-
在Windows 10上安装单机版的hadoop-3.3.5
1、Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以不需要了解分布式底层细节的情况下,开发分布式程序。充分利用集群进行高速运算和存储。
2、下载Hadoop,我们在清华大学的镜像站下载
Index of /apache/hadoop/core/hadoop-3.3.6 (tsinghua.edu.cn)
3、下载之后解压缩
 4、安装相应的环境
4、安装相应的环境4.1、jdk1.8或者jdk11,
4.2、配置hadoop环境


5、修改hadoop配置
5.1、修改start-all.cmd中的配置
- @rem start hdfs daemons if hdfs is present
- if exist %HADOOP_HDFS_HOME%\sbin\start-dfs.cmd (
- call %HADOOP_HDFS_HOME%\sbin\start-dfs.cmd --config %HADOOP_CONF_DIR%
- )
- @rem start yarn daemons if yarn is present
- if exist %HADOOP_YARN_HOME%\sbin\start-yarn.cmd (
- call %HADOOP_YARN_HOME%\sbin\start-yarn.cmd --config %HADOOP_CONF_DIR%
- )
5.2、修改yarn-site.xml
- <configuration>
- <!-- Site specific YARN configuration properties -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>localhost</value>
- </property>
- </configuration>
5.3、mapred-site.xml
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
5.4、hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>/D:/bigdata/hadoop/data/namenode</value> //注意前面部分路径修改为自己的
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>/D:/bigdata/hadoop/data/datanode</value> //注意前面部分路径修改为自己的
- </property>
- <property>
- <name>dfs.permissions.enabled</name>
- <value>false</value>
- </property>
- </configuration>
5.5、core-site.xml
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/D:/bigdata/hadoop/data/tmp</value> //注意前面部分路径修改为自己的
- </property>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- <property>
- <name>hadoop.http.authentication.simple.anonymous.allowed</name>
- <value>true</value>
- </property>
- </configuration>
5.6、需要拷贝winutils下的winutils.exe,hadoop.dll到hadoop的bin下面

在/ect/hadoop/hadoop-env.cmd中设置set JAVA_HOME=D:/Java/jdk1.8.0_311,jdk的环境地址

修改start-yarn.cmd的配置
- setlocal enabledelayedexpansion
- echo starting yarn daemons
- if not defined HADOOP_BIN_PATH (
- rem set HADOOP_BIN_PATH=%~dp0
- set HADOOP_BIN_PATH=%HADOOP_HOME%\bin
- )
- if "%HADOOP_BIN_PATH:~-1%" == "\" (
- set HADOOP_BIN_PATH=%HADOOP_BIN_PATH:~0,-1%
- )
- set DEFAULT_LIBEXEC_DIR=%HADOOP_BIN_PATH%\..\libexec
- if not defined HADOOP_LIBEXEC_DIR (
- set HADOOP_LIBEXEC_DIR=%DEFAULT_LIBEXEC_DIR%
- )
- call %HADOOP_LIBEXEC_DIR%\yarn-config.cmd %*
- if "%1" == "--config" (
- shift
- shift
- )
- @rem start resourceManager
- start "Apache Hadoop Distribution" %HADOOP_HOME%\bin\yarn resourcemanager
- @rem start nodeManager
- start "Apache Hadoop Distribution" %HADOOP_HOME%\bin\yarn nodemanager
- @rem start proxyserver
- @rem start "Apache Hadoop Distribution" %HADOOP_HOME%\yarn proxyserver
- endlocal
5.7、输入hdfs namenode -format格式化
hdfs namenode -format5.8、进入hadoop/sbin目录执行start-all.cmd
- D:\bigdata\hadoop\sbin>start-all.cmd
- This script is Deprecated. Instead use start-dfs.cmd and start-yarn.cmd
- starting yarn daemons

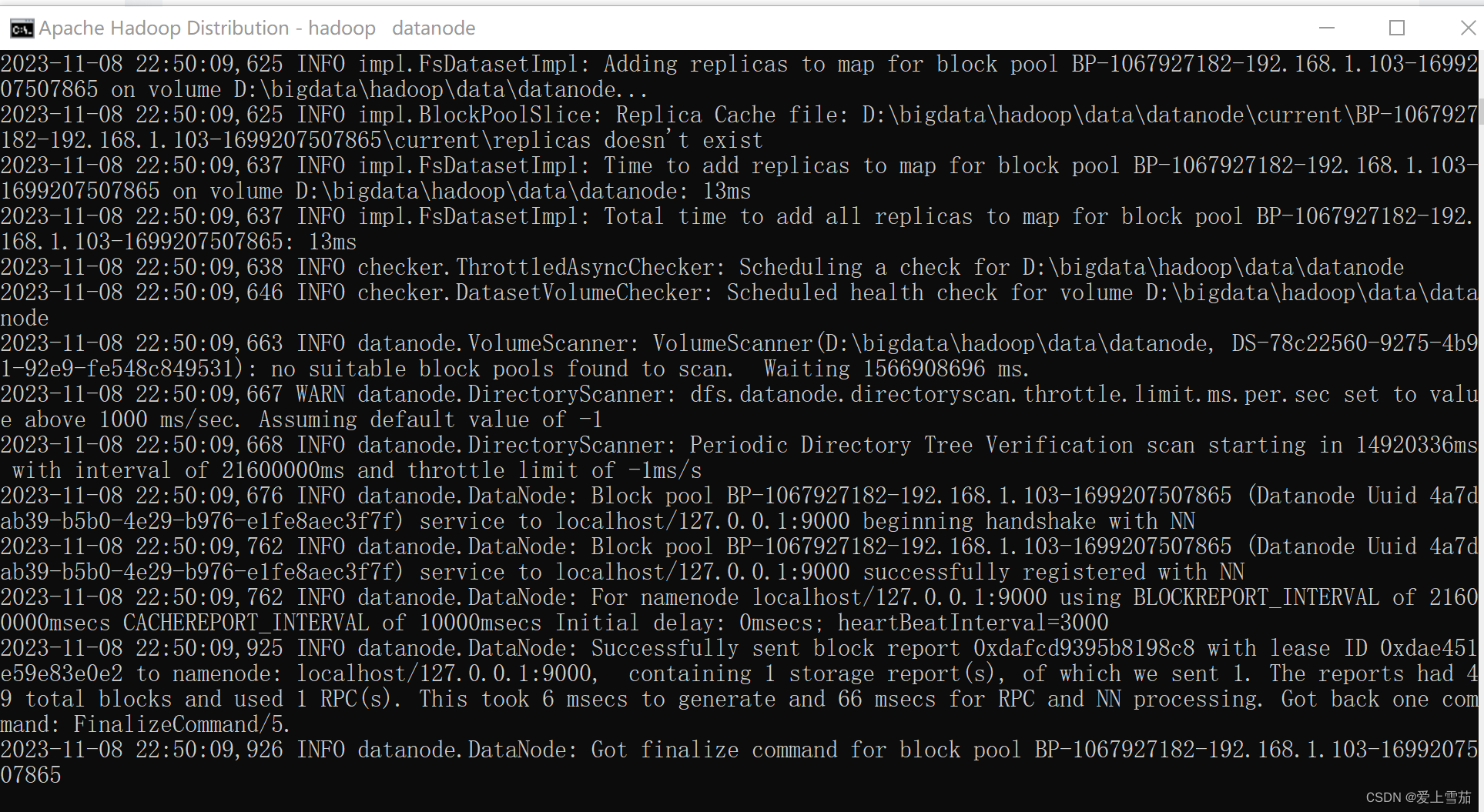

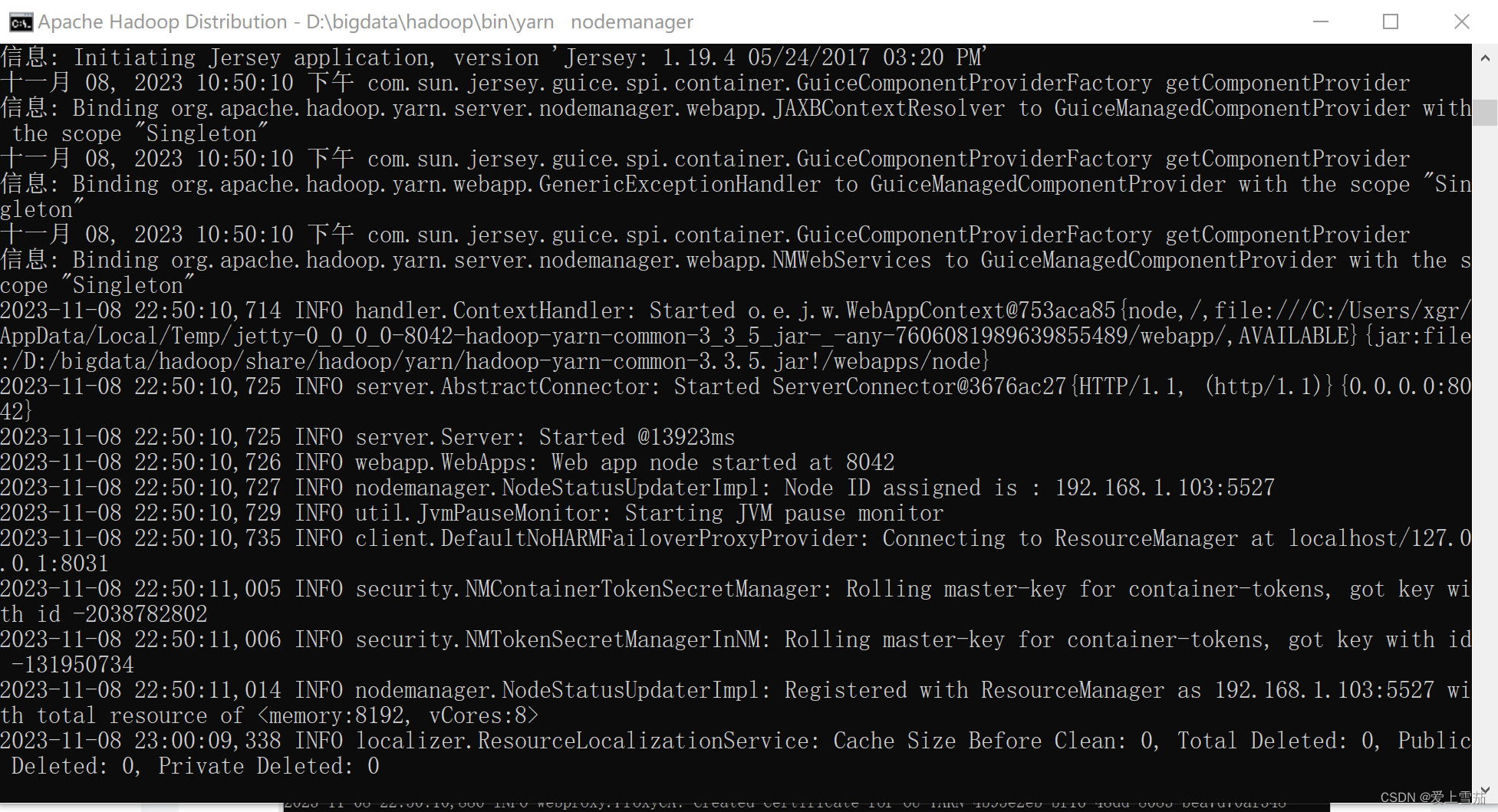
5.9、jps查看
- D:\bigdata\hadoop\sbin>jps
- 8448 Jps
- 28360 NameNode
- 29592 ResourceManager
- 18108 NodeManager
- 20940 DataNode
5.10、启动成功后界面
http://localhost:8088/cluster
http://localhost:9870/

单机版的hadoop就启动成功
-
相关阅读:
在windows和linux上玩转Tensorrt
【Hack The Box】linux练习-- Paper
gitlab-runner 中的 Docker-in-Docker
关于PointHeadBox类的理解
iMazing最新版2.16.1Apple设备管理器功能介绍
.NET Core Web APi类库如何内嵌运行?
java计算机毕业设计期刊在线投稿系统源码+系统+数据库+lw文档+mybatis+运行部署
06-添加用户关注、我的关注列表
数据挖掘经典十大算法_C4.5算法
【leetcode】值和下标之差都在给定的范围内
- 原文地址:https://blog.csdn.net/itorac/article/details/134299995
