-
leetcode刷题 - SQL - 中等
1. 176. 第二高的薪水
筛选出第二大
查询并返回
Employee表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回null(Pandas 则返回 None)。查询结果如下例所示。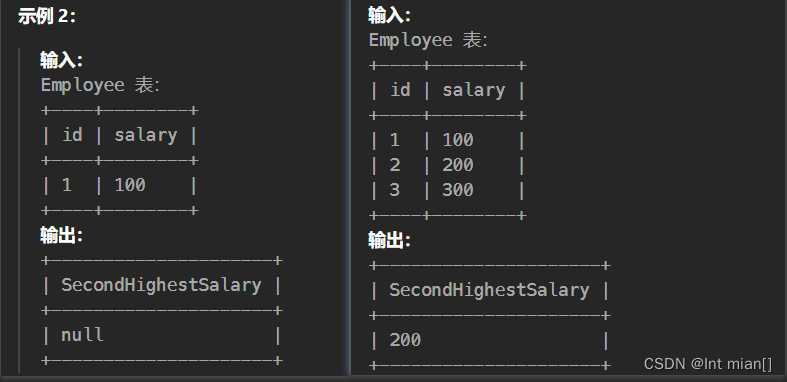
666中等的第一题就上强度
强行解法
- select max(salary) as SecondHighestSalary from Employee
- where salary!=(select max(salary) as salary from Employee);
万一是其他次序的解法,使用limit(看2.)
1.标量子查询,查询为空的时候会填充null
2.
limit n,m等价于limit m offset n,表示跳过开头的n行,返回接下来的m条数据。降序之后的第2条数据就是limit 1,1- SELECT
- ( SELECT DISTINCT Salary FROM Employee
- ORDER BY Salary DESC
- LIMIT 1, 1 ) AS SecondHighestSalary
第三题提供的思路,但是无法实现重复的最大值
- -- 每个部门第一第三高
- SELECT S.NAME, S.EMPLOYEE, S.SALARY
- FROM (SELECT D.NAME,
- T.NAME EMPLOYEE,
- T.SALARY,
- ROW_NUMBER() OVER(PARTITION BY T.DEPARTMENTID ORDER BY T.SALARY DESC) RN
- FROM EMPLOYEE T
- LEFT JOIN DEPARTMENT D
- ON T.DEPARTMENTID = D.ID) S
- WHERE S.RN = 1 OR S.RN = 3
2. 177. 第N高的薪水
写函数
查询
Employee表中第n高的工资。如果没有第n个最高工资,查询结果应该为null。
有点玄学的函数
- CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
- BEGIN
- set n=n-1;
- RETURN (
- SELECT distinct salary FROM Employee ORDER BY salary DESC LIMIT N, 1
- );
- END
3. 178. 分数排名
考察同3.
- select score,
- dense_rank() over(order by score desc) as 'rank' from Scores
4. 180. 连续出现的数字
连续值

- SELECT DISTINCT Num AS ConsecutiveNums FROM Logs
- WHERE (Id+1, Num) IN (SELECT * FROM Logs)
- AND (Id+2, Num) IN (SELECT * FROM Logs)
5. 184. 部门工资最高的员工
多个最大值
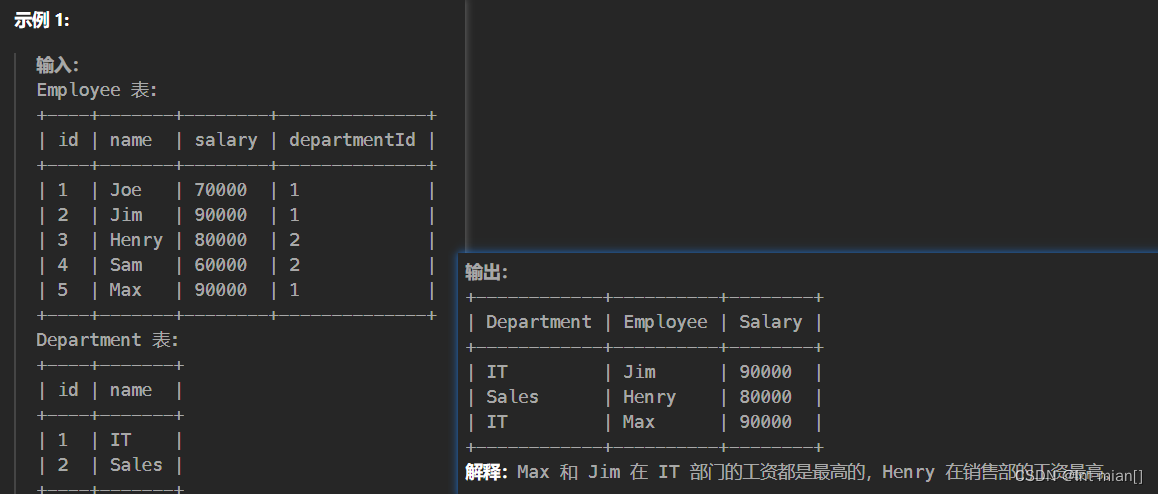
- select d.name as Department, e.name as Employee, e.salary as Salary
- from Employee e left join Department d on e.departmentId = d.id
- where (e.departmentId, e.salary) in (select distinct departmentId, max(salary) from Employee
- group by departmentId)
开窗函数实现
- select Department, Employee, Salary from
- (select d.name Department,
- e.name Employee,
- e.salary Salary,
- rank() over(partition by e.departmentId order by e.salary DESC) rankA
- from Employee e left join Department d on e.departmentId = d.id) ranktbl
- where rankA = 1
over() 一类是聚合开窗函数,一类是排序开窗函数。
调用格式为:函数名(列名) OVER(partition by 列名 order by列名) 。
聚合函数对一组值执行计算并返回单一的值,如sum(),count(),max(),min(), avg()等
常与group by子句连用。除了 COUNT 以外,聚合函数忽略空值
想知道各个地区的前几名、各个班的前几名。这时候需要每一组返回多个值
SQL 标准允许将所有聚合函数用作开窗函数,用OVER 关键字区分开窗函数和聚合函数
开窗函数与聚合函数一样,也是对行集组进行聚合计算
row_number () over()
ROW_NUMBER() OVER(PARTITION BY T.DEPARTMENTID ORDER BY T.SALARY DESC) RN但是这个无法取出重复的最大值
对相等的值不进行区分,其实就是行号,相等的值对应的排名不同,序号从1到n连续。
rank() over():
相等的值排名相同,但若有相等的值,则序号从1到n不连续。如果有两个人都排在第3名,则没有第4名。1233567
dense_rank() over():
对相等的值排名相同,但序号从1到n连续。如果有两个人都排在第一名,1123456
可以看作是把有序的数据集合平均分配到指定的数量n的桶中,将桶号分配给每一行,排序对应的数字为桶号,序号从1到n连续。如果不能平均分配,则较小桶号的桶分配额外的行,并且各个桶中能放的数据条数最多相差1。1111222333444555(放三轮,1桶多一个)
6. 550. 游戏玩法分析 IV
日期计算,查询相互运算
- 示例 1:
- 输入:
- Activity table:
- +-----------+-----------+------------+--------------+
- | player_id | device_id | event_date | games_played |
- +-----------+-----------+------------+--------------+
- | 1 | 2 | 2016-03-01 | 5 |
- | 1 | 2 | 2016-03-02 | 6 |
- | 2 | 3 | 2017-06-25 | 1 |
- | 3 | 1 | 2016-03-02 | 0 |
- | 3 | 4 | 2018-07-03 | 5 |
- +-----------+-----------+------------+--------------+
- 输出:
- +-----------+
- | fraction |
- +-----------+
- | 0.33 |
- +-----------+
- 解释:
- 只有 ID 为 1 的玩家在第一天登录后才重新登录,所以答案是 1/3 = 0.33
- select round(
- (select count(player_id) from Activity -- 算出所有条件玩家数
- where (player_id,event_date-INTERVAL 1 day) in (select player_id,min(event_date) from Activity group by player_id))
- /
- (select count(distinct player_id) from Activity) -- 算出所有玩家数
- ,2) as fraction
7. 570. 至少有5名直接下属的经理
混进来一个简单题
- # Write your MySQL query statement below
- select e1.name from Employee e1 left join Employee e2 on e1.id = e2.managerId
- group by e1.id
- having count(*)>=5
8. 602. 好友申请 II :谁有最多的好友
with用法
- # Write your MySQL query statement below
- with t1 as (
- select requester_id as id1,
- accepter_id as id2
- from RequestAccepted
- union all
- select accepter_id as id1,
- requester_id as id2
- from RequestAccepted
- )
- select id1 as id,
- count(distinct id2) as num
- from t1
- group by 1
- order by 2 desc
- limit 1
9. 608. 树节点
case
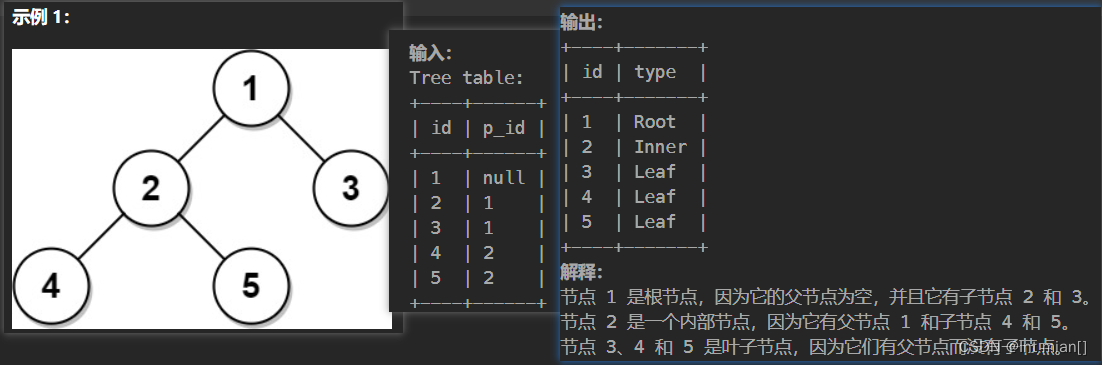
- select
- id,
- case when p_id is null then "Root"
- when id not in (select ifnull(p_id,'s') from Tree) then "Leaf"
- else "Inner"
- end as type
- from
- Tree
-
相关阅读:
计算机毕业设计(附源码)python游戏资讯网站
机器学习基本术语
Mall电商实战项目微服务版本全面升级,支持最新版SpringCloud,权限解决方案升级...
mysql数据库基础
数据结构-----图(graph)的储存和创建
深度学习与总结JVM专辑(四):类文件结构(图文+代码)
【初阶数据结构】深入解析栈:探索底层逻辑
TMS320F280049最小系统原理图
linux03
ALbert语言模型
- 原文地址:https://blog.csdn.net/qq_58551342/article/details/134220058
