-
Python学习(打基础版)
以前只是大致的了解,现在比较完整的整理一下笔记,以后工作可能会用到。
第一章 环境配置
1 初识Python
人生苦短,我用Python。由于Python的含义是蟒蛇,所以Python的Logo使用两个蟒蛇表示。

山东省已经将Python加入小学六年级的信息技术的课程之中。
2 编程语言
编程语言是与计算机进行交流的一种语言,可以将其视为一种编译器,写代码->翻译。
自然语言是比较麻烦的,因此使用编程语言是最简便的方式,使用固定的代码去表示固定的东西。关爱人工智障,人人有责。
3 Python环境安装
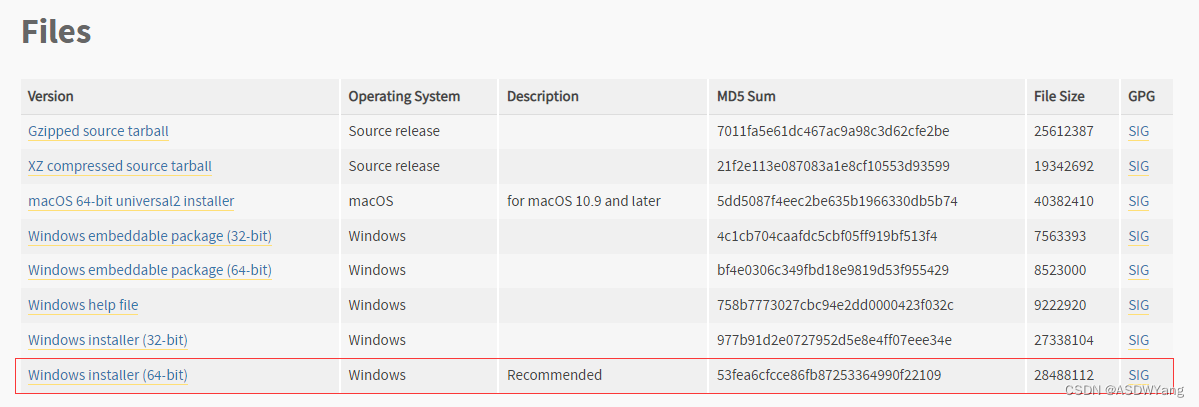
一.下载安装包(windows系统)
1.下载:以3.10.4版本为例,官方地址:Welcome to Python.org

2.进行安装


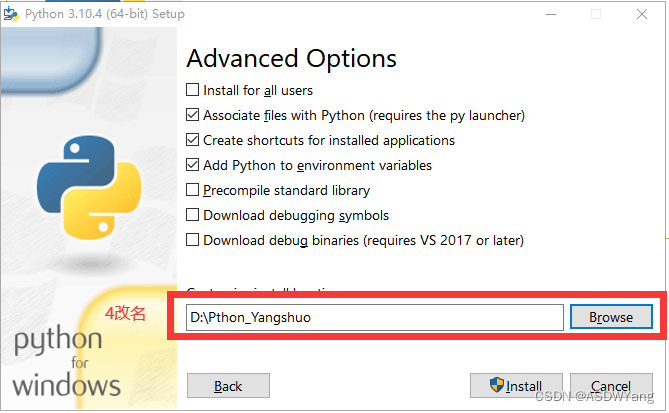
等待一分钟

3.验证是否安装成功


当看到相应的版本就可以得知,相应的python是安装好的。
4 "你好,世界"
win+r,输入cmd

出现的问题:
1.如果输入python并不能够出现版本号,则在进行安装的时候没有选中使用相应的环境变量的过程,需要在网上重新找一下教程,非常简单的。
卸载python的软件,我建议使用geek uninstaller这一款软件,可以卸载相应的注册表,下载地址如下:Geek Uninstaller官方下载_Geek Uninstaller官网下载_Geek Uninstaller电脑版下载
2.出现invaild character的时候,说明括号使用的并不是英文的,需要重新输入字符就可以了。
5 Python解释器
1.Python解释器就是将相应的Python代码解释为二进制,之后进行提交执行的过程。

上面的应用程序.exe文件就是相应的解释器。
2.Python解释器的使用
(1)首先将文档的扩展名展示出来

(2)声明一个.txt结尾的文件

(3)将.txt文件改成.pt文件
(4)出现错误

把刚才文档之中的汉字改为英文就可以了。
6 Python
一.开发环境
1.程序的下载,第三方开发工具PyCharm:JetBrains: Essential tools for software developers and teams



2.程序的安装
安装位置:


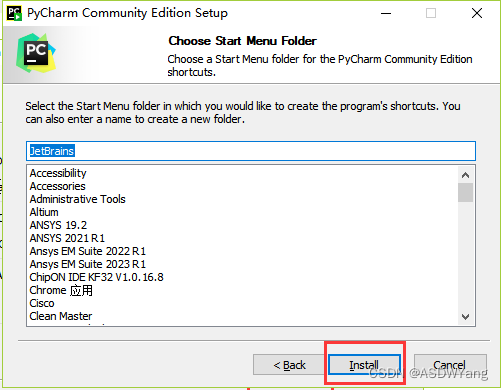
点击运行 - 同意 - 不发送
3.程序的环境



4.程序的创建
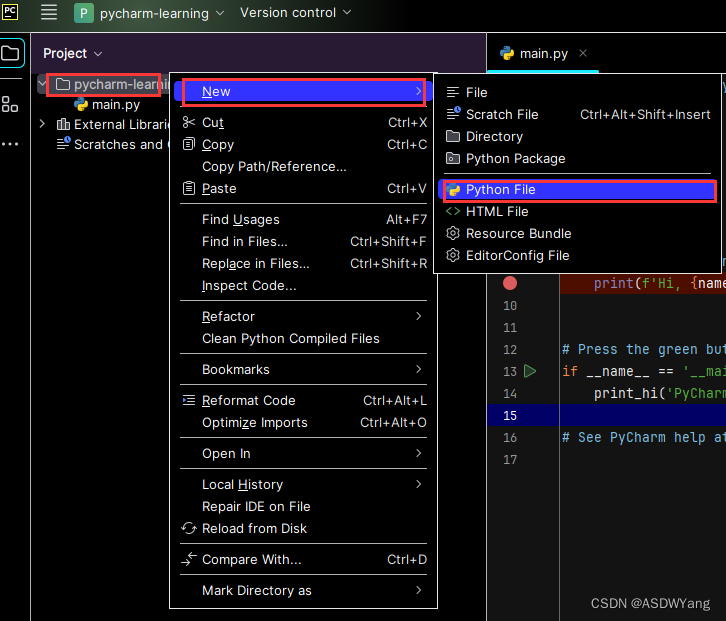
5.执行

二.配置
1.主题

2.字体大小

字体大小方式2
3.中文版界面
4.翻译 选中单词,右键翻译

5.快捷键
shift + alt + 上/下:移动当前句
shift + alt + f10 :运行当前代码
第二章 基础语法
(本章节和C、C++、Java差不多,不做过多解释,只写重点)
单行注释:#+注释内容,#与注释内容间有空格---规范
多行注释:""" 注释内容 """- 变量
程序运行的过程中,用来记录数据的。
- # 定义一个变量,用来记录
- money = 50
- # 买了一个奶黄包,还剩多少钱
- money = money - 10
- print("还有多少钱:", money, "元")
type()直接输出相关的数据类型
- name = "心若不欺,必然扬眉吐气!"
- string_name = type(name)
- print(string_name)

int(x) float(x) str(x),字符串
- # 将数字转换为相应的字符串类型
- num_str = str(11)
- print(type(num_str), num_str)

不建议使用中文,不能够使用数字进行开头,大小写敏感,不可以使用关键字
/:取除法
//:取整除
**:取指数- print("11/2", 11/2)
- print("11//2", 11//2)
- print("3**2", 3**2)

单引号,双引号,三引号定义法
- # 单引号定义法
- name = '老刘打羽毛球'
- print(name)
- # 双引号定义法
- name = "老姚找对象去了"
- print(name)
- # 三引号定义法
- name = """
- 老田这个胖子,
- 晚上打王者荣耀输了,
- 坑坑捶墙
- """
- print(name)

打印相应的单引号与双引号的方法有两种
- # 在字符串内 包含单引号
- name = "'老田去了杭州的海康威视'"
- # 在字符串内 包含双引号
- name = '"老姚去了北京"'
- # 转义字符的使用
- name = "\"老刘去地下工作了\""
1.拼接过程直接使用“+”就是可以的,字符串只能和字符串进行拼接。
2.占位拼接,%:占位,s:将变量变为字符串的地方,d:整数,f:浮点型
- class_id = 1701
- name_id = 201705090102
- message = "我在测控卓越%s班,学号是%s" % (class_id, name_id)
- print(message)

3.精度控制:m.n:m是宽度,n为小数
- num1 = 11
- num2 = 11.345
- print("数字11宽度限制5,结果: %5d" % num1)
- print("数字11宽度限制1,结果: %1d" % num1)
- print("数字11.345宽度限制7,小数精度2,结果 : %7.2f" % num2)
- print("数字11.345不限制宽度,小数精度2,结果 : %.2f" % num2)

4.精度控制:快速写法语法:f"内容{变量}"的格式进行快速格式化,不限数据类型,不做精度控制
- shazi = 2
- print(f"老姚是{shazi}傻子")
概念比较简单,直接使用
- # 定义需要的变量
- name = "老姚"
- daletou_price = 20
- daletou_paper = 2
- # 输出
- print(f"{name}买了{daletou_paper}张大乐透,花了{(daletou_price*daletou_paper)}元" )

input():你是我是谁,我是没头脑!
- print("请告诉我你是谁?")
- name = input()
- print("我知道了,你是:%s" % name)

第三章 判断语句
(本章节和C、C++、Java差不多,不做过多解释,只写重点)
这个地方时比较好理解的,不做过多记录
- # 定义的方法
- zhen = True
- jia = False
- print(f"zhen的变量内容是:{zhen},类型是{type(zhen)}")
- print(f"jia的变量内容是:{jia},类型是{type(jia)}")
- # 比较运算法
- print(f"1000>=50? {1000>=50}")

if 要判断的条件:
条件成立时,要做的事情- age = 18
- if age >= 18:
- print("可以考驾照")
- print("可以写入党申请书")
- have_passid = "是"
- input_pass = input()
- PD = have_passid == input_pass
- print(f"""
- 欢迎来到天津大学,有校园卡可以进入,没有校园卡需要申请。
- 请输入是否有校园卡:{PD}""")
- if PD:
- print("欢迎来到七里台男子职业技术学院")
使用方式见下面的代码
- age = int(input("请输入你的年龄:"))
- if age >= 18:
- print("可以去考驾照了")
- else:
- print("年龄不够,不能考取驾照,去打王者荣耀吧")
1.多条件判断方式
- age = int(input("请输入你的年龄:"))
- if age >= 60:
- print("可以养老")
- elif age >= 23:
- print("可以找女朋友")
- elif age >= 18:
- print("可以考驾照")
- elif age >= 14:
- print("可以打王者")
- else:
- print("你还小,只能看看天线宝宝")
2.练习题-----自己想的题目
A与B两个人说晚饭要吃啥,A猜想B的心理想的什么,只有三次机会。猜错重新猜,猜对则输出。- dinner_B = "地三鲜"
- if str(input("请猜:"))=="地三鲜":
- print("真默契,上来就猜对了")
- elif str(input("不对,接着猜:")) == "地三鲜":
- print("对了")
- elif str(input("还不对,接着猜:")) == "地三鲜":
- print("终于猜对了")
- else:
- print("我想的是地三鲜,没默契,不跟你吃饭了,哈哈哈哈哈")
1.嵌套的关系是通过缩进进行区别的

2.嵌套判断代码
- age = input("请输入您的您的年龄:")
- if int(age) >= 18:
- print("老紫成年人")
- if int(age) <= 30:
- print("青年人")
- else:
- print("不是青年人")
- else:
- print("还是个孩子")
3.例题
案例需求:
定义一个数字(1~10,随机产生),通过3次判断来猜出来数字案例要求:
1. 数字随机产生,范围1-10
2. 有3次机会猜测数字,通过3层嵌套判断实现
3. 每次猜不中,会提示大了或小了- # 1.构建一个随机的数字
- import random
- num = random.randint(1,10)
- # 2.输入猜测的数字
- guess_num = int(input("请进行第一次猜测数字:"))
- # 3.if条件语句进行猜测
- if guess_num == num:
- print("恭喜你,第一次就猜对了!")
- else:
- if guess_num > num:
- print("猜的数字太大了")
- else:
- print("猜的数字太小了")
- guess_num = int(input("请进行第二次猜测数字:"))
- if guess_num == num:
- print("恭喜你,第二次就猜对了!")
- else:
- if (guess_num > num):
- print("猜的数字太大了")
- else:
- print("猜的数字太小了")
- guess_num = int(input("请进行第三次猜测数字:"))
- if guess_num == num:
- print("恭喜你,第三次就猜对了!")
- else:
- if (guess_num > num):
- print("猜的数字太大了")
- else:
- print("猜的数字太小了")

第四章 循环语句
(本章节和C、C++、Java差不多,不做过多解释,只写重点)
1.格式

2.简单的使用
- i = 0
- while i < 100:
- print("小美,双面龟喜欢你!")
- i += 1
3.输出1-100的数量和
- i = 1
- sum = 0
- while i <= 100:
- sum = sum + i
- i += 1
- if i == 101:
- print(sum)
4.猜数字的案例:
设置一个范围1-100的随机整数变量,通过while循环,配合input语句,判断输入的数字是否等于随机数
- 无限次机会,直到猜中为止
- 每一次猜不中,会提示大了或小了
- 猜完数字后,提示猜了几次
- 无限次机会,终止条件不适合用数字累加来判断
- 可以考虑布尔类型本身(True or False)
- 需要提示几次猜中,就需要提供数字累加功能
- # 1.引入随机数字1-100之间的数
- import random
- num = random.randint(1,100)
- # 2.定义一个数字,记录猜的次数
- count = 0
- # 3.进行标志位定义
- flag = True
- # 4.进行循环
- while flag:
- guess_num = int(input("请输入猜的数字:"))
- count += 1
- if guess_num == num:
- print(f"猜对了,猜的次数为{count}")
- flag = False # 退出循环
- else:
- if guess_num > num:
- print("猜的数字太大了")
- else:
- print("猜的数字太小了")

剩余的几个例题是同样的道理,就不写了
1.示例格式
- # 定义字符串name
- name = "zhuzhuxia"
- # for循环处理字符串
- for x in name:
- print(x)
2.判断字符串之中存在多少个字母a
- # 定义字符串name
- name = "itheima is a brand of itcast"
- # 定义一个变量,看里面有多少个字母a
- count = 0
- # for循环处理字符串
- for x in name:
- if x == "a":
- count += 1
- print(f"一共有{count}个字母a")
3.for的嵌套循环

1.语法
①range(num):range(5)->[0,1,2,3,4]
②range(num1,num2):range(5,10)->[5,6,7,8,9]
③range(num1,num2,step):range(5,10,2)->[5,7,9]1.continue:结束本次循环,break:结束循环
第五章 函数
(本章节和C、C++、Java差不多,不做过多解释,只写重点)
1.定义:已组织好,可重复使用,针对特定功能

① 参数如不需要,可以省略(后续章节讲解)
② 返回值如不需要,可以省略(后续章节讲解)
③ 函数必须先定义后使用2.举例说明
- # 定义一个函数,输出相关的信息
- def say_hi():
- print("学Python,就去哔哩哔哩白嫖黑马程序员")
- # 调用
- say_hi()
比较简单,直接写代码,不做过多记录
- # 定义一个函数,输出相关的信息
- def add(x,y):
- result = x + y
- print(f"{x} + {y} = {result}")
- # 使用函数
- add(1,5)
1.定义语法

注意:函数体只要是遇到return,后面的代码是不会进行执行的。2.函数返回值None
其含义就是在函数之中,无论是否写了return,都是存在返回值的
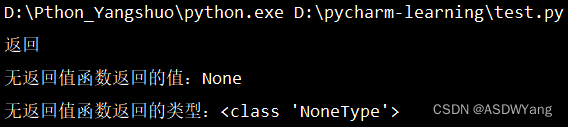
- # 无返回值函数
- def return_result():
- print("返回")
- result = return_result()
- # 使用函数
- print(f"无返回值函数返回的值:{result}")
- print(f"无返回值函数返回的类型:{type(result)}")
注意:None可以视为False,在使用if进行判断时

在一个函数之中调用了另一个函数的使用。

局部变量:出了函数体不能够使用的变量
全局变量:函数体内外都能够正常使用的变量 函数内直接global关键字的使用
第六章 数据容器
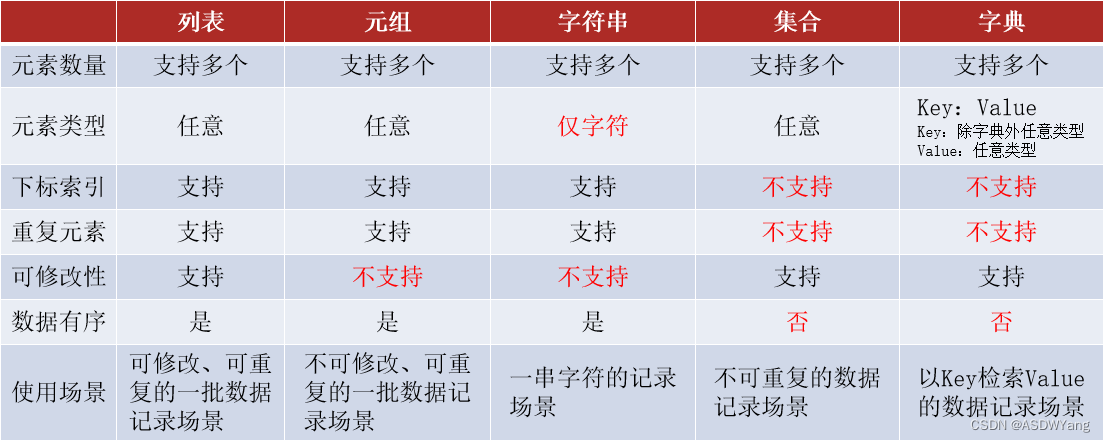
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素 每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,如: 是否支持重复元素、是否可以修改、是否有序
1.定义方式

注意:列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套
2.代码演示
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 打印输出
- print(f"元素为:{my_list} 类型为:{type(my_list)}")

3.下标索引
两种方式:
方式一:正向遍历
方式二:反向遍历

注意针对于嵌套的而言,可以使用双重索引进行使用,和别的语言是一样的使用方式
4.列表的特定方法
(a)方法的概念
在函数之中,如果要是将函数定义为相应的class类的成员,那么函数就是会称之为方法。使用方法如下所示:
- class Student:
- def add(self,x,y):
- return x + y
- student = Student()
- print(f"1+5={student.add(1,5)}")
(b)查询功能:查找某个元素的下标,在进行查询的时候,需要注意查找最后一个元素的方式为下标[-1]
I.功能:查找指定元素在列表的下标,如果找不到,报错ValueError
语法:列表.index(元素) ->index就是列表对象(变量)内置的方法(函数)- # 定义一个列表
- my_list = ["考虫",299,True]
- # 打印输出
- print(f"考虫的索引为:{my_list.index('考虫')} ")
注意:上述代码中的index之中的考虫需要''索引好,跟视频之中不一样

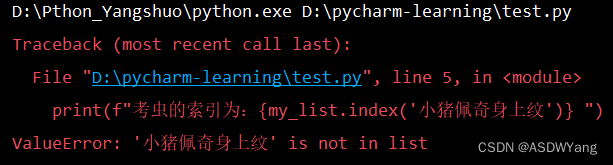
II.如果查询不到,会报出错误
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 打印输出
- print(f"考虫的索引为:{my_list.index('小猪佩奇身上纹')} ")
 (c)
(c)(c)修改list之中的值
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 进行修改的操作
- my_list[0]="新东方"
- # 打印输出
- print(f"考虫的索引为:{my_list} ")
(d)在list之中插入值 insert(下标,元素),在
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 进行插入的操作 第一个元素的含义是在第一个元素前面进行插入
- my_list.insert(0,"考研英语")
- # 打印输出
- print(f"考虫的索引为:{my_list} ")
(e)追加元素,将元素插入到末尾的位置 append(元素)
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 进行插入的操作 第一个元素的含义是在第一个元素前面进行插入
- my_list.append("去哔哩哔哩,白嫖黑马程序员")
- # 打印输出
- print(f"考虫的索引为:{my_list} ")
(f)追加一批元素 extend([元素])
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 进行插入的操作 第一个元素的含义是在第一个元素前面进行插入
- my_list.extend(["新东方",199,False])
- # 打印输出
- print(f"考虫的索引为:{my_list} ")
(g)元素的删除 del 指定元素
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 删除元素
- del my_list[2]
- # 打印输出
- print(f"考虫的索引为:{my_list} ")
(h)元素的删除,并且可以得到删除的那个元素值 pop(下标)
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 删除元素
- pop_element = my_list.pop(0)
- # 打印输出
- print(f"删除之后:{my_list},删除的元素为:{pop_element} ")
(i)元素的删除,制指定的某个元素进行删除 move(元素)
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 删除元素
- my_list.remove(299)
- # 打印输出
- print(f"删除之后:{my_list} ")
(j)列表的清空 clear()
- # 定义一个列表
- my_list = ["考虫",299,True]
- # 清空元素
- my_list.clear()
- # 打印输出
- print(f"清空之后:{my_list} ")
(k)统计某一元素的数量 count(元素)
- # 定义一个列表
- my_list = ["考虫",299,True,"孙悟空","猪八戒","沙僧","孙悟空"]
- # 元素个数
- count = my_list.count("孙悟空")
- # 打印输出
- print(f"元素个数:{count} ")
(l)统计列表织鬃所有的元素的个数
- # 定义一个列表
- my_list = ["考虫",299,True,"孙悟空","猪八戒","沙僧","孙悟空"]
- # 元素个数
- count = len(my_list)
- # 打印输出
- print(f"元素个数:{count} ")
5.列表的循环遍历
(a)使用while循环遍历
- def list_while_func():
- """
- 使用while循环遍历列表
- :return: None
- """
- my_list = ["考虫",299,True,"孙悟空","猪八戒","沙僧","孙悟空"]
- index = 0
- while index < len(my_list):
- element = my_list[index]
- print(f"列表的元素为:{element}")
- index += 1
- list_while_func()
(b)使用for循环遍历
- def list_for_func():
- """
- 使用while循环遍历列表
- :return: None
- """
- my_list = ["考虫",299,True,"孙悟空","猪八戒","沙僧","孙悟空"]
- for element in my_list:
- print(f"列表的元素为:{element}")
- list_for_func()
1.元素的定义
元组和列表是一样的,都是可以封装多个、不同类型的元素在内。但是最大的不同点再远:元组一旦定义完成,就不可修改。
2.定义语法

注意:I 元组要是定义单个元素的时候,后面必须要加一个逗号
- t1 = ("二傻子")
- # 定义单个元组
- t2 = ("二傻子",)
- print(f"t1的类型为{type(t1)},t2的类型为{type(t2)}")

II 同list可以进行嵌套,可以使用取索引取出内容,可以使用index方式查找,count统计,len函数查询长度。方法之中使用下标的方式取值和index方式取值以及len()、count()前面已经得知,不做过多记录。
1.替换 replace(被替换的元素,替换成为的元素)
- str = ("Hello, it is my honor to paticipate in this interview! My name is Yang and I come from CangZhou")
- # replace方法
- new_str = str.replace("CangZhou","Tianjin")
- print(f"{new_str}")
2.分割方法 split(元素)
- str = ("Hello, it is my honor to paticipate in this interview! My name is Yang and I come from CangZhou")
- # split方法
- new_str = str.split(" ")
- print(f"{new_str}")

3.去除操作 strip()
a.字符串.strip():直接去除原始字符串前后的空格
b.字符串.strip(字符串):去除字符串- str = ("123 Hello, it is my honor to paticipate in this interview! My name is Yang and I come from CangZhou 321")
- # strip方法
- new_str = str.strip("132")
- print(f"{new_str}")

注意:使用的过程中,strip("字符串"),字符串是单个的字符串,只要单个一致便可以去除。
4.序列
I.定义:序列是指内容连续、有序,可以使用下标进行索引的一类数据容器。

II.语法
- # 对list进行切片,从1开始,4结束,步长为1
- my_list = [0,1,2,3,4,5,6]
- result1 = my_list[1:4] # 步长默认为1,可以省略不写
- print(f"结果1:{result1}")
- # 对tuple进行切片,从头开始,最后结束,步长为1
- my_tuple = (0,1,2,3,4,5,6)
- result2 = my_tuple[:] # 起始和结束不写表示从头到尾,步长为1可以省略
- print(f"结果2:{result2}")
- # 对str进行切片,从头开始,到最后结束,步长为2
- my_str = "0123456"
- result3 = my_str[::2]
- print(f"结果3:{result3}")
- # 对str进行切片,从头开始,最后结束,步长为-1
- my_str = "0123456"
- result4 = my_str[::-1] # 等同于将字符串进行翻转
- print(f"结果4:{result4}")
- # 对列表进行切片,从3开始,到1结束,步长为-1
- my_list = [0,1,2,3,4,5,6]
- result5 = my_list[3:1:-1] # 步长默认为1,可以省略不写
- print(f"结果5:{result5}")
- # 对元组进行切片,从头开始,到尾结束,步长为-2
- my_tuple = (0,1,2,3,4,5,6)
- result6 = my_tuple[::-2] # 起始和结束不写表示从头到尾,步长为1可以省略
- print(f"结果6:{result6}")

1.集合的定义
a.为什么要学习set?
b.集合的特点:内部无序,并且是元素不重复
c.定义过程

- # 集合的定义
- my_set = {"孙悟空","猪八戒","林黛玉","贾宝玉","林黛玉","贾宝玉"}
- my_set_empty = set()
- print(f"my_set之中的内容是:{my_set},类型是:{type(my_set)}")
- print(f"my_set_empty之中的内容是:{my_set_empty},类型是:{type(my_set_empty)}")

2.集合的操作
a.修改 add(元素)
b.移除 remove(元素)
c.随机取出一个元素 pop()
d.清空集合 clear()
e.取出2个集合的差集 .differernce(集合)
- # 取2个集合的差集
- my_set1 = {"孙悟空","猪八戒","林黛玉","贾宝玉","林黛玉","贾宝玉"}
- my_set2 = {"孙悟空","林黛玉","贾宝玉"}
- set3 = my_set1.difference(my_set2)
- print(f"两个集合的差集为:{set3}")
f.消除差集,集合1.difference_update(集合2):在集合1内删除掉共有的元素
- # 消除差集
- my_set1 = {"孙悟空","猪八戒","林黛玉","贾宝玉","林黛玉","贾宝玉"}
- my_set2 = {"孙悟空","林黛玉","贾宝玉"}
- set3 = my_set1.difference_update(my_set2)
- print(f"消除差集为:{set3}")
g.2个集合进行合并 集合1.union(集合2)
- # 合并集合
- my_set1 = {"孙悟空","猪八戒","林黛玉","贾宝玉","林黛玉","贾宝玉"}
- my_set2 = {"孙悟空","林黛玉","贾宝玉","老姚"}
- set3 = my_set1.union(my_set2)
- print(f"合并集合为:{set3}")
h.统计集合元素的数量 len(集合)
i.集合的遍历 由于不支持下标索引,因此进行索引的时候,只能够使用for
1.字典的定义


2.特点
字典之中的Key是不可以重复的,若重复只保留后面的Key。
不可以使用下标索引。
使用Key进行索引。3.字典的嵌套
字典的Key和Value都是可以为任意的数据类型,Key是不可以为字典的。


4.字典的常用操作
由于本处是进行Key与Value同时操作,因此,这个地方的代码与前方是不一样的,进行全部记录
- """
- 演示字典的常用操作
- """
- my_dict = {
- "老姚":82,
- "老田":80,
- "老刘":90}
- # 新增元素
- my_dict["老马"] = 85
- print(f"字典经过新增元素之后,结果为:{my_dict}")
- # 更新元素
- my_dict["老马"] = 0 # 老马作弊了,成绩直接变为0
- # 删除元素
- Liu = my_dict.pop("老刘")
- print(f"字典中被移除了一个元素,结果是:{my_dict},移除的分数为:{Liu}")
- # 清空元素,clear()
- # 获取全部的Key
- keys = my_dict.keys()
- print(f"字典之中全部的keys是:{keys}")
- # 遍历字典
- for key in keys:
- print(f"字典之中的Key是:{key}")
- print(f"字典之中的Value是:{my_dict[key]}")
- # 统计字典内的元素数量
- num = len(my_dict)
- print(f"字典之中的元素有{num}个")
1.数据容器的特点对比
2.字符串比较
字符串进行比较的过程是进行按位比较的
第七章 函数进阶
1.表示形式

2.函数参数的种类
a.位置参数:调用函数时根据函数定义的参数位置来传递参数

b.关键字参数:函数调用时通过“键=值”形式传递参数
作用: 可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求
c.缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
作用: 当调用函数时没有传递参数, 就会使用默认是用缺省参数对应的值
d.不定长参数:不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景
作用: 当调用函数时不确定参数个数时, 可以使用不定长参数I.位置传递

注意:
①传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
②位置的不定长传递以*号标记一个形式参数,以元组的形式接受参数,参数的一般命名为argsII.关键字传递

注意:
①参数是“键=值”形式的形式的情况下, 所有的“键=值”都会被kwargs接受, 同时会根据“键=值”组成字典
②关键字不定长传递以**编辑一个形式参数,以字典的形式接受参数,形式参数一般命名为kwargs1.函数作为参数传递

函数作为参数进行使用的过程是比较简单的,是对于计算逻辑进行相应的传递,不做过多记录
2.lambda匿名函数
a.普通函数与lambda函数之间的区别
①函数的定义中 def关键字,可以定义带有名称的函数
②lambda关键字,可以定义匿名函数(无名称)
③有名称的函数,可以基于名称重复使用。
④无名称的匿名函数,只可临时使用一次b.lambda函数的定义语法

lambda 是关键字,表示定义匿名函数
传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数
函数体,就是函数的执行逻辑->注意:只能写一行,无法写多行代码c.具体使用对比

第八章 文件操作
编码技术即:翻译的规则,记录了如何将内容翻译成二进制,以及如何将二进制翻译回可识别内容
编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑。 编码有许多中,我们最常用的是UTF-8编码
1.打开文件open()
 name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加等
encoding:编码格式(推荐使用UTF-8)


- # open()打开文件
- f = open("D:/要长脑子.txt", "r", encoding="gbk")
2.读取方法
a.read(字节数)
- # open()打开文件
- f = open("D:/要长脑子.txt", "r", encoding="gbk")
- # 读取文件read()
- print(f"读取10个字节:{f.read(7)}") # 读取7个字节
- print(f"读取后面的:{f.read()}") # 读取从上个位置开始之后全部的内容
b.readLines()
- # open()打开文件
- f = open("D:/要长脑子.txt", "r", encoding="GBK")
- # 读取文件readLines()
- lines = f.readlines()
- print(f"按照行进行读取:{lines}")
- print(f"按照行进行读取的类型为:{type(lines)}")

c.readline()
- # open()打开文件
- f = open("D:/要长脑子.txt", "r", encoding="GBK")
- # 读取文件readLine()
- line = f.readline()
- print(f"按照行进行读取:{line}")
- print(f"按照行进行读取的类型为:{type(line)}")

d.for循环读取文件行
- # open()打开文件
- f = open("D:/要长脑子.txt", "r", encoding="GBK")
- # 读取文件for
- for line in f:
- print(f"按照行进行读取:{line}")
e.文件的关闭,直接调用
I.直接调用文件.close()
II.使用with 函数,使用结束后,自动关闭- import time
- # 读取文件for
- with open("D:/要长脑子.txt", "r", encoding="GBK") as f:
- for line in f:
- print(f"按照行进行读取:{line}")
- time.sleep(121212)


直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)注意:
①文件如果不存在,使用”w”模式,会创建新文件
②文件如果存在,使用”w”模式,会将原有内容清空
③close()内置了flush()功能
如果要是加入相应的换行,直接使用一个\n
第九章 异常模块与包
1.异常的定义
a.异常(Bug):当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示
b.为什么异常叫做Bug?
1945年9月9日,下午三点,马克二型计算机无法正常工作了,技术人员试了很多办法,最后定位到第70号继电器出错。负责人哈珀观察这个出错的继电器,发现一只飞蛾躺在中间,已经被继电器打死。她小心地用摄子将蛾子夹出来,用透明胶布帖到“事件记录本”中,并注明“第一个发现虫子的实例。”自此之后,引发软件失效的缺陷,便被称为Bug。
早起的马克二号计算机

c.异常的示例

2.异常的捕获
a.当我们的程序遇到了BUG, 那么接下来有两种情况:
① 整个程序因为一个BUG停止运行
② 对BUG进行提醒, 整个程序继续运行(异常的捕获)b.语法

c.示例

d.捕获指定异常

e.捕获多个异常

f.捕获所有异常

g.异常else

h.异常finally:有没有异常都要执行
3.异常的传递

利用异常具有传递性的特点, 当我们想要保证程序不会因为异常崩溃的时候, 就可以在main函数中设置异常捕获, 由于无论在整个程序哪里发生异常, 最终都 会传递到main函数中, 这样就可以确保所有的异常都会被捕获
在最顶级的地方进行调用1.模块的定义
模块(Module),是一个 Python 文件,以 .py 结尾. 模块能定义函数,类和变量,模块里也能包含可执行的代码
2.模块的作用
Python中有很多各种不同的模块, 每一个模块都可以帮助我 们快速的实现一些功能, 比如实现和时间相关的功能就可以使用time模块 我们可以认为一个模块就是一个工具包, 每一个工具包中都有各种不同的 工具供我们使用进而实现各种不同的功能
3.模块的导入

4.基本语法
a.import模块名


b.from 模块名 import 功能名


c.from 模块名 import *


d.as定义别名


5.自定义模块
a.自定义模块

注意事项:当导入多个模块的时候,且模块内有同名功能. 当调用这个同名功能的时候,调用到的是后面导入的模块的功能

b.无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行`test`函数的调用

c.部分导入方式
如果一个模块文件中有`__all__`变量,当使用`from xxx import *`导入时,只能导入这个列表中的元素
1.自定义包
a.定义
①从物理上看,包就是一个文件夹,在该文件夹下包含了一个 __init__.py 文件,该文件夹可用于包含多个模块文件
②从逻辑上看,包的本质依然是模块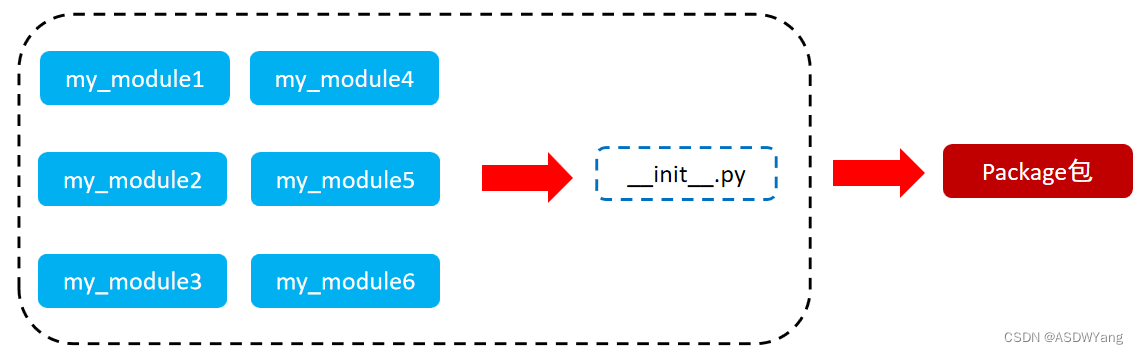
b.作用:当我们的模块文件越来越多时,包可以帮助我们管理这些模块, 包的作用就是包含多个模块,但包的本质依然是模块
c.创建的过程


d.导入包的方式
方式一:

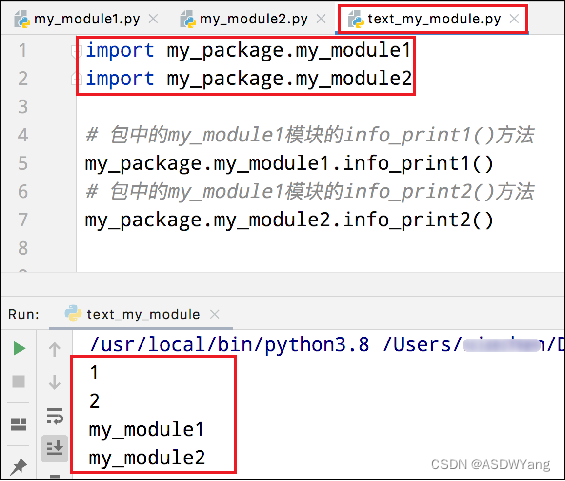
方式二:必须在`__init__.py`文件中添加`__all__ = []`,控制允许导入的模块列表

2.第三方包
a.演示安装第三方包 numpy
windows+R - 输入cmd - pip install numpy
如果国内的网站太慢的话,可以使用下面的命令链接国内的网站进行包的安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
b.测试安装情况

c.软件之中进行安装




安装中

第十章 数据可视化-折线图
1.JSON格式的说明:
①JSON是一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据
②JSON本质上是一个带有特定格式的字符串
主要功能:进行各个语言间的数据流通的数据格式,负责不同编程语言中的数据传递和交互。2.JSON格式数据转换

3.Python数据和Json数据的相互转化

上面的过程是比较容易理解的,不作过多解释。
- """
- 演示将JSON格式的数据与Python格式的数据进行相互的转换
- """
- # 引入相应的JSON库函数
- import json
- # 准备数据 列表形式
- data = [{"name":"小土豆","age":"18"}, {"name":"大地瓜","age":22}, {"name":"铁憨憨","age":90},{"name":"大聪明","age":88}]
- json_str = json.dumps(data,ensure_ascii=False) # ensure_ascii=False保证输出的为文字
- print(type(json_str))
- print(json_str)
- # 准备数据 字典类型
- data = {"name":"小土豆","age":"18"}
- json_str = json.dumps(data,ensure_ascii=False) # ensure_ascii=False保证输出的为文字
- print(type(json_str))
- print(json_str)

- # 将JSON格式的数据转换为Python格式数据
- s = '[{"name":"小土豆","age":"18"}, {"name":"大地瓜","age":22}, {"name":"铁憨憨","age":90},{"name":"大聪明","age":88}]'
- l = json.loads(s)
- print(type(l))
- print(l)
- # 将JSON格式的数据转换为Python格式数据
- s = '{"name":"小土豆","age":"18"}'
- l = json.loads(s)
- print(type(l))
- print(l)

1.简介
Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可. 而 Python 是门富有表达力的语言,很适合用于数据处理. 当数据分析遇上数据可视化时pyecharts 诞生了.
2.官方网站
网站二:DocumentDescription
 https://gallery.pyecharts.org/#/README
https://gallery.pyecharts.org/#/README3.安装
安装过程爆出错误

解决办法
由于使用终端安装总是存在问题,所以我使用软件进行安装
1.基础折线图
- # 导包,导入Line功能构建折线图对象
- from pyecharts.charts import Line
- # 得到折线图对象
- line = Line()
- # 添加x轴数据
- line.add_xaxis(["中国","美国","英国"])
- # 添加y轴数据
- line.add_yaxis("GDP",["30","20","10"])
- # 生成折线图表
- line.render()

将html文件使用谷歌浏览器打开


2.全局配置
set_global_opts方法
- # 导包,导入Line功能构建折线图对象
- from pyecharts.charts import Line
- from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
- # 得到折线图对象
- line = Line()
- # 添加x轴数据
- line.add_xaxis(["中国","美国","英国"])
- # 添加y轴数据
- line.add_yaxis("GDP",["30","20","10"])
- # 设置全局全局配置
- line.set_global_opts(
- title_opts=TitleOpts(title="GDP展示",pos_left="center",pos_bottom="1%"),# 标题
- legend_opts=LegendOpts(is_show=True),
- toolbox_opts=ToolboxOpts(is_show=True),
- visualmap_opts=VisualMapOpts(is_show=True),
- )
- # 生成折线图表
- line.render()

3.案例使用
- """
- 演示可视化需求1:折线图开发
- """
- import json
- from pyecharts.charts import Line
- from pyecharts.options import TitleOpts, LabelOpts
- # 处理数据
- f_us = open("D:/美国.txt", "r", encoding="UTF-8")
- us_data = f_us.read() # 美国的全部内容
- f_jp = open("D:/日本.txt", "r", encoding="UTF-8")
- jp_data = f_jp.read() # 日本的全部内容
- f_in = open("D:/印度.txt", "r", encoding="UTF-8")
- in_data = f_in.read() # 印度的全部内容
- # 去掉不合JSON规范的开头
- us_data = us_data.replace("jsonp_1629344292311_69436(", "")
- jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
- in_data = in_data.replace("jsonp_1629350745930_63180(", "")
- # 去掉不合JSON规范的结尾
- us_data = us_data[:-2]
- jp_data = jp_data[:-2]
- in_data = in_data[:-2]
- # JSON转Python字典
- us_dict = json.loads(us_data)
- jp_dict = json.loads(jp_data)
- in_dict = json.loads(in_data)
- # 获取trend key
- us_trend_data = us_dict['data'][0]['trend']
- jp_trend_data = jp_dict['data'][0]['trend']
- in_trend_data = in_dict['data'][0]['trend']
- # 获取日期数据,用于x轴,取2020年(到314下标结束)
- us_x_data = us_trend_data['updateDate'][:314]
- jp_x_data = jp_trend_data['updateDate'][:314]
- in_x_data = in_trend_data['updateDate'][:314]
- # 获取确认数据,用于y轴,取2020年(到314下标结束)
- us_y_data = us_trend_data['list'][0]['data'][:314]
- jp_y_data = jp_trend_data['list'][0]['data'][:314]
- in_y_data = in_trend_data['list'][0]['data'][:314]
- # 生成图表
- line = Line() # 构建折线图对象
- # 添加x轴数据
- line.add_xaxis(us_x_data) # x轴是公用的,所以使用一个国家的数据即可
- # 添加y轴数据
- line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
- line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
- line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据
- # 设置全局选项
- line.set_global_opts(
- # 标题设置
- title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
- )
- # 调用render方法,生成图表
- line.render()
- # 关闭文件对象
- f_us.close()
- f_jp.close()
- f_in.close()
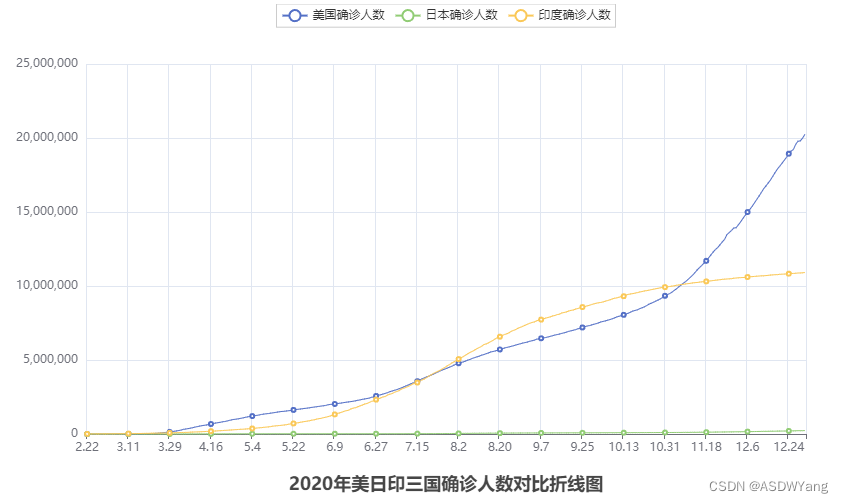
第十一章 数据可视化-地图


- """
- 演示全国疫情可视化地图开发
- """
- import json
- from pyecharts.charts import Map
- from pyecharts.options import *
- # 读取数据文件
- f = open("D:/疫情.txt", "r", encoding="UTF-8")
- data = f.read() # 全部数据
- # 关闭文件
- f.close()
- # 取到各省数据
- # 将字符串json转换为python的字典
- data_dict = json.loads(data) # 基础数据字典
- # 从字典中取出省份的数据
- province_data_list = data_dict["areaTree"][0]["children"]
- # 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内
- data_list = [] # 绘图需要用的数据列表
- for province_data in province_data_list:
- province_name = province_data["name"] # 省份名称
- province_confirm = province_data["total"]["confirm"] # 确诊人数
- data_list.append((province_name, province_confirm))
- # 创建地图对象
- map = Map()
- # 添加数据
- map.add("各省份确诊人数", data_list, "china")
- # 设置全局配置,定制分段的视觉映射
- map.set_global_opts(
- title_opts=TitleOpts(title="全国疫情地图"),
- visualmap_opts=VisualMapOpts(
- is_show=True, # 是否显示
- is_piecewise=True, # 是否分段
- pieces=[
- {"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"},
- {"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"},
- {"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"},
- {"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"},
- {"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"},
- {"min": 100000, "lable": "100000+", "color": "#990033"},
- ]
- )
- )
- # 绘图
- map.render("全国疫情地图.html")

第十二章 数据可视化-动态柱状图
1.基础柱状图
Timeline()-时间线

- """
- 基础柱状图
- """
- from pyecharts.charts import Bar
- from pyecharts.options import LabelOpts
- # 使用Bar构建基础柱状图
- bar = Bar()
- # 添加x轴的数据
- bar.add_xaxis(["中国", "美国", "英国"])
- # 添加y轴数据
- bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
- # 反转x和y轴
- bar.reversal_axis()
- # 绘图
- bar.render("基础柱状图.html")
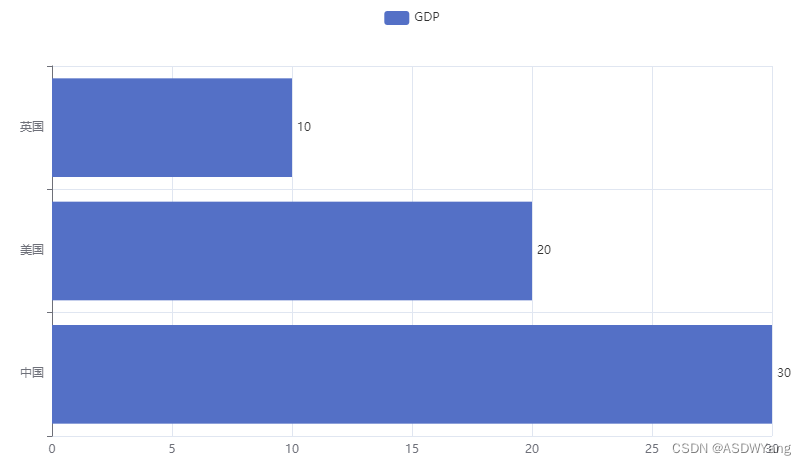
2.基础时间线柱状图
- """
- 带有时间线的柱状图
- """
- from pyecharts.charts import Bar, Timeline
- from pyecharts.options import LabelOpts
- from pyecharts.globals import ThemeType
- bar1 = Bar()
- bar1.add_xaxis(["中国", "美国", "英国"])
- bar1.add_yaxis("GDP", [30, 30, 20], label_opts=LabelOpts(position="right"))
- bar1.reversal_axis()
- bar2 = Bar()
- bar2.add_xaxis(["中国", "美国", "英国"])
- bar2.add_yaxis("GDP", [50, 50, 50], label_opts=LabelOpts(position="right"))
- bar2.reversal_axis()
- bar3 = Bar()
- bar3.add_xaxis(["中国", "美国", "英国"])
- bar3.add_yaxis("GDP", [70, 60, 60], label_opts=LabelOpts(position="right"))
- bar3.reversal_axis()
- # 构建时间线对象
- timeline = Timeline({"theme": ThemeType.LIGHT})
- # 在时间线内添加柱状图对象
- timeline.add(bar1, "点1")
- timeline.add(bar2, "点2")
- timeline.add(bar3, "点3")
- # 自动播放设置
- timeline.add_schema(
- play_interval=1000,
- is_timeline_show=True,
- is_auto_play=True,
- is_loop_play=True
- )
- # 绘图是用时间线对象绘图,而不是bar对象了
- timeline.render("基础时间线柱状图.html")

3.动态柱状图的绘制
列表的sort方法
列表.sort(key=选择排序依据的函数, reverse=True|False) 参数key,是要求传入一个函数,表示将列表的每一个元素都传入函数中,返回排序的依据
参数reverse,是否反转排序结果,True表示降序,False表示升序

- """
- GDP动态柱状图开发
- """
- from pyecharts.charts import Bar, Timeline
- from pyecharts.options import *
- from pyecharts.globals import ThemeType
- # 读取数据
- f = open("D:/1960-2019全球GDP数据.csv", "r", encoding="GB2312")
- data_lines = f.readlines()
- # 关闭文件
- f.close()
- # 删除第一条数据
- data_lines.pop(0)
- # 将数据转换为字典存储,格式为:
- # { 年份: [ [国家, gdp], [国家,gdp], ...... ], 年份: [ [国家, gdp], [国家,gdp], ...... ], ...... }
- # { 1960: [ [美国, 123], [中国,321], ...... ], 1961: [ [美国, 123], [中国,321], ...... ], ...... }
- # 先定义一个字典对象
- data_dict = {}
- for line in data_lines:
- year = int(line.split(",")[0]) # 年份
- country = line.split(",")[1] # 国家
- gdp = float(line.split(",")[2]) # gdp数据
- # 如何判断字典里面有没有指定的key呢?
- try:
- data_dict[year].append([country, gdp])
- except KeyError:
- data_dict[year] = []
- data_dict[year].append([country, gdp])
- # print(data_dict[1960])
- # 创建时间线对象
- timeline = Timeline({"theme": ThemeType.LIGHT})
- # 排序年份
- sorted_year_list = sorted(data_dict.keys())
- for year in sorted_year_list:
- data_dict[year].sort(key=lambda element: element[1], reverse=True)
- # 取出本年份前8名的国家
- year_data = data_dict[year][0:8]
- x_data = []
- y_data = []
- for country_gdp in year_data:
- x_data.append(country_gdp[0]) # x轴添加国家
- y_data.append(country_gdp[1] / 100000000) # y轴添加gdp数据
- # 构建柱状图
- bar = Bar()
- x_data.reverse()
- y_data.reverse()
- bar.add_xaxis(x_data)
- bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right"))
- # 反转x轴和y轴
- bar.reversal_axis()
- # 设置每一年的图表的标题
- bar.set_global_opts(
- title_opts=TitleOpts(title=f"{year}年全球前8GDP数据")
- )
- timeline.add(bar, str(year))
- # for循环每一年的数据,基于每一年的数据,创建每一年的bar对象
- # 在for中,将每一年的bar对象添加到时间线中
- # 设置时间线自动播放
- timeline.add_schema(
- play_interval=1000,
- is_timeline_show=True,
- is_auto_play=True,
- is_loop_play=False
- )
- # 绘图
- timeline.render("1960-2019全球GDP前8国家.html")

第十三章 面向对象
(本章学习的时候,可以思考之前学过的C++和Java语言,很相似)
- # 设计一个类(类比生活中,设计一张登记表)
- class Student:
- name = None # 记录姓名
- gender = None # 记录性别
- nationality = None # 记录国籍
- native_place = None# 记录地区
- age = None # 记录年龄
- # 创建对象(类比打印登记表)
- stu_1 = Student()
- # 对象赋值(类比填表)
- stu_1.name = "老马"
- stu_1.gender = "貌似是男生" # 哈哈哈
- stu_1.nationality = "中国"
- stu_1.native_place = "青海"
- stu_1.age = 25
- # 获取对象之中的信息
- print(stu_1.name)
- print(stu_1.gender)
- print(stu_1.nationality)
- print(stu_1.native_place)
- print(stu_1.age)

1.类的定义

2.成员变量和成员方法

成员方法访问成员变量需要使用self进行调用。
注意事项:


1.定义
__init__()方法,称之为构造方法。
特性:
①在创建类对象(构造类)的时候,会自动执行。
②在创建类对象(构造类)的时候,将传入参数自动传递给__init__方法使用。2.使用案例

注意:
①构造方法名称:__init__ __init__ __init__ , 千万不要忘记init前后都有2个下划线
②构造方法也是成员方法,不要忘记在参数列表中提供:self
__str__方法:改变为输出转变字符串的行为
- class Person:
- def __init__(self,name,age):
- self.name = name
- self.age = age
- # __str__魔术方法
- def __str__(self):
- return f"{self.name}是一个{self.age}的老男人"
- person_1 = Person("老刘",27)
- print(person_1)
- print(str(person_1))

__lt__ 小于符号比较方法:
- class Person:
- def __init__(self,name,age):
- self.name = name
- self.age = age
- # __lt__魔术方法
- def __lt__(self, other):
- return self.age < other.age
- person_1 = Person("老刘",27)
- person_2 = Person("老姚",26)
- print(person_1 < person_2)

__le__ 小于等于比较符号方法:
- class Person:
- def __init__(self,name,age):
- self.name = name
- self.age = age
- # __le__魔术方法
- def __le__(self, other):
- return self.age <= other.age
- person_1 = Person("老刘",27)
- person_2 = Person("老姚",26)
- print(person_1 <= person_2)

__eq__比较运算符实现方法:
- class Person:
- def __init__(self,name,age):
- self.name = name
- self.age = age
- # __eq__魔术方法
- def __eq__(self, other):
- return self.age == other.age
- person_1 = Person("老刘",27)
- person_2 = Person("老姚",26)
- print(person_1 == person_2)
1.定义
封装表示的是,将现实世界事物的属性、行为,封装到类中,描述为 成员变量 成员方法,从而完成程序对现实世界事物的描述
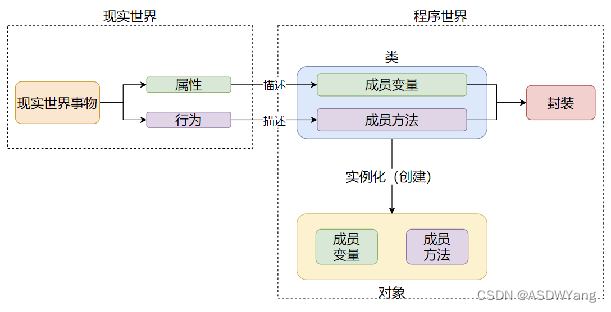
2.私有成员
a.私有成员变量:变量名以__开头(2个下划线)
私有成员方法:方法名以__开头(2个下划线)
b.使用方式

1.格式
单继承

多继承
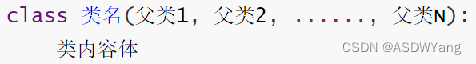
2.单继承

3.多继承


注意:pass的关键字是用来补全语法的
4.多继承的注意事项
多个父类中,如果有同名的成员,那么默认以继承顺序(从左到右)为优先级(先继承的保留,后继承的被覆盖)

5.复写
在子类中重新定义同名的属性或方法即可

6.调用父类同名成员
一旦复写父类成员,那么类对象调用成员的时候,就会调用复写后的新成员
方式1: 调用父类成员
使用成员变量:父类名.成员变量
使用成员方法:父类名.成员方法(self)方式2: 使用super()调用父类成员
使用成员变量:super().成员变量
使用成员方法:super().成员方法()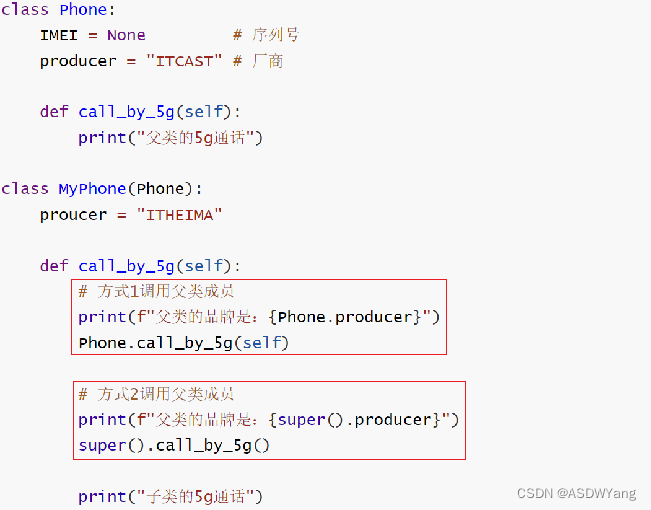
1.变量的类型注解
a.基础语法
变量: 类型




注意:
①元组类型设置类型详细注解,需要将每一个元素都标记出来
②字典类型设置类型详细注解,需要2个类型,第一个是key第二个是valueb.类型注解语法
# type: 类型

类型注解只是一个备注,不会影响程序的执行。
2.函数和方法注解
a.形参注解

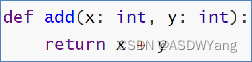
b.返回值注解


3.Union联合类型的注解
Union[类型, ......, 类型]


1.定义
多种状态,即完成某个行为时,使用不同的对象会得到不同的状态

2.抽象类

抽象类:含有抽象方法的类称之为抽象类
抽象方法:方法体是空实现的(pass)称之为抽象方法 -
相关阅读:
binder通信实现
vue 3 第三十五章:集成 tailwind Css
【python】OpenCV—Age and Gender Classification
VIM 编辑文件命令
强制删除文件?正确操作方法分享!
三维种子点生长算法(以及Python递归深度问题)
如何进行销售漏斗管理?
分布式数据库Apache Doris简易体验
vue2 数据响应式原理——数据劫持(对象篇)
探索 SK 示例 -- GitHub 存储库中的机器人
- 原文地址:https://blog.csdn.net/m0_47489229/article/details/134467188
