-
论文阅读——Detection Hub(cvpr2023)
Detection Hub: Unifying Object Detection Datasets via Query Adaptation on Language Embedding
一、要解决的问题
大规模数据集可以提高模型性能,但是当训练多类别单一模型时,大规模数据集不能用在目标检测任务上,因为两个困难:类别和框标注不一致。就是说,目标检测数据集,没有统一的大规模数据,一来即使类别相似概念每个数据集标注的类别结果可能差别很大,二来每个目标检测数据集只标注了某几个特定的少数的类别,其他的都当成背景了,比如,两个数据集都包含汽车和行人,但是第一个数据集只标注了汽车,那么行人就当成背景了,同理第二个数据集只标注了行人,汽车当背景,这就使得不能在一个模型上同时训练行人和汽车。
本文通过在每个数据集的类别的语言嵌入上调整对象查询解决这个问题。
二、方法
作者设计了一个检测hub,根据不同数据集的分布,动态调整在类别嵌入向量的查询。以前的方法是为所有数据集学习一个联合向量,本文的自适应方法使用文本向量作为类别向量的语义中心,学习不同数据集具体某个类别对这个中心的语义偏差,通过这个方法来解决标注差别。
1、A Naïve Attempt with Language Embedding
首先简单粗暴的把目标类别的名字用语言向量代替。给一张图片N个物体,把所有类别concat,组成prompt:
 ,然后把这个prompt转换成固定长度的语言向量,把这个向量作为初始查询输入到Sparse R-CNN。这个方法对性能有伤害。
,然后把这个prompt转换成固定长度的语言向量,把这个向量作为初始查询输入到Sparse R-CNN。这个方法对性能有伤害。2、Adapting Queries on Language Embedding
只是简单的把类别统一,不能解决标注不连续的问题。所以,作者提出了自适应查询的方法。
1)Detection Hub

首先设计了一个Detection Hub,动态的将查询适应到不同数据集的类别向量上。
初始查询Q,几个数据集向量E,希望Detection Hub能使Q和E交互,从而可以一起训练。

意思应该是,先初始化一个查询Q,然后有一个数据集向量集合E,然后通过交叉注意力,计算给的这个Q和哪个数据集label比较近,输出一个适应过的向量。
2)Query Adaption


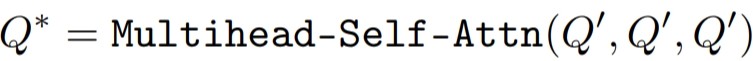
 使用线性层产生动态卷积核
使用线性层产生动态卷积核
3、Unified Multi-dataset Training
语言向量送入bert得到语言特征,再用一个线性层把目标物体特征映射到和语言特征一样的同一个视觉语言空间,然后点乘计算相似度。即把分类问题作为单词-区域对齐问题。


-
相关阅读:
一篇博客学会系列(2)—— C语言中的自定义类型 :结构体、位段、枚举、联合体
Diffusion Model 相关文章(图像生成方面)
Centos7使用Nginx配置HTTPS正向代理
go recover
springboot jpa 返回自定义非实体VO类
消息中间件
深入了解Spring Boot Actuator
HackTheBox---Starting Point-- Tier 0---Meow
ke9案例三:页面提交文件,我服务器端接收
技术速递|宣布为 .NET 升级助手提供第三方 API 和包映射支持
- 原文地址:https://blog.csdn.net/weixin_43575791/article/details/134291693