-
Navicat的使用--mysql
表关系
数据库的操作,表字段的设计,一般都由于图形化界面工具Navicat完成。
而表中数据的增删改查,需要熟悉sql语句。一对一
一对一:一个A对应一个B,一个B对应一个A
- 将A或B任意一张表的主键设置为外键
一对多
一对多:一个A对应多个B,一个B对应一个A。称A和B是一对多,B和A时多对一
- 在多的一端设置外键,对应到另一张表的主键
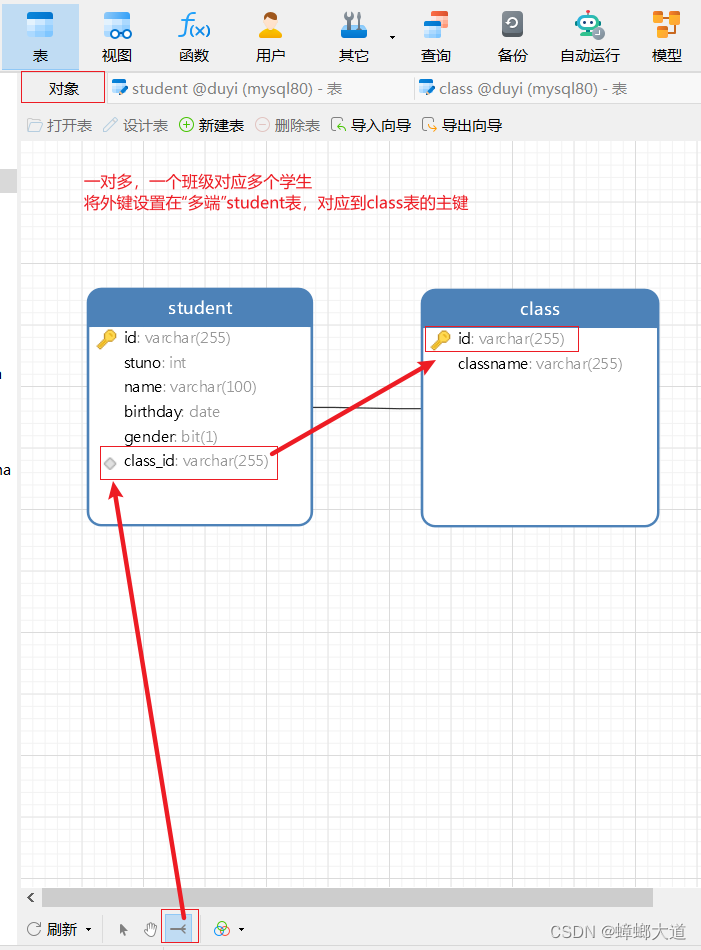
添加完成:

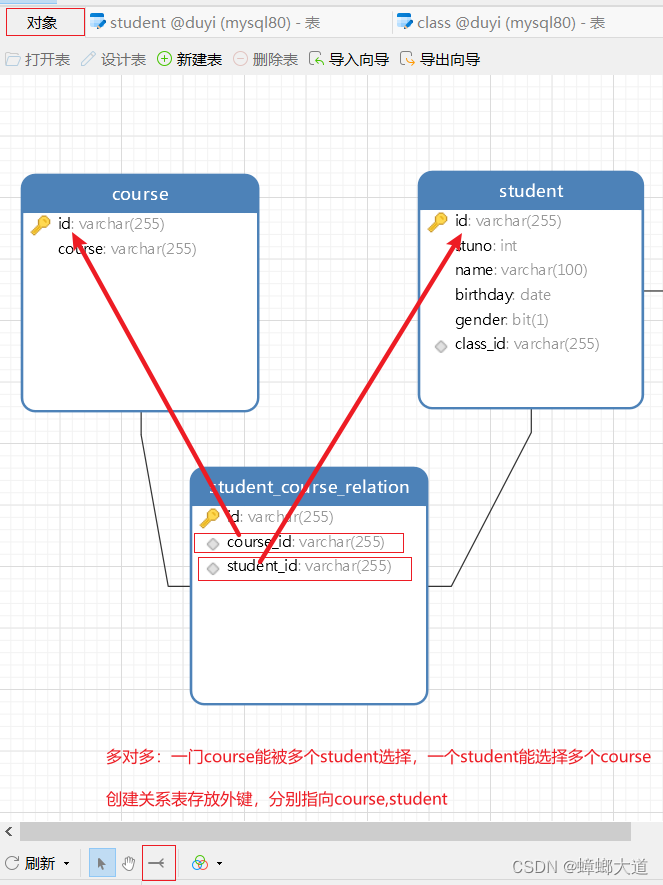
多对多
多对多:一个A对应多个B,一个B对应多个A
- 新建一张关系表,关系表至少包含两个外键,分别对应到A,B
数据的增删改查
增删改
-- 1.增加数据 INSERT INTO `user` ( `name`, `age`) VALUES ('cjc', 100); INSERT INTO `user` ( `name`, `age`) VALUES ('ccc', 999); INSERT INTO `user` ( `name`, `age`) VALUES ('aaa', 111); -- 2.删除数据 -- 删除所有数据 DELETE FROM `user` DELETE FROM `user` WHERE `name` = 'aaa' -- 3.修改数据 UPDATE `user` SET `name` = 'CJC',`age` = 10000 WHERE `name` = 'cjc' -- 修改数据时,手动加上时间的更新 UPDATE `user` SET `name` = 'CCC',`age` = 99999,`updateTime` = CURRENT_TIMESTAMP WHERE `name` = 'ccc' -- 修改了数据,根据当前时间戳更新updateTime ALTER TABLE `user` ADD `updateTime` TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
单表查询
select…from…
-- 额外的一列 SELECT id, loginid, loginpwd, 'abc' as '额外的一列' from `user`; -- 列名重命名 as SELECT *, 'abc' as 'extra' from `employee`; -- 将1/0映射为'男'/'女' -- 新增一列level,值为 高/中/低 SELECT id, `name`, case when ismale = 1 then '男' else '女' end sex, case when salary>=10000 then '高' when salary>=5000 then '中' else '低' end `level`, salary FROM employee; -- DISTINCT去重 select DISTINCT location from employee;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
where
SELECT * FROM employee WHERE ismale = 1; -- companyId = 1 or companyId = 2 SELECT * FROM department WHERE companyId in (1, 2); -- null SELECT * from employee WHERE location is not null; SELECT * from employee WHERE location is null; -- between...and -- > >= < <= SELECT * from employee WHERE salary>=10000; SELECT * from employee WHERE salary BETWEEN 10000 and 12000; -- like模糊查询 -- %任意字符0个或多个 _任意字符1个 SELECT * from employee WHERE `name` like '%曹%'; -- 第二个字符为c SELECT * from employee WHERE `name` like '_c'; -- and or SELECT * from employee WHERE `name` like '张%' and ismale=0 and salary>=12000; SELECT * from employee WHERE `name` like '张%' and (ismale=0 and salary>=12000 or birthday>='1996-1-1');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
order by
-- 按照gender升序, -- 性别相同,则再按照salary降序 SELECT * from employee ORDER BY gender asc, salary desc;- 1
- 2
- 3
- 4
limit
-- 跳过1条数据后,查询前20条数据 SELECT * FROM `user` LIMIT 20 OFFSET 1 SELECT * FROM `user` LIMIT 1,20 -- 查询第3页,每页5条数据 -- 分页公式 limit (curPage-1)*pageSize, pageSize SELECT * FROM `user` LIMIT 10,5- 1
- 2
- 3
- 4
- 5
- 6
函数与分组
1.聚合函数
-- 数学函数 SELECT ABS(-1); SELECT CEIL(1.4); SELECT ROUND(3.1415926, 3); SELECT TRUNCATE(3.1415926,3); -- 字符串函数 SELECT CURDATE(); SELECT CURTIME(); SELECT TIMESTAMPDIFF(DAY,'2010-1-1 11:11:11','2010-1-2 11:11:12'); -- 聚合函数 SELECT count(id) as 员工数量, avg(salary) as 平均薪资, sum(salary) as 总薪资, min(salary) as 最小薪资 FROM employee;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2.分组group by
分组只能查询分组的列或聚合列-- 查询员工分布的居住地,以及每个居住地有多少名员工 SELECT location, count(id) as empnumber FROM employee GROUP BY location -- 将居住地和性别都相同的分为一组 SELECT location, count(id) as empnumber FROM employee GROUP BY location,gender- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
多表查询
-- 1.笛卡尔积 -- a表m行记录,b表n行记录,笛卡尔积运算得m*n行记录 -- 查询出足球队的对阵表 SELECT t1.name 主场, t2.name 客场 FROM team as t1, team as t2 WHERE t1.id != t2.id; -- 2.左外连接 SELECT * from department as d left join employee as e on d.id = e.deptId; -- 3.右外连接 SELECT * from employee as e right join department as d on d.id = e.deptId; -- 4.内连接 SELECT e.`name` as empname, d.`name` as dptname, c.`name` as companyname from employee as e inner join department as d on d.id = e.deptId inner join company c on d.companyId = c.id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
sql书写顺序、执行顺序
书写顺序
SELECT tagname as "tag1", tagname2 as "tag2", [聚合函数]... FROM table1 [LEFT] JOIN table2 on xxx [LEFT] JOIN table3 on xxx WHERE 不含聚合函数的条件 GROUP BY tag1,tag2...等所有非聚合函数字段 HAVING 含聚合函数的条件 ORDER BY tag1,tag2 DESC LIMIT [偏移量],显示的记录数; # LIMIT 显示的记录数 OFFSET 偏移量;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
执行顺序
- from
- join…on…
- where
- group by
- select
- having
- order by
- limit
sql查询语句练习
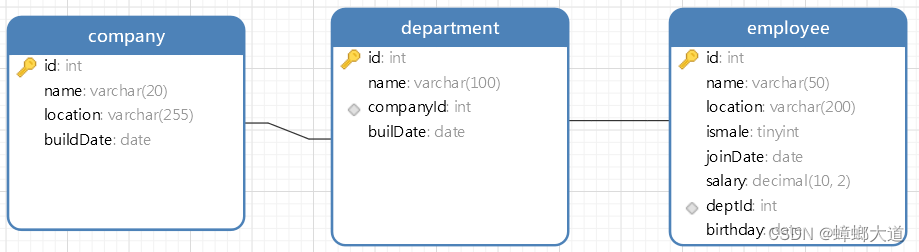
-- 三表连接 SELECT * from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on d.companyId = c.id- 1
- 2
- 3
- 4
- 5
- 6
- 7
-- 1. 查询渡一每个部门的员工数量 SELECT COUNT(e.id),d.`name` from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on d.companyId = c.id WHERE c.`name` LIKE '%渡一%' GROUP BY d.id -- 2. 查询每个公司的员工数量 SELECT COUNT(e.id),c.`name` from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on d.companyId = c.id GROUP BY c.id -- 3. 查询所有公司10年内入职的居住在万家湾的女员工数量 -- 注意:所有公司都要显示 SELECT c.id,c.`name`,res.count from company c LEFT JOIN ( SELECT c.id,c.`name`,COUNT(e.id) count from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on d.companyId = c.id WHERE TIMESTAMPDIFF(YEAR,e.joinDate,CURDATE())<=10 AND e.location LIKE '%万家湾%' GROUP BY c.id ) as res on c.id = res.id -- 4. 查询渡一所有员工分布在哪些居住地,每个居住地的数量 SELECT e.location,COUNT(e.id) from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on d.companyId = c.id WHERE c.`name` LIKE '%渡一%' GROUP BY e.location -- 5. 查询员工人数大于200的公司信息 SELECT * from company c WHERE c.id = ( -- 查找到符合条件的公司id SELECT c.id from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on d.companyId = c.id GROUP BY c.id HAVING count(e.id)>200 ) -- 6. 查询渡一公司里比它平均工资高的员工 SELECT e.* from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on c.id = d.companyId WHERE c.`name` LIKE '%渡一%' AND e.salary > ( -- 渡一的平均薪资 SELECT AVG(e.salary) from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on d.companyId = c.id WHERE c.`name` LIKE '%渡一%' ) -- 7. 查询渡一所有名字为两个字和三个字的员工对应人数 SELECT CHARACTER_LENGTH(e.`name`) nameLen, COUNT(e.id) from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on c.id = d.companyId WHERE c.`name` LIKE '%渡一%' GROUP BY CHARACTER_LENGTH(e.`name`) HAVING nameLen in (2,3) -- 8. 查询每个公司每个月的总支出薪水,并按照从低到高排序 SELECT c.`name`,sum(e.salary) totalSalary from employee e INNER JOIN department d on d.id = e.deptId INNER JOIN company c on d.companyId = c.id GROUP BY c.id ORDER BY totalSalary desc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
视图
我们可以把重复使用的查询封装成视图
mysql驱动程序
mysql驱动程序:连接mysql的数据和内存中的数据
常用mysql驱动程序:mysql,mysql2const mysql = require('mysql2') // 1.创建连接池 const connectionPool = mysql.createPool({ host: 'localhost', port: 13306, user: 'root', password: 'root', database: 'koa-apis', connectionLimit: 5 }) // 2.测试是否连接成功 connectionPool.getConnection((err, connection) => { if (err) { console.log('数据库连接失败', err); return } connection.connect(err => { if (err) { console.log('和数据库交互失败', err); } else { console.log('和数据库交互成功'); } }) }) // 3.定义预处理语句 // 防止sql注入 const statement = 'SELECT * FROM `student` WHERE id > ? AND name LIKE ?' // 4.执行sql语句 // 使用promise语法 const connection = connectionPool.promise() connection.execute(statement, [2, '%c%']).then(res => { const [val, fields] = res console.log(val); }).catch(err => { console.log(err); })- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
ORM
ORM(Object Relational Mapping)对象关系映射
- 将程序中的对象和数据库关联
- 使用统一的接口,完成对不用数据库的操作
node中常用ORM框架
- Sequelize
- TypeORM
连接到数据库
const { Sequelize } = require('sequelize'); const sequelize = new Sequelize('school', 'root', 'root', { host: 'localhost', dialect: 'mysql', port: '13306', logging: false // 关闭打印日志 }); // 测试连通性 (async function () { try { await sequelize.authenticate(); console.log('Connection has been established successfully.'); } catch (error) { console.error('Unable to connect to the database:', error); } })(); module.exports = sequelize- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
模型定义和同步
const sequelize = require('./db'); const { DataTypes } = require('sequelize'); const Admin = sequelize.define('Admin', { // 在这里定义模型属性 loginId: { type: DataTypes.STRING, allowNull: false }, loginPwd: { type: DataTypes.STRING, allowNull: false }, name: { type: DataTypes.STRING, allowNull: false } }, { createdAt: true, updatedAt: true, paranoid: true, // 记录删除的时间,不会真正删除数据 freezeTableName: false // 表名是否添加复数 }); (async function () { await Admin.sync({ alter: true }) console.log('Admin 同步完成'); })(); module.exports = Admin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
表关系(外键)
1.一对一
A.hasOne(B) 关联意味着 A 和 B 之间存在一对一的关系,外键在目标模型(B)中定义.
A.belongsTo(B)关联意味着 A 和 B 之间存在一对一的关系,外键在源模型中定义(A).2.一对多
A.hasMany(B) 关联意味着 A 和 B 之间存在一对多关系,外键在目标模型(B)中定义.3.多对多
A.belongsToMany(B, { through: ‘C’ }) 关联意味着将表 C 用作联结表,在 A 和 B 之间存在多对多关系. 具有外键(例如,aId 和 bId)三层架构

增删改查
bookService.js
const Book = require("../models/Book"); // 1.增 exports.addBook = async function (obj) { // 业务逻辑判断 // ... const ins = await Book.create(obj); return ins.toJSON(); }; // 2.删 exports.deleteBook = async function (id) { const result = await Book.destroy({ where: { id, }, }); return result; }; // 3.改 exports.updateBook = async function (id, obj) { const result = await Book.update(obj, { where: { id, }, }); return result; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
数据的导入导出
通过后缀名为.sql的文件,导入导出数据
导入sql文件
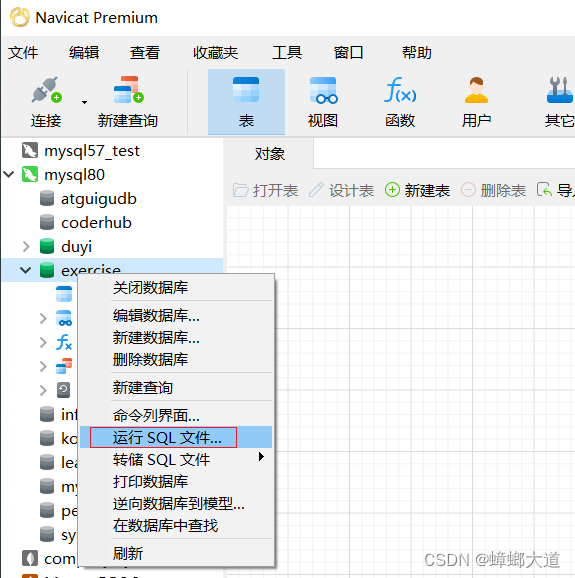
导出sql文件

-
相关阅读:
Leetcode:正则表达式匹配
带SLCD屏驱动的低功耗单片机MM32L0130
【Android】NDK开发Crash分析
深入解析spring boot配置加载原理,配置文件的加载顺序是怎么实现的?
完美解决docker skywalking报错:no provider found for module storage
iTOP-3568开发板Ubuntu下安装ADB工具
秒杀系统(1)——秒杀功能设计理念
Prometheus + Grafana 搭建监控仪表盘
mongodb安装及使用
伪类应用——
- 原文地址:https://blog.csdn.net/qq_43551056/article/details/134276072
