-
信息检索与数据挖掘 | 【实验】检索评价指标MAP、MRR、NDCG
📚实验内容
- 实现以下指标评价,并对Experiment2的检索结果进行评价
- Mean Average Precision (
MAP) - Mean Reciprocal Rank (
MRR) - Normalized Discounted Cumulative Gain (
NDCG)
- Mean Average Precision (
📚知识梳理
- MAP(Mean Average Precision):平均准确率,是衡量检索结果排序质量的指标。
- 计算方式是对于每个查询,计算被正确检索的文档的
平均精确率,再对所有查询的平均值取均值。 - 存在意义是衡量对于一个查询,检索结果的平均精确率,适用于评估排序结果精确度的情况。
- 计算方式是对于每个查询,计算被正确检索的文档的
- MRR(Mean Reciprocal Rank):平均倒数排名,是衡量检索结果排序质量的指标。
- 计算方式是对于每个查询,计算被正确检索的文档的
最高排名的倒数的平均值,再对所有查询的平均值取均值。 - 存在意义是衡量对于一个查询,检索结果的排名,适用于评估检索结果排序效果好坏的情况。
- 计算方式是对于每个查询,计算被正确检索的文档的
- NDCG(Normalized Discounted Cumulative Gain):归一化折损累积增益,是衡量检索结果排序质量的指标。
- 计算方式是对于每个查询,对每个被检索到的结果计算其
相对于理想排序的增益值,然后对这些相对增益值进行加权求和,再除以理想排序的增益值。 - 存在意义是衡量对于一个查询,检索结果的绝对和相对排序质量,适用于评估排序结果的质量与排名准确度的情况。
- 计算方式是对于每个查询,对每个被检索到的结果计算其
- 这三个指标各有侧重,根据不同的评估需要和数据特征选择合适的指标。例如,对于特定领域的文档检索,可能更关注排名准确度和检索结果的可靠度,因此MRR和NDCG可能比较适合。对于广泛领域的文档检索,可能更关注精确度,因此MAP比较适合。
📚实验步骤
🐇前情提要
- 本次实验是补充式实验,先给出了
qrels_dict和test_dict - 构建
qrels_dict,根据 qrel.txt 中的 query_id 和对应库中真正相关的 doc_id 的信息构建qrels_dict={query_id:{doc_id:gain,doc_id:gain,……}}。 遍历文件中的每一行,完成遍历后,返回 qrels_dict:- 使用 split(’ ') 将行按空格分隔成列表 ele。
- 检查
ele[0](query_id)是否已经在 qrels_dict 中。如果不在,将其作为新的查询ID键添加到 qrels_dict 中,并将其对应的值设置为空字典。 - 检查
ele[3](gain)是否大于0。如果是,将ele[2](doc_id)作为新的相关文档ID键添加到查询ID键对应的值中,并将其对应的值设置为 ele[3] 的整数形式。
def generate_tweetid_gain(file_name): qrels_dict = {} with open(file_name, 'r', errors='ignore') as f: for line in f: # 按空格划分 ele = line.strip().split(' ') # ele[0]中存放的是query_id if ele[0] not in qrels_dict: qrels_dict[ele[0]] = {} # ele[3]存放的是gain,ele[2]存放的是doc_id # 将gain大于0的存入 if int(ele[3]) > 0: qrels_dict[ele[0]][ele[2]] = int(ele[3]) return qrels_dict- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 构建
test_dict,根据 result.txt 文档中 query 和对应的检索到的 doc 文档对应信息构建test_dict={query_id:{doc_id,doc_id,……}}。遍历文件中的每一行,完成遍历后,返回 test_dict:- 使用 split(’ ') 将行按空格分隔成列表 ele。
- 检查
ele[0](query_id)是否已经在 test_dict 中。如果不在,将其作为新的查询ID键添加到 test_dict 中,并将其对应的值设置为一个空列表。 - 将
ele[1](doc_id)添加到查询ID键对应的列表中。
def read_tweetid_test(file_name): # 输入格式为:query_id doc_id test_dict = {} with open(file_name, 'r', errors='ignore') as f: for line in f: # 按空格划分 ele = line.strip().split(' ') # 这里的ele[0]是query_id,ele[1]是doc_id if ele[0] not in test_dict: test_dict[ele[0]] = [] test_dict[ele[0]].append(ele[1]) return test_dict- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
🐇MAP评价指标函数
-
获取检索到的(test_dict)相关文档信息
-
获取库中(qrels_dict)所有相关文档的信息
-
进行 P@K评估计算


-
进行 AP 评估计算

-
进行 MAP 均值评估计算。


def MAP_eval(qrels_dict, test_dict, k = 100): # MAP是对AP评价结果进行平均,AP基于P(Precision@K)评估 AP_result = [] for query in qrels_dict: # 获取相关信息 test_result = test_dict[query] # 检索文档 true_list = set(qrels_dict[query].keys()) # 相关文档 use_length = min(k, len(test_result)) # 用不超过100条文档计算 if use_length <= 0: print('query:', query, '未找到') return [] # 声明变量 P_result = [] total = 0 the_true = 0 # P@K 评估 for doc_id in test_result[0: use_length]: total += 1 if doc_id in true_list: # 如果是相关的 the_true += 1 P_result.append(the_true / total) # AP评估 if P_result: AP = np.sum(P_result) / len(true_list) # print('query:', query, '的AP评估结果:', AP) AP_result.append(AP) else: print('query:', query, ' 就没有相关的┭┮﹏┭┮') AP_result.append(0) # MAP就是AP的平均值 return np.mean(AP_result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
🐇MRR 评价指标函数
-
获取检索到的(test_dict)相关文档信息
-
获取库中(qrels_dict)所有相关文档的信息
-
计算排序倒数(第一个相关结果的位置倒数)
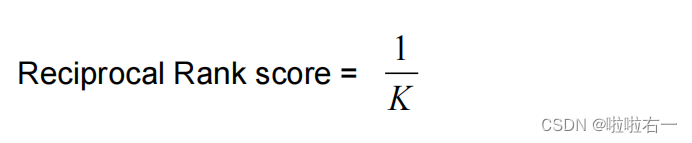
-
进行 RR 评估计算

-
进行 MRR 均值评估计算。


def MRR_eval(qrels_dict, test_dict, k = 100): # MRR是对RR评价结果进行平均,RR基于排序倒数 RR_result = [] for query in qrels_dict: # 获取相关信息 test_result = test_dict[query] # 检索文档 true_list = set(qrels_dict[query].keys()) # 相关文档 use_length = min(k, len(test_result)) # 用不超过100条文档计算 if use_length <= 0: print('query:', query, '未找到') return [] # 声明变量 R_result = [] rank = 0 # 计算排序倒数 for doc_id in test_result[0: use_length]: rank += 1 if doc_id in true_list: R_result.append(1 / rank) break # RR评估 if R_result: RR = np.sum(R_result)/1.0 # print('query:', query, '的RR评估结果:', RR) RR_result.append(RR) else: print('query:', query, ' 就没有相关的┭┮﹏┭┮') RR_result.append(0) # MRR就是RR的平均值 return np.mean(RR_result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
🐇NDCG评价指标函数
- 获取检索到的(test_dict)相关文档信息
- 获取库中(qrels_dict)所有相关文档的gain(也就是下边的rel)信息
- 按gain(rel)倒序排列(理想化,用于计算IDCG)
- 先计算出 DCG和 IDCG,二者相除得到NDCG,取均值后返回。




def NDCG_eval(qrels_dict, test_dict, k = 100): # NDCG@K = DCG@K / IDCG@K # DCG = rel(1) + sum(rel(i)/log(i)) # IDCG就是按rel排序之后的DCG NDCG_result = [] for query in qrels_dict: # 获取相关信息 test_result = test_dict[query] # 检索文档 true_list = list(qrels_dict[query].values()) # 相关文档的gain列表 true_list = sorted(true_list, reverse=True) # 按gain(rel)倒序排列 use_length = min(k, len(test_result),len(true_list)) # 用不超过100条文档计算 if use_length <= 0: print('query:', query, '未找到') return [] # 声明变量 i = 1 DCG = 0.0 IDCG = 0.0 # 计算DCG和IDCG rel1 = qrels_dict[query].get(test_result[0], 0) DCG += rel1 for doc_id in test_result[1: use_length]: i += 1 rel = qrels_dict[query].get(doc_id, 0) DCG += rel / math.log(i, 2) IDCG += true_list[i - 2] / math.log(i, 2) NDCG = DCG / IDCG # print('query:', query, '的NDCG评估结果:', NDCG) NDCG_result.append(NDCG) # 取平均值后返回 return np.mean(NDCG_result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
🐇调试结果

- 实现以下指标评价,并对Experiment2的检索结果进行评价
-
相关阅读:
感应熔炼设备市场现状及未来发展趋势分析
mysql-8.0.31-macos12-x86_64记录
跨平台客户端Blazor方案尝试
交换两个数的值 -- Java实现(加深对引用对象的理解)
在 CentOS 8 上为Apache HTTPD 配置 HTTPS
Blazor前后端框架Known-V1.2.1
Docker从入门到上天系列第二篇:传统虚拟机和容器的对比以及Docker的作用以及所解决的问题
lvs的keepalived
5分钟从掌握到精通---进制转化
创建型设计模式
- 原文地址:https://blog.csdn.net/m0_63398413/article/details/134393293
