
CK_THROW_(Error_t::WrongInput, "No such layer: " + embedding_name);
}
break;
}
// 建立嵌入层
if (use_mixed_precision_) {
create_embedding<TypeKey, __half>()(
sparse_input_map, train_tensor_entries_list, evaluate_tensor_entries_list,
embeddings, embedding_type, config_, resource_manager, batch_size_,
batch_size_eval_, exchange_wgrad, use_mixed_precision_, scaler_, j, use_cuda_graph_,
grouped_all_reduce_);
} else {
create_embedding<TypeKey, float>()(
sparse_input_map, train_tensor_entries_list, evaluate_tensor_entries_list,
embeddings, embedding_type, config_, resource_manager, batch_size_,
batch_size_eval_, exchange_wgrad, use_mixed_precision_, scaler_, j, use_cuda_graph_,
grouped_all_reduce_);
}
} // for ()
} // Create Embedding
// 建立网络层
// create network
int total_gpu_count = resource_manager->get_global_gpu_count();
if (0 != batch_size_ % total_gpu_count) {
CK_THROW_(Error_t::WrongInput, "0 != batch_size\%total_gpu_count");
}
// create network,在每张GPU卡之中构建一个network副本
for (size_t i = 0; i < resource_manager->get_local_gpu_count(); i++) {
networks.emplace_back(Network::create_network(
j_layers_array, j_optimizer, train_tensor_entries_list[i],
evaluate_tensor_entries_list[i], total_gpu_count, exchange_wgrad,
resource_manager->get_local_cpu(), resource_manager->get_local_gpu(i),
use_mixed_precision_, enable_tf32_compute_, scaler_, use_algorithm_search_,
use_cuda_graph_, false, grouped_all_reduce_));
}
}
exchange_wgrad->allocate(); // 建立梯度交换类
} catch (const std::runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
}
4.3.2 create_allreduce_comm
create_allreduce_comm 的功能是设置通信算法,比如建立 AllReduceInPlaceComm,构建 GroupedExchangeWgrad。
void Parser::create_allreduce_comm(const std::shared_ptr<ResourceManager>& resource_manager,
std::shared_ptr<ExchangeWgrad>& exchange_wgrad) {
auto ar_algo = AllReduceAlgo::NCCL;
bool grouped_all_reduce = false;
// 获取通信算法配置
if (has_key_(config_, "all_reduce")) {
auto j_all_reduce = get_json(config_, "all_reduce");
std::string ar_algo_name = "Oneshot";
if (has_key_(j_all_reduce, "algo")) {
ar_algo_name = get_value_from_json<std::string>(j_all_reduce, "algo");
}
if (has_key_(j_all_reduce, "grouped")) {
grouped_all_reduce = get_value_from_json<bool>(j_all_reduce, "grouped");
}
if (!find_item_in_map(ar_algo, ar_algo_name, ALLREDUCE_ALGO_MAP)) {
CK_THROW_(Error_t::WrongInput, "All reduce algo unknown: " + ar_algo_name);
}
}
// 设置通信算法,比如建立 AllReduceInPlaceComm
resource_manager->set_ar_comm(ar_algo, use_mixed_precision_);
// 构建 GroupedExchangeWgrad
grouped_all_reduce_ = grouped_all_reduce;
if (grouped_all_reduce_) {
if (use_mixed_precision_) {
exchange_wgrad = std::make_shared<GroupedExchangeWgrad<__half>>(resource_manager);
} else {
exchange_wgrad = std::make_shared<GroupedExchangeWgrad<float>>(resource_manager);
}
} else {
if (use_mixed_precision_) {
exchange_wgrad = std::make_shared<NetworkExchangeWgrad<__half>>(resource_manager);
} else {
exchange_wgrad = std::make_shared<NetworkExchangeWgrad<float>>(resource_manager);
}
}
}
其中 GroupedExchangeWgrad 是用来交换梯度的。
template <typename TypeFP>
class GroupedExchangeWgrad : public ExchangeWgrad {
public:
const BuffPtrs<TypeFP>& get_network_wgrad_buffs() const { return network_wgrad_buffs_; }
const BuffPtrs<TypeFP>& get_embed_wgrad_buffs() const { return embed_wgrad_buffs_; }
void allocate() final;
void update_embed_wgrad_size(size_t size) final;
void allreduce(size_t device_id, cudaStream_t stream);
GroupedExchangeWgrad(const std::shared_ptr<ResourceManager>& resource_manager);
~GroupedExchangeWgrad() = default;
private:
BuffPtrs<TypeFP> network_wgrad_buffs_;
BuffPtrs<TypeFP> embed_wgrad_buffs_;
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> bufs_;
std::shared_ptr<ResourceManager> resource_manager_;
AllReduceInPlaceComm::Handle ar_handle_;
size_t network_wgrad_size_ = 0;
size_t embed_wgrad_size_ = 0;
size_t num_gpus_ = 0;
};
比如通过allreduce进行交换:
template <typename T>
void GroupedExchangeWgrad<T>::allreduce(size_t device_id, cudaStream_t stream) {
auto ar_comm = resource_manager_->get_ar_comm();
ar_comm->all_reduce(ar_handle_, stream, device_id);
}
4.3.3 create_datareader
DataReader 是流水线的主体,它实际包含了流水线的前两级:data reader worker 与 data collector。
4.3.3.1 建立哪些内容
create_datareader 的调用如下,
create_datareader<TypeKey>()(j, sparse_input_map, train_tensor_entries_list,
evaluate_tensor_entries_list, init_data_reader,
train_data_reader, evaluate_data_reader, batch_size_,
batch_size_eval_, use_mixed_precision_, repeat_dataset_,
enable_overlap, resource_manager);
回忆一下,在下面代码之中会调用到create_datareader创建了几个 reader。
parser_->create_pipeline(init_data_reader_, train_data_reader_, evaluate_data_reader_,
embeddings_, networks_, resource_manager_, exchange_wgrad_);
其实就是 Session 之中的几个成员变量,比如:
std::shared_ptr<IDataReader> init_data_reader_;
std::shared_ptr<IDataReader> train_data_reader_; /**< data reader to reading data from data set to embedding. */
std::shared_ptr<IDataReader> evaluate_data_reader_; /**< data reader for evaluation. */
分别用于训练,评估。
4.3.3.2 建立reader
因为代码太长,我们只保留部分关键代码。我们先看create_datareader里面做了什么:这里有两个 reader,一个train_data_reader和一个evaluate_data_reader,也就是一个用于训练,一个用于评估。然后会为他们建立workgroup。
对于Reader,HugeCTR 提供了三种实现:
- Norm:普通文件读取。
- Parquet :parquet格式的文件。
- Raw:Raw 数据集格式与 Norm 数据集格式的不同之处在于训练数据出现在一个二进制文件中。
template <typename TypeKey>
void create_datareader<TypeKey>::operator()(
switch (format) {
case DataReaderType_t::Norm: {
bool start_right_now = repeat_dataset;
train_data_reader->create_drwg_norm(source_data, check_type, start_right_now);
evaluate_data_reader->create_drwg_norm(eval_source, check_type, start_right_now);
break;
}
case DataReaderType_t::Raw: {
const auto num_samples = get_value_from_json<long long>(j, "num_samples");
const auto eval_num_samples = get_value_from_json<long long>(j, "eval_num_samples");
std::vector<long long> slot_offset = f();
bool float_label_dense = get_value_from_json_soft<bool>(j, "float_label_dense", false);
train_data_reader->create_drwg_raw(source_data, num_samples, float_label_dense, true,
false);
evaluate_data_reader->create_drwg_raw(eval_source, eval_num_samples, float_label_dense,
false, false);
break;
}
case DataReaderType_t::Parquet: {
// @Future: Should be slot_offset here and data_reader ctor should
// be TypeKey not long long
std::vector<long long> slot_offset = f();
train_data_reader->create_drwg_parquet(source_data, slot_offset, true);
evaluate_data_reader->create_drwg_parquet(eval_source, slot_offset, true);
break;
}
}
}
我们以 norm 为例进行解析,首先提一下,其内部建立了 WorkerGroup。
void create_drwg_norm(std::string file_name, Check_t check_type,
bool start_reading_from_beginning = true) override {
source_type_ = SourceType_t::FileList;
worker_group_.reset(new DataReaderWorkerGroupNorm<TypeKey>(
thread_buffers_, resource_manager_, file_name, repeat_, check_type, params_,
start_reading_from_beginning));
file_name_ = file_name;
}
4.3.3.3 DataReaderWorkerGroupNorm
在 DataReaderWorkerGroupNorm 之中,建立了DataReaderWorker,其中 file_list_ 是需要读取的数据文件。
template <typename TypeKey>
class DataReaderWorkerGroupNorm : public DataReaderWorkerGroup {
std::string file_list_; /**< file list of data set */
std::shared_ptr<Source> create_source(size_t worker_id, size_t num_worker,
const std::string &file_name, bool repeat) override {
return std::make_shared<FileSource>(worker_id, num_worker, file_name, repeat);
}
public:
// Ctor
DataReaderWorkerGroupNorm(const std::vector<std::shared_ptr<ThreadBuffer>> &output_buffers,
const std::shared_ptr<ResourceManager> &resource_manager_,
std::string file_list, bool repeat, Check_t check_type,
const std::vector<DataReaderSparseParam> ¶ms,
bool start_reading_from_beginning = true)
: DataReaderWorkerGroup(start_reading_from_beginning, DataReaderType_t::Norm) {
int num_threads = output_buffers.size();
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
// create data reader workers
int max_feature_num_per_sample = 0;
for (auto ¶m : params) {
max_feature_num_per_sample += param.max_feature_num;
}
set_resource_manager(resource_manager_);
for (int i = 0; i < num_threads; i++) {
std::shared_ptr<IDataReaderWorker> data_reader(new DataReaderWorker<TypeKey>(
i, num_threads, resource_manager_->get_local_gpu(i % local_gpu_count),
&data_reader_loop_flag_, output_buffers[i], file_list, max_feature_num_per_sample, repeat,
check_type, params));
data_readers_.push_back(data_reader);
}
create_data_reader_threads();
}
};
然后创建了多个线程 data_reader_threads_ 分别运行这些 woker。
/**
* Create threads to run data reader workers
>>>>>>> v3.1_preview
*/
void create_data_reader_threads() {
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
for (size_t i = 0; i < data_readers_.size(); ++i) {
auto local_gpu = resource_manager_->get_local_gpu(i % local_gpu_count);
data_reader_threads_.emplace_back(data_reader_thread_func_, data_readers_[i],
&data_reader_loop_flag_, local_gpu->get_device_id());
}
}
4.3.4 小结
我们总结一下。DataReader 包含了流水线的前两级,目前分析之涉及到了第一级。在 Reader之中,有一个 worker group,里面包含了若干worker,也有若干对应线程来运行这些 worker, Data Reader worker 就是流水线第一级。第二级 collecotr 我们会暂时跳过去在下一章进行介绍。
4.4 建立嵌入
我们直接调过来看流水线第三级,如下代码建立了嵌入。
create_embedding<TypeKey, float>()(
sparse_input_map, train_tensor_entries_list, evaluate_tensor_entries_list,
embeddings, embedding_type, config_, resource_manager, batch_size_,
batch_size_eval_, exchange_wgrad, use_mixed_precision_, scaler_, j, use_cuda_graph_,
grouped_all_reduce_);
这里建立了一些embedding,比如DistributedSlotSparseEmbeddingHash。
如前文所述,HugeCTR 包含了若干 Hash,比如:
-
LocalizedSlotEmbeddingHash:同一个槽(特征域)中的特征会存储在一个GPU中,这就是为什么它被称为“本地化槽”,根据槽的索引号,不同的槽可能存储在不同的GPU中。
-
DistributedSlotEmbeddingHash:所有特征都存储于不同特征域/槽上,不管槽索引号是多少,这些特征都根据特征的索引号分布到不同的GPU上。这意味着同一插槽中的特征可能存储在不同的 GPU 中,这就是将其称为“分布式插槽”的原因。
以下代码省略了很多,有兴趣的读者可以深入源码进行阅读。
template <typename TypeKey, typename TypeFP>
void create_embedding<TypeKey, TypeFP>::operator()(
std::map<std::string, SparseInput<TypeKey>>& sparse_input_map,
std::vector<TensorEntry>* train_tensor_entries_list,
std::vector<TensorEntry>* evaluate_tensor_entries_list,
std::vector<std::shared_ptr<IEmbedding>>& embeddings, Embedding_t embedding_type,
const nlohmann::json& config, const std::shared_ptr<ResourceManager>& resource_manager,
size_t batch_size, size_t batch_size_eval, std::shared_ptr<ExchangeWgrad>& exchange_wgrad,
bool use_mixed_precision, float scaler, const nlohmann::json& j_layers, bool use_cuda_graph,
bool grouped_all_reduce) {
#ifdef ENABLE_MPI
int num_procs = 1, pid = 0; // 建立 MPI相关
MPI_Comm_rank(MPI_COMM_WORLD, &pid);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
#endif
// 从配置文件之中读取
auto j_optimizer = get_json(config, "optimizer");
auto embedding_name = get_value_from_json<std::string>(j_layers, "type");
auto bottom_name = get_value_from_json<std::string>(j_layers, "bottom");
auto top_name = get_value_from_json<std::string>(j_layers, "top");
auto j_hparam = get_json(j_layers, "sparse_embedding_hparam");
size_t workspace_size_per_gpu_in_mb =
get_value_from_json_soft<size_t>(j_hparam, "workspace_size_per_gpu_in_mb", 0);
auto embedding_vec_size = get_value_from_json<size_t>(j_hparam, "embedding_vec_size");
size_t max_vocabulary_size_per_gpu =
(workspace_size_per_gpu_in_mb * 1024 * 1024) / (sizeof(float) * embedding_vec_size);
auto combiner_str = get_value_from_json<std::string>(j_hparam, "combiner");
int combiner; // 设定combiner方法
if (combiner_str == "sum") {
combiner = 0;
} else if (combiner_str == "mean") {
combiner = 1;
} else {
CK_THROW_(Error_t::WrongInput, "No such combiner type: " + combiner_str);
}
// 设定slot配置
std::vector<size_t> slot_size_array;
if (has_key_(j_hparam, "slot_size_array")) {
auto slots = get_json(j_hparam, "slot_size_array");
assert(slots.is_array());
for (auto slot : slots) {
slot_size_array.emplace_back(slot.get<size_t>());
}
}
SparseInput<TypeKey> sparse_input;
// 设定优化器配置
OptParams embedding_opt_params;
if (has_key_(j_layers, "optimizer")) {
embedding_opt_params = get_optimizer_param(get_json(j_layers, "optimizer"));
} else {
embedding_opt_params = get_optimizer_param(j_optimizer);
}
embedding_opt_params.scaler = scaler;
// 建立不同的hash
switch (embedding_type) {
case Embedding_t::DistributedSlotSparseEmbeddingHash: {
const SparseEmbeddingHashParams embedding_params = {batch_size,
batch_size_eval,
max_vocabulary_size_per_gpu,
{},
embedding_vec_size,
sparse_input.max_feature_num_per_sample,
sparse_input.slot_num,
combiner, // combiner: 0-sum, 1-mean
embedding_opt_params};
embeddings.emplace_back(new DistributedSlotSparseEmbeddingHash<TypeKey, TypeFP>(
sparse_input.train_sparse_tensors, sparse_input.evaluate_sparse_tensors, embedding_params,
resource_manager));
break;
}
case Embedding_t::LocalizedSlotSparseEmbeddingHash: {
const SparseEmbeddingHashParams embedding_params = {batch_size,
batch_size_eval,
max_vocabulary_size_per_gpu,
slot_size_array,
embedding_vec_size,
sparse_input.max_feature_num_per_sample,
sparse_input.slot_num,
combiner, // combiner: 0-sum, 1-mean
embedding_opt_params};
embeddings.emplace_back(new LocalizedSlotSparseEmbeddingHash<TypeKey, TypeFP>(
sparse_input.train_sparse_tensors, sparse_input.evaluate_sparse_tensors, embedding_params,
resource_manager));
break;
}
case Embedding_t::LocalizedSlotSparseEmbeddingOneHot: {
const SparseEmbeddingHashParams embedding_params = {...};
embeddings.emplace_back(new LocalizedSlotSparseEmbeddingOneHot<TypeKey, TypeFP>(
sparse_input.train_sparse_tensors, sparse_input.evaluate_sparse_tensors, embedding_params,
resource_manager));
break;
}
case Embedding_t::HybridSparseEmbedding: {
const HybridSparseEmbeddingParams<TypeFP> embedding_params = {...};
embeddings.emplace_back(new HybridSparseEmbedding<TypeKey, TypeFP>(
sparse_input.train_sparse_tensors, sparse_input.evaluate_sparse_tensors, embedding_params,
embed_wgrad_buff, get_gpu_learning_rate_schedulers(config, resource_manager), graph_mode,
resource_manager));
break;
}
} // switch
}
4.5 建立网络
接下来是建立网络环节,这部分过后,hugeCTR系统就正式建立起来,可以进行训练了,大体逻辑是:
- 进行GPU内存分配,这里大量使用了 create_block,其中就是 BufferBlockImpl。
- 建立训练网络层。
- 建立评估网络层。
- 建立优化器。
- 初始化网络其他信息。
Network* Network::create_network(const nlohmann::json& j_array, const nlohmann::json& j_optimizer,
std::vector<TensorEntry>& train_tensor_entries,
std::vector<TensorEntry>& evaluate_tensor_entries,
int num_networks_in_global,
std::shared_ptr<ExchangeWgrad>& exchange_wgrad,
const std::shared_ptr<CPUResource>& cpu_resource,
const std::shared_ptr<GPUResource>& gpu_resource,
bool use_mixed_precision, bool enable_tf32_compute, float scaler,
bool use_algorithm_search, bool use_cuda_graph,
bool inference_flag, bool grouped_all_reduce) {
Network* network = new Network(cpu_resource, gpu_resource, use_mixed_precision, use_cuda_graph);
auto& train_layers = network->train_layers_;
auto* bottom_layers = &network->bottom_layers_;
auto* top_layers = &network->top_layers_;
auto& evaluate_layers = network->evaluate_layers_;
auto& train_loss_tensor = network->train_loss_tensor_;
auto& evaluate_loss_tensor = network->evaluate_loss_tensor_;
auto& train_loss = network->train_loss_;
auto& evaluate_loss = network->evaluate_loss_;
auto& enable_cuda_graph = network->enable_cuda_graph_;
auto& raw_metrics = network->raw_metrics_;
// 会进行GPU内存分配,这里大量使用了 create_block,其中就是 BufferBlockImpl
std::shared_ptr<GeneralBuffer2<CudaAllocator>> blobs_buff =
GeneralBuffer2<CudaAllocator>::create();
std::shared_ptr<BufferBlock2<float>> train_weight_buff = blobs_buff->create_block<float>();
std::shared_ptr<BufferBlock2<__half>> train_weight_buff_half = blobs_buff->create_block<__half>();
std::shared_ptr<BufferBlock2<float>> wgrad_buff = nullptr;
std::shared_ptr<BufferBlock2<__half>> wgrad_buff_half = nullptr;
if (!inference_flag) {
if (use_mixed_precision) {
auto id = gpu_resource->get_local_id();
wgrad_buff_half =
(grouped_all_reduce)
? std::dynamic_pointer_cast<GroupedExchangeWgrad<__half>>(exchange_wgrad)
->get_network_wgrad_buffs()[id]
: std::dynamic_pointer_cast<NetworkExchangeWgrad<__half>>(exchange_wgrad)
->get_network_wgrad_buffs()[id];
wgrad_buff = blobs_buff->create_block<float>(); // placeholder
} else {
auto id = gpu_resource->get_local_id();
wgrad_buff = (grouped_all_reduce)
? std::dynamic_pointer_cast<GroupedExchangeWgrad<float>>(exchange_wgrad)
->get_network_wgrad_buffs()[id]
: std::dynamic_pointer_cast<NetworkExchangeWgrad<float>>(exchange_wgrad)
->get_network_wgrad_buffs()[id];
wgrad_buff_half = blobs_buff->create_block<__half>(); // placeholder
}
} else {
wgrad_buff = blobs_buff->create_block<float>();
wgrad_buff_half = blobs_buff->create_block<__half>();
}
std::shared_ptr<BufferBlock2<float>> evaluate_weight_buff = blobs_buff->create_block<float>();
std::shared_ptr<BufferBlock2<__half>> evaluate_weight_buff_half =
blobs_buff->create_block<__half>();
std::shared_ptr<BufferBlock2<float>> wgrad_buff_placeholder = blobs_buff->create_block<float>();
std::shared_ptr<BufferBlock2<__half>> wgrad_buff_half_placeholder =
blobs_buff->create_block<__half>();
std::shared_ptr<BufferBlock2<float>> opt_buff = blobs_buff->create_block<float>();
std::shared_ptr<BufferBlock2<__half>> opt_buff_half = blobs_buff->create_block<__half>();
// 建立训练网络层
if (!inference_flag) {
// create train layers
create_layers(j_array, train_tensor_entries, blobs_buff, train_weight_buff,
train_weight_buff_half, wgrad_buff, wgrad_buff_half, train_loss_tensor,
gpu_resource, use_mixed_precision, enable_tf32_compute, num_networks_in_global,
scaler, enable_cuda_graph, inference_flag, train_layers, train_loss, nullptr,
top_layers, bottom_layers);
}
// 建立评估网络层
// create evaluate layers
create_layers(j_array, evaluate_tensor_entries, blobs_buff, evaluate_weight_buff,
evaluate_weight_buff_half, wgrad_buff_placeholder, wgrad_buff_half_placeholder,
evaluate_loss_tensor, gpu_resource, use_mixed_precision, enable_tf32_compute,
num_networks_in_global, scaler, enable_cuda_graph, inference_flag, evaluate_layers,
evaluate_loss, &raw_metrics);
// 建立优化器
// create optimizer
if (!inference_flag) {
if (use_mixed_precision) {
auto opt_param = get_optimizer_param(j_optimizer);
network->optimizer_ = std::move(Optimizer::Create(opt_param, train_weight_buff->as_tensor(),
wgrad_buff_half->as_tensor(), scaler,
opt_buff_half, gpu_resource));
} else {
auto opt_param = get_optimizer_param(j_optimizer);
network->optimizer_ =
std::move(Optimizer::Create(opt_param, train_weight_buff->as_tensor(),
wgrad_buff->as_tensor(), scaler, opt_buff, gpu_resource));
}
} else {
try {
TensorEntry pred_tensor_entry = evaluate_tensor_entries.back();
if (use_mixed_precision) {
network->pred_tensor_half_ = Tensor2<__half>::stretch_from(pred_tensor_entry.bag);
} else {
network->pred_tensor_ = Tensor2<float>::stretch_from(pred_tensor_entry.bag);
}
} catch (const std::runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
}
// 初始化网络其他信息
network->train_weight_tensor_ = train_weight_buff->as_tensor();
network->train_weight_tensor_half_ = train_weight_buff_half->as_tensor();
network->wgrad_tensor_ = wgrad_buff->as_tensor();
network->wgrad_tensor_half_ = wgrad_buff_half->as_tensor();
network->evaluate_weight_tensor_ = evaluate_weight_buff->as_tensor();
network->evaluate_weight_tensor_half_ = evaluate_weight_buff_half->as_tensor();
network->opt_tensor_ = opt_buff->as_tensor();
network->opt_tensor_half_ = opt_buff_half->as_tensor();
CudaDeviceContext context(gpu_resource->get_device_id());
blobs_buff->allocate();
return network;
}
4.5.1 create_layers
create_layers 有两个版本,分别是HugeCTR/src/parsers/create_network.cpp 和 HugeCTR/src/cpu/create_network_cpu.cpp,我们使用 create_network.cpp 的代码来看看。
其实就是遍历从配置读取的json数组,然后建立每一层,因为层类型太多,所以我们只给出了两个例子。
void create_layers(const nlohmann::json& j_array, std::vector<TensorEntry>& tensor_entries,
const std::shared_ptr<GeneralBuffer2<CudaAllocator>>& blobs_buff,
const std::shared_ptr<BufferBlock2<float>>& weight_buff,
const std::shared_ptr<BufferBlock2<__half>>& weight_buff_half,
const std::shared_ptr<BufferBlock2<float>>& wgrad_buff,
const std::shared_ptr<BufferBlock2<__half>>& wgrad_buff_half,
Tensor2<float>& loss_tensor, const std::shared_ptr<GPUResource>& gpu_resource,
bool use_mixed_precision, bool enable_tf32_compute, int num_networks_in_global,
float scaler, bool& enable_cuda_graph, bool inference_flag,
std::vector<std::unique_ptr<Layer>>& layers, std::unique_ptr<ILoss>& loss,
metrics::RawMetricMap* raw_metrics, std::vector<Layer*>* top_layers = nullptr,
std::vector<Layer*>* bottom_layers = nullptr) {
for (unsigned int i = 1; i < j_array.size(); i++) { // 遍历json数组
const nlohmann::json& j = j_array[i];
const auto layer_type_name = get_value_from_json<std::string>(j, "type");
Layer_t layer_type;
std::vector<TensorEntry> output_tensor_entries;
// 这里获得本层的输入和输出
auto input_output_info = get_input_tensor_and_output_name(j, tensor_entries);
switch (layer_type) {
// 建立对应的每一层
case Layer_t::ReduceMean: {
int axis = get_json(j, "axis").get<int>();
// 本层输入
Tensor2<float> in_tensor = Tensor2<float>::stretch_from(input_output_info.inputs[0]);
Tensor2<float> out_tensor;
emplaceback_layer(
new ReduceMeanLayer<float>(in_tensor, out_tensor, blobs_buff, axis, gpu_resource));
// 本层输出
output_tensor_entries.push_back({input_output_info.output_names[0], out_tensor.shrink()});
break;
}
case Layer_t::Softmax: {
// 本层输入
Tensor2<float> in_tensor = Tensor2<float>::stretch_from(input_output_info.inputs[0]);
Tensor2<float> out_tensor;
blobs_buff->reserve(in_tensor.get_dimensions(), &out_tensor);
// 本层输出
output_tensor_entries.push_back({input_output_info.output_names[0], out_tensor.shrink()});
emplaceback_layer(new SoftmaxLayer<float>(in_tensor, out_tensor, blobs_buff, gpu_resource));
break;
}
} // end of switch
} // for layers
}
4.5.2 层实现
HugeCTR 属于一个具体而微的深度学习系统,它实现的具体层类型如下:
enum class Layer_t {
BatchNorm,
BinaryCrossEntropyLoss,
Reshape,
Concat,
CrossEntropyLoss,
Dropout,
ELU,
InnerProduct,
FusedInnerProduct,
Interaction,
MultiCrossEntropyLoss,
ReLU,
ReLUHalf,
GRU,
MatrixMultiply,
Scale,
FusedReshapeConcat,
FusedReshapeConcatGeneral,
Softmax,
PReLU_Dice,
ReduceMean,
Sub,
Gather,
Sigmoid,
Slice,
WeightMultiply,
FmOrder2,
Add,
ReduceSum,
MultiCross,
Cast,
DotProduct,
ElementwiseMultiply
};
我们使用 SigmoidLayer 作为例子,大家来看看。
/**
* Sigmoid activation function as a derived class of Layer
*/
template <typename T>
class SigmoidLayer : public Layer {
/*
* stores the references to the input tensors of this layer.
*/
Tensors2<T> in_tensors_;
/*
* stores the references to the output tensors of this layer.
*/
Tensors2<T> out_tensors_;
public:
/**
* Ctor of SigmoidLayer.
* @param in_tensor the input tensor
* @param out_tensor the output tensor which has the same dim with in_tensor
* @param device_id the id of GPU where this layer belongs
*/
SigmoidLayer(const Tensor2<T>& in_tensor, const Tensor2<T>& out_tensor,
const std::shared_ptr<GPUResource>& gpu_resource);
/**
* A method of implementing the forward pass of Sigmoid
* @param stream CUDA stream where the foward propagation is executed
*/
void fprop(bool is_train) override;
/**
* A method of implementing the backward pass of Sigmoid
* @param stream CUDA stream where the backward propagation is executed
*/
void bprop() override;
};
其前向传播如下:
template <typename T>
void SigmoidLayer<T>::fprop(bool is_train) {
CudaDeviceContext context(get_device_id());
int len = in_tensors_[0].get_num_elements();
auto fop = [] __device__(T in) { return T(1) / (T(1) + exponential(-in)); };
MLCommon::LinAlg::unaryOp(out_tensors_[0].get_ptr(), in_tensors_[0].get_ptr(), len, fop,
get_gpu().get_stream());
#ifndef NDEBUG
cudaDeviceSynchronize();
CK_CUDA_THROW_(cudaGetLastError());
#endif
}
其后向传播如下:
template <typename T>
void SigmoidLayer<T>::bprop() {
CudaDeviceContext context(get_device_id());
int len = in_tensors_[0].get_num_elements();
auto bop = [] __device__(T d_out, T d_in) {
T y = T(1) / (T(1) + exponential(-d_in));
return d_out * y * (T(1) - y);
};
MLCommon::LinAlg::binaryOp(in_tensors_[0].get_ptr(), out_tensors_[0].get_ptr(),
in_tensors_[0].get_ptr(), len, bop, get_gpu().get_stream());
#ifndef NDEBUG
cudaDeviceSynchronize();
CK_CUDA_THROW_(cudaGetLastError());
#endif
}
至此,HugeCTR 已经初始化完毕,接下来可以开始训练了,我们摘录官方HugeCTR_Webinar 之中的图来给大家做一个梳理,这里CSR是嵌入层依赖的数据格式,我们下文会分析。

4.5.3 层与层之间如何串联
我们尚且有一个疑问,那就是层与层之间如何串联起来?
在create_layers之中有如下代码:
// 获取本层的输入和输出
auto input_output_info = get_input_tensor_and_output_name(j, tensor_entries);
get_input_tensor_and_output_name 的代码如下,可以看到,每一层都会记录自己的输入和输出,结合内部解析模块,这些层就建立其了逻辑关系。
static InputOutputInfo get_input_tensor_and_output_name(
const nlohmann::json& json, const std::vector<TensorEntry>& tensor_entries) {
auto bottom = get_json(json, "bottom");
auto top = get_json(json, "top");
// 从jason获取输入,输出名字
std::vector<std::string> bottom_names = get_layer_names(bottom);
std::vector<std::string> top_names = get_layer_names(top);
std::vector<TensorBag2> bottom_bags;
// 把输出组成一个向量列表
for (auto& bottom_name : bottom_names) {
for (auto& top_name : top_names) {
if (bottom_name == top_name) {
CK_THROW_(Error_t::WrongInput, "bottom and top include a same layer name");
}
}
TensorBag2 bag;
if (!get_tensor_from_entries(tensor_entries, bottom_name, &bag)) {
CK_THROW_(Error_t::WrongInput, "No such bottom: " + bottom_name);
}
bottom_bags.push_back(bag);
}
return {bottom_bags, top_names}; // 返回
}
最终,建立流水线逻辑关系如下:

0x05 训练
具体训练代码逻辑如下:
- 需要 reader 先读取一个 batchsize 的数据。
- 开始解析数据。
- 嵌入层进行前向传播,即从参数服务器读取embedding,进行处理。
- 对于网络层进行前向传播和后向传播,具体区分是多卡,单卡,多机,单机等。
- 嵌入层反向操作。
- 多卡之间交换dense参数的梯度。
- 嵌入层更新sparse参数。
- 各个流进行同步。
bool Session::train() {
try {
// 确保 train_data_reader_ 已经启动
if (train_data_reader_->is_started() == false) {
CK_THROW_(Error_t::IllegalCall,
"Start the data reader first before calling Session::train()");
}
#ifndef DATA_READING_TEST
// 需要 reader 先读取一个 batchsize 的数据。
long long current_batchsize = train_data_reader_->read_a_batch_to_device_delay_release();
if (!current_batchsize) {
return false; // 读不到就退出,没有数据了
}
#pragma omp parallel num_threads(networks_.size()) //其后语句将被networks_.size()个线程并行执行
{
size_t id = omp_get_thread_num();
CudaCPUDeviceContext ctx(resource_manager_->get_local_gpu(id)->get_device_id());
cudaStreamSynchronize(resource_manager_->get_local_gpu(id)->get_stream());
}
// reader 可以开始解析数据
train_data_reader_->ready_to_collect();
#ifdef ENABLE_PROFILING
global_profiler.iter_check();
#endif
// If true we're gonna use overlaping, if false we use default
if (solver_config_.use_overlapped_pipeline) {
train_overlapped();
} else {
for (const auto& one_embedding : embeddings_) {
one_embedding->forward(true); // 嵌入层进行前向传播,即从参数服务器读取embedding,进行处理
}
// Network forward / backward
if (networks_.size() > 1) { // 因为之前是把模型分别拷贝到GPU之上,所以size大于1,就说明多卡
// 单机多卡或多机多卡
// execute dense forward and backward with multi-cpu threads
#pragma omp parallel num_threads(networks_.size())
{
// dense网络的前向反向
size_t id = omp_get_thread_num();
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(id);
networks_[id]->train(current_batchsize_per_device); // 前向操作
const auto& local_gpu = resource_manager_->get_local_gpu(id);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
// 多机单卡
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device); // 前向操作
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
} else {
// 单机单卡
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device); // 前向操作
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
networks_[0]->update_params();
}
// Embedding backward
for (const auto& one_embedding : embeddings_) {
one_embedding->backward(); // 嵌入层反向操作
}
// Exchange wgrad and update params
if (networks_.size() > 1) {
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
exchange_wgrad(id); // 多卡之间交换dense参数的梯度
networks_[id]->update_params();
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
exchange_wgrad(0);
networks_[0]->update_params();
}
for (const auto& one_embedding : embeddings_) {
one_embedding->update_params(); // 嵌入层更新sparse参数
}
// Join streams 各个流进行同步
if (networks_.size() > 1) {
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
const auto& local_gpu = resource_manager_->get_local_gpu(id);
local_gpu->set_compute2_event_sync(local_gpu->get_comp_overlap_stream());
local_gpu->wait_on_compute2_event(local_gpu->get_stream());
}
}
else {
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute2_event_sync(local_gpu->get_comp_overlap_stream());
local_gpu->wait_on_compute2_event(local_gpu->get_stream());
}
return true;
}
#else
data_reader_->read_a_batch_to_device();
#endif
} catch (const internal_runtime_error& err) {
std::cerr << err.what() << std::endl;
throw err;
} catch (const std::exception& err) {
std::cerr << err.what() << std::endl;
throw err;
}
return true;
}
训练流程如下:

至此,我们大体知道了 HugeCTR如何初始化和训练,下一篇我们介绍如何读取数据。
0xFF 参考
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html