-
MultiHeadAttention在Tensorflow中的实现原理
前言
通过这篇文章,你可以学习到Tensorflow实现MultiHeadAttention的底层原理。
一、MultiHeadAttention的本质内涵
1.Self_Atention机制
MultiHeadAttention是Self_Atention的多头堆嵌,有必要对Self_Atention机制进行一次深入浅出的理解,这也是MultiHeadAttention的核心所在。
Self_Attention并不直接使用输入向量,而是先将其进行映射,使得输入向量在每个位置上产生一个query和context,context充当字典。在context的每个位置都提供一个key和value向量。
query:尝试去获取某类信息的序列。
context:包含key序列和value序列,是query感兴趣的内容。
最终输出的形状将与query序列相同。
一个常见的类比是,这种操作就像字典查询。一个模糊的、可区分的、矢量的字典查询。
如下是一个普通的 python 字典类型数据,有 3 个键和 3 个值,并被传递给一个query——"What color is it ?"。这个query会与key="color"最契合,最终得到查询结果value="blue"
。

query是你要尝试去找的东西。key表示字典里有哪些信息,而value就是这些信息。当你在正则字典中查找一个query时,字典会找到匹配的key,并返回其相关的value。这个查询要么有一个匹配的键,要么没有。你可以想象一个模糊的字典,其中的键不一定要完全匹配。如果你在上面的字典中查找 query—"What species is it ?",也许你希望它返回 key="type",value="pickup",因为那是与query最匹配的key和value。
注意力层就像这样做了一个模糊查找,但它不仅仅是在寻找最好的key,而是根据query与每个key的匹配程度来组合这些value。
那是如何做到这一点的呢?在注意力层中,query、key和value都是向量。注意力层不是简单地做哈希查找,而是结合query和key向量来确定它们的匹配程度——计算query和key的向量点积,再将所有匹配程度经过Softmax映射完后,即得到 "注意力得分"。最终该层返回所有value的加权平均值,以 "注意力分数 "为权重。
对于一段具体的文本来说,每一个字都会引发一个疑问query,并提供一个关键值key和一个目标内容value。每个query都会去寻找感兴趣的key,并按注意力分数提取并组合value,


图中越粗的红线对应的attention权重更大,query与key的紧密程度也越近。attention权重如此分布也是很符合情理的,要想回答query =“他是谁?”,我们很大可能会在“是”后面寻找答案,因为“爱人”提供的信息最多,所以它俩的attention权重最大。
总的来说,Self_Attention模拟的是一个符合人脑思维逻辑的研究过程。每当遇到一些新的信息,我们总会产生一定量的疑问(query),为了解决疑问,我们需要在信息中捕捉关键字(key),进而凝练出该关键字中所蕴涵的答案(value)。特定的疑问(query)需要联系特定的关键字(key),进而得出最终答案,这个最终答案往往是折合了不同value而得来的。
2.MultiHead_Atention机制
在不同情景中,字引发的query是不同的,例如,
“他是男的,已婚。”
query可以是”他的性别是什么?”,或者”他结婚了吗?”。不同的query会产生不同的注意力分数。单一的Self_attention无法捕捉多层面query和key之间的依赖关系,因为它只进行一次attention的分配。意在解决此类局限性,MultiHead_Atention会计算多次Self_attention。

利用MultiHead_Atention机制,可以为每一个输入学习到一个信息量丰富的向量表示。
二、使MultiHeadAttention在TensorFlow中的代码实现
1.参数说明
TensorFlow中是用tf.keras.layers.MultiHeadAttention()实现的。它的参数分为两类,一种参数为初始化参数,存在于__init__方法中;另一种为调用参数,存在于call方法中。
主要的初始化参数:
num_heads:Self_Attention的层数
key_dim:query和key多头映射层的输出shape在axis=-1上的长度。因为后续需要计算query和key的点积,所以需要保证query和key在最后一个轴上的长度相等。
value_dim:value多头映射层的输出shape在axis=-1上的长度。如果不指定,则默认等于key_dim
output_shape: 指定输入经过整个MultiHeadAttention层后的输出shape,默认与进入query多头映射层的输入shape相同
主要的call方法参数:
''' B即Batch_size,每一批中的样本数;
T是query的个数,即一段序列产生的疑问个数;S是value和key的个数,即一段序列产生的关键字和关键信息的个数,序列产生的key和value是成对出现的,所以value映射层 和key映射层的输入张量在axis=1处的长度S相同。T和S是可以随意指定的,只需在样本集进入Embedding层之前,先通过一个dense层进行T和S的指定(T和S等于各自dense层中的神经元个数)。例如,文本集shape=(B, S),经过一个具有T个神经元的Dense层→shape=(B, T),再经Embedding层→shape=(B, T, dim),得到query映射层的输入张量。当然,如果不愿如此麻烦,可直接将经Embedding层得到shape=(B, S, dim)的张量作为query映射层的输入;
dim通常是Embedding向量的长度(每个字对应一个Embedding向量)'''
query:输入query多头映射层且shape为(B, T, dim)的张量
value:输入value多头映射层且shape为(B, S, dim)的张量
key:输入key多头映射层且shape为(B, S, dim)的张量,如果未指定,则key=value
use_causal_mask:布尔值,是否开启causal_mask(因果掩码)机制
2.整体结构
tf.keras.layers.MultiHeadAttention类中call()方法的逻辑过程就是MultiHeadAttention的前向传播过程,我将其提炼成以下三部分,
- ''' 多头映射层 '''
- query = self._query_dense(query)
- key = self._key_dense(key)
- value = self._value_dense(value)
- ''' 注意力层 '''
- attention_output, attention_scores = self._compute_attention(
- query, key, value, attention_mask, training
- )
- ''' 输出层 '''
- attention_output = self._output_dense(attention_output)
3.多头映射层
由query多头映射层—query_dense,value多头映射层—value_dense,key多头映射层—key_dense组成。
每个映射层执行的张量运算是一样的,张量运算逻辑为,
' abc , cde -> abde '




该层的训练参数总数为,

4.注意力层
计算query与key之间的内积,张量运算逻辑为,
' aecd, abcd -> acbe '

内积能够反映向量之间的相关程度,内积结果越大则相关性越大,联系也越紧密。得到query和key的内积后,为了得到attention分数,需要将内积结果进行softmax映射。

sttention_scores张量可视作一个B行num_heads列的矩阵,其矩阵中的元素均是T行S列的注意力分数矩阵。当输入是大序列(比如音频序列)时,TransFormer需要维护的注意力分数矩阵将呈
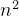 曲线式增长,这种庞大的数据量将会对TransFormer训练和推理的效率和速度产生严重的影响,在内存上的要求也会成曲线式增长。
曲线式增长,这种庞大的数据量将会对TransFormer训练和推理的效率和速度产生严重的影响,在内存上的要求也会成曲线式增长。
最后利用attention分数对value进行加权叠加,张量运算逻辑为,
'acbe,aecd->abcd'


注意:如果指定use_causal_mask=True引入Causal_Mask(因果掩码)机制,则在softmax映射时,会传入一个左下三角为True右上三角为False的,布尔类型的,且与attention_scores.shape相同掩码张量,此时掩码张量中为False的对应位置(对应attention内积张量)将会被softmax忽略。如此一来就会导致每个query只会与当前及其以前的key进行内积,并不会考虑未来的key。进而导致在每个query处产生的新value只会是当前value与过往value在sttention分数上的加权叠加。这样的结构是因果的,符合在预测中结果会对输入产生影响的因果逻辑。因果掩码会在Decoder中使用。
注意力层无可训练的参数。
5.输出映射层
属于MultiHeadAttention的最后一层,负责将注意力层得到的value在sttention分数上的加权叠加后的张量进行输出映射。张量运算逻辑为,
' abcd, cde -> abe '


该层训练参数总共为,

验证
- import tensorflow as tf
- layer = tf.keras.layers.MultiHeadAttention(num_heads=2, key_dim=2)
- target = tf.keras.Input(shape=[9, 16])
- source = tf.keras.Input(shape=[4, 16])
- output_tensor, weights = layer(query=target, value=source,
- return_attention_scores=True)
- ''' 手动计算训练参数总数 '''
- sum = 16*2*2*3+2*2*3+2*2*16+16
- print(f'手动计算的训练参数总数为 : {sum}')
- print(f'训练参数总共为 : {layer.count_params()}')
- print(f'输出shape为 : {output_tensor.shape}')
- print(f'注意力分数shape为 : {weights.shape}')
- 手动计算的训练参数总数为 : 284
- 训练参数总共为 : 284
- 输出shape为 : (None, 9, 16)
- 注意力分数shape为 : (None, 2, 9, 4)

-
相关阅读:
3857墨卡托坐标系转换为4326 (WGS84)经纬度坐标
Python爬虫之Js逆向案例(8)-某乎x-zst-81之webpack
澳福外汇还不会超短线交易,可以了解一下混沌理论
macOS Monterey12.5.1 配置vim
数据分析案例-基于随机森林算法探索影响人类预期寿命的因素并预测人类预期寿命
【Ts】tsconfig.json、package.json、强制编译ts工程
Vue封装组件并发布到npm仓库
Devops学习Day1--概念
Python多进程(process)(二)进程间通讯
C. Magic Grid(构造题,异或性质)
- 原文地址:https://blog.csdn.net/qq_57390446/article/details/138001625
