-
【C++项目】高并发内存池第三讲PageCache框架涉及+核心实现(上)

项目源代码:高并发内存池
1. PageCache框架设计
1.1整体设计
回顾:
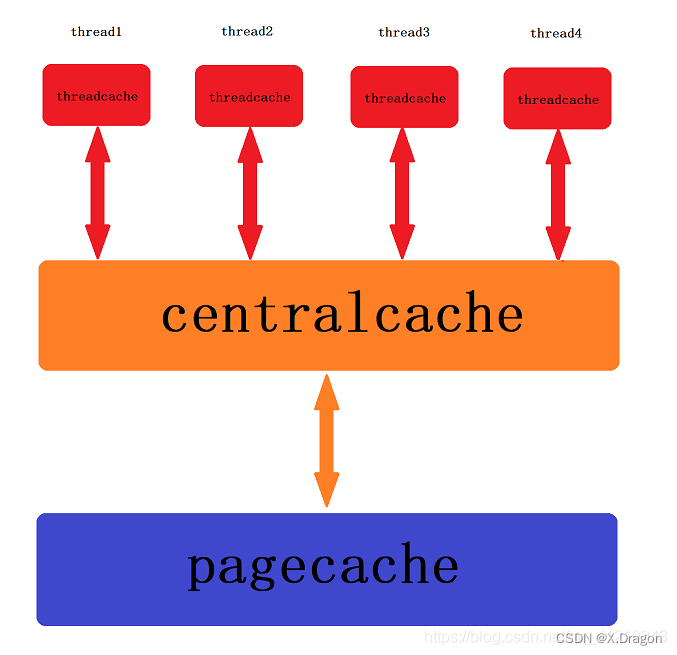
如图所示 内存申请的过程是逐步往下的,从ThreadCache—>CentralCache—>PageCache,内存不足时依次找下一级申请。- PageCache结构逻辑图:
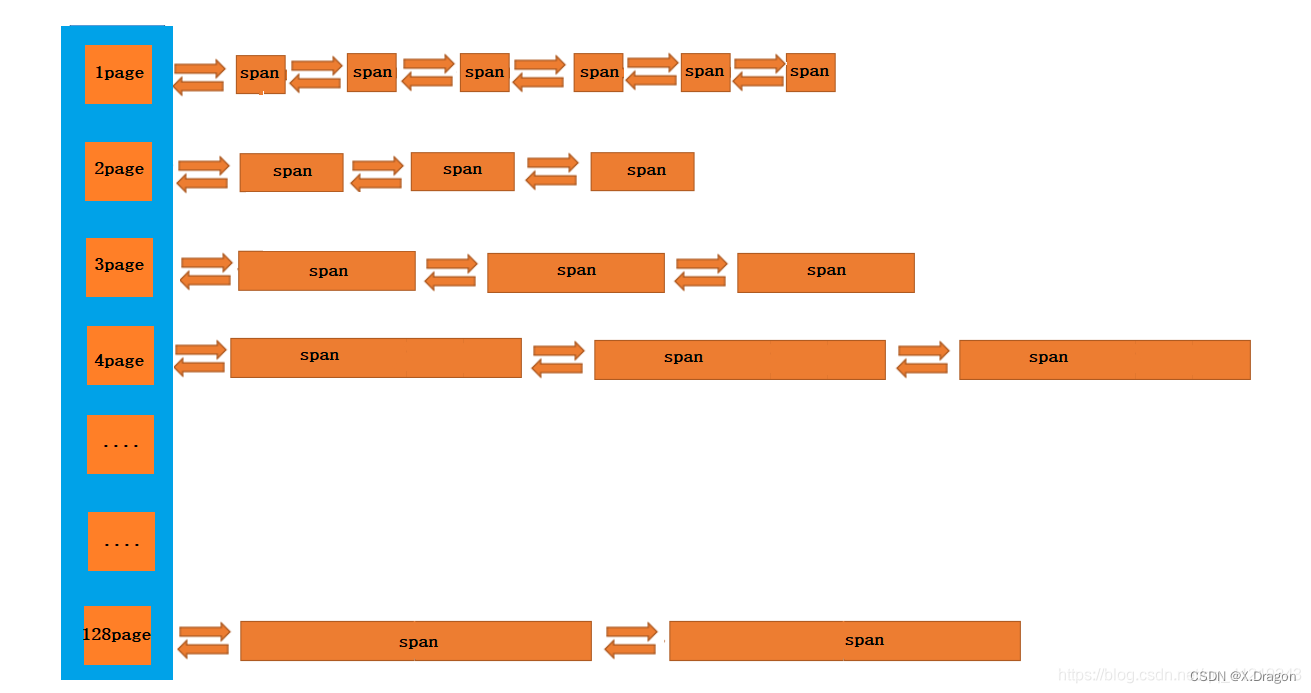
一样是一个哈希桶结构,只不过不同的是,上面是一个双向带头的循环链表,每个链表挂的是一个个大块内存块span
而且下标映射规则:1–128每个桶上挂的大块内存大小和下标相匹配,例如:一号桶 每个span的大下是1page,2号桶是2page依次类推…
1.2CentralCache向PageCache申请内存的逻辑设计
当CentralCache向PageCache申请内存时首先会计算出对应的pageid然后根据pageid去对应的桶获取一个span,当对应的桶没有对象时,会逐步往下一个桶遍历寻找空闲的span。举例说明:当申请一个2页的内存时,首先会去PageCache中下标为2的桶去寻找空闲的span,该桶有空闲的span就直接返回给上一级;如果没有就会往下一个桶也就是下标为3 的桶寻找,此时找到了空闲的span,但是其大小为3页,这时就要进行切分:把页切分成2页+1页,2页给上级对象返回,剩余的1页则根据映射规则挂到下标为1的桶,留着下次对象申请调用。
相关实现代码:
//获取一个K页的span Span* PageCache::Newspan(size_t k) { assert(k > 0); //大于128页的就直接向堆中申请 if (k > NPAGES - 1) { // void* ptr = SystemAlloc(k); Span* span = pageCache->_spanPool.New(); span->_page_id = (PAGE_ID)ptr >> PAGE_SHIFT; span->_n = k; pageCache->_idSpanMap.set(span->_page_id, span); return span; } //先检查第K个桶里面有没有span if (! pageCache->_spanList[k].Empty()) { Span* kSpan = pageCache->_spanList[k].PopFront(); for (PAGE_ID i = 0; i < kSpan->_n; i++) { pageCache->_idSpanMap.set(kSpan->_page_id + i, kSpan); } return kSpan; } //第K个桶是空的 检查一下后面的桶里面有没有span for (size_t i = k + 1; i < NPAGES; i++) { if (!pageCache->_spanList[i].Empty()) { Span* nspan = pageCache->_spanList[i].PopFront(); Span* kspan= pageCache->_spanPool.New(); //在nspan头部切一个k页下来 //k页的span返给centralcache剩下的挂在对应的映射位置上 kspan->_page_id = nspan->_page_id; kspan->_n = k; nspan->_page_id += k; nspan->_n -= k; pageCache->_spanList[nspan->_n].PushFront(nspan); //存储nSpan的首位页号跟nspan映射 //存储nSapn的首位页号跟nspan映射 //方便page cache回收内存时,进行合并查找 //_idSpanMap[nSpan->_pageId] = nSpan; pageCache->_idSpanMap.set(nspan->_page_id, nspan); //_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan; pageCache->_idSpanMap.set(nspan->_page_id + nspan->_n - 1, nspan); //建立id和span的映射,方便central cache回收小块内存时,查找对应的span for (PAGE_ID i = 0; i < kspan->_n; ++i) { //_idSpanMap[kSpan->_pageId + i] = kSpan; pageCache->_idSpanMap.set(kspan->_page_id + i, kspan); } return kspan; } } //走到这个位置,后面没有大页的span //这时候就去找堆要一个128的span //Span* bigSpan = new Span; Span* bigSpan = pageCache->_spanPool.New(); void* ptr = SystemAlloc(NPAGES - 1); bigSpan->_page_id = (PAGE_ID)ptr >> PAGE_SHIFT; bigSpan->_n = NPAGES - 1; pageCache->_spanList[bigSpan->_n].PushFront(bigSpan); return Newspan(k); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
2.PageCache的核心框架实现
一样用的是单例模式–>饿汉模式 其优点在上一篇博客已经详细介绍
- PageCache.h
#pragma once #include "Common.h" #include"ObjectPool.h" #include"PageMap.h" class PageCache { public: static PageCache* GetInstance() { return &_sInst; } Span* MapObjectToSpan(void* obj); //获取一个K页的span static Span* Newspan(size_t); std::mutex _pageMtx; void ReleaseSpanToPageCache(Span* span); private: //禁构造和拷贝构造 PageCache() {}; PageCache(const PageCache& p) = delete; ObjectPool<Span> _spanPool; SpanList _spanList[NPAGES]; PageCache& operator=(const PageCache&) = delete; static PageCache _sInst; TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- PageCache.cpp
#define _CRT_SECURE_NO_WARNINGS #include"PageCache.h" PageCache PageCache::_sInst; PageCache* pageCache = PageCache::GetInstance(); // 获取 PageCache 的单例对象 //获取一个K页的span Span* PageCache::Newspan(size_t k) { assert(k > 0); //大于128页的就直接向堆中申请 if (k > NPAGES - 1) { // void* ptr = SystemAlloc(k); Span* span = pageCache->_spanPool.New(); span->_page_id = (PAGE_ID)ptr >> PAGE_SHIFT; span->_n = k; pageCache->_idSpanMap.set(span->_page_id, span); return span; } //先检查第K个桶里面有没有span if (! pageCache->_spanList[k].Empty()) { Span* kSpan = pageCache->_spanList[k].PopFront(); for (PAGE_ID i = 0; i < kSpan->_n; i++) { pageCache->_idSpanMap.set(kSpan->_page_id + i, kSpan); } return kSpan; } //第K个桶是空的 检查一下后面的桶里面有没有span for (size_t i = k + 1; i < NPAGES; i++) { if (!pageCache->_spanList[i].Empty()) { Span* nspan = pageCache->_spanList[i].PopFront(); Span* kspan= pageCache->_spanPool.New(); //在nspan头部切一个k页下来 //k页的span返给centralcache剩下的挂在对应的映射位置上 kspan->_page_id = nspan->_page_id; kspan->_n = k; nspan->_page_id += k; nspan->_n -= k; pageCache->_spanList[nspan->_n].PushFront(nspan); //存储nSpan的首位页号跟nspan映射 //存储nSapn的首位页号跟nspan映射 //方便page cache回收内存时,进行合并查找 //_idSpanMap[nSpan->_pageId] = nSpan; pageCache->_idSpanMap.set(nspan->_page_id, nspan); //_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan; pageCache->_idSpanMap.set(nspan->_page_id + nspan->_n - 1, nspan); //建立id和span的映射,方便central cache回收小块内存时,查找对应的span for (PAGE_ID i = 0; i < kspan->_n; ++i) { //_idSpanMap[kSpan->_pageId + i] = kSpan; pageCache->_idSpanMap.set(kspan->_page_id + i, kspan); } return kspan; } } //走到这个位置,后面没有大页的span //这时候就去找堆要一个128的span //Span* bigSpan = new Span; Span* bigSpan = pageCache->_spanPool.New(); void* ptr = SystemAlloc(NPAGES - 1); bigSpan->_page_id = (PAGE_ID)ptr >> PAGE_SHIFT; bigSpan->_n = NPAGES - 1; pageCache->_spanList[bigSpan->_n].PushFront(bigSpan); return Newspan(k); } Span* PageCache::MapObjectToSpan(void* obj) { PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT); //std::unique_lock- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
这里着重介绍一下CentralCache向PageCache申请内存的过程:
- GetOneSpan
Span* GetOneSpance(SpanList& list, size_t size) { //查看一下当前spanlists是否span未分配的 Span* it = list.Begin(); while (it != list.End()) { if (it->_freeList!=nullptr) { return it; } else { it = it->_next; } } //先把centralCache的桶解掉 ,这样如果其他的线程释放对象回来,不会阻塞 list._mtx.unlock(); //走到这里说明没有空闲的span了,再往下找PageCache要 PageCache::GetInstance()->_pageMtx.lock(); //加锁 这是一个大锁 Span* span = PageCache::Newspan(SizeClass::NumMovePage(size)); span->_isUse = true; span->_objSize = size; PageCache::GetInstance()->_pageMtx.unlock();//到这一步程序就已经申请到一个span了 //对span进行切分 此过程不需要加锁 因为其他的线程访问不到这个span //通过页号 计算出起始页的地址 add=_pageID<- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
-
首先,代码通过 ‘list.Begin()’ 获取 ‘SpanList’ 中第一个 ‘Span’(链表头)的迭代器 ‘it’,然后遍历 ‘SpanList’。对于每个 ‘Span’,它检查 ‘_freeList’ 是否为空。如果 ‘_freeList’ 不为空,表示这个 ‘Span’ 中还有未分配的内存块,于是返回这个 ‘Span’,以便分配内存。如果 ‘_freeList’ 为空,表示这个 ‘Span’ 已分配完,于是继续遍历下一个 ‘Span’。
-
如果遍历完所有 ‘Span’ 后仍未找到可用的 ‘Span’,则说明没有足够的可用内存。此时,代码会解锁当前的 ‘list’,这个操作可以防止其他线程在等待可用内存时被阻塞。
-
然后,代码进入 PageCache 部分,通过 ‘PageCache::GetInstance()’ 获取 ‘PageCache’ 的单例对象,再对 ‘PageCache’ 进行加锁(‘PageCache::_pageMtx’)。这个锁用来保证只有一个线程能够执行下面的操作,以避免竞态条件。
-
代码通过 ‘PageCache::Newspan(SizeClass::NumMovePage(size))’ 创建一个新的 ‘Span’,这个 ‘Span’ 将用于进一步的内存分配。然后,标记这个 ‘Span’ 为正在使用(‘span->_isUse = true’)。
-
接下来,计算该 ‘Span’ 的大块内存的起始地址 ‘start’ 和大小 ‘bytes’。大块内存的大小由 ‘_n’ 字段乘以 ‘PAGE_SHIFT’ 决定。
-
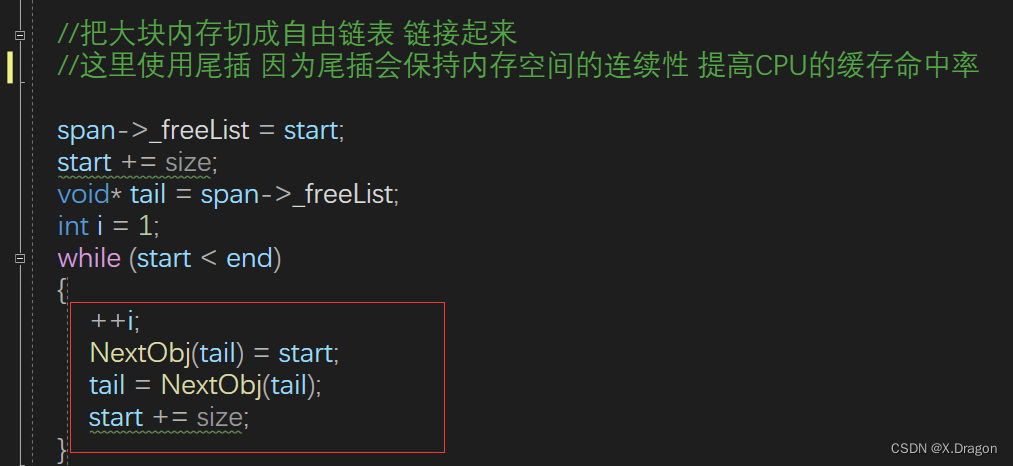
接下来,将大块内存切分成小块,这些小块将成为自由链表的一部分。切分的过程是通过将内存地址链接起来来实现的。这里使用了尾插法,以确保内存块的连续性,提高 CPU 缓存的利用率。
-
将 ‘Span’ 的 ‘_freeList’ 指针指向自由链表的头部,然后将自由链表中每个内存块通过 ‘NextObj’ 连接起来。最后,将最后一个内存块的 ‘NextObj’ 指针设置为 ‘nullptr’,表示自由链表的结束。
-
最后,代码将新创建的 ‘Span’ 加锁并插入到 ‘list’ 的头部,以保证其被其他线程看到。然后解锁 ‘list’,以允许其他线程继续分配内存。
总的来说,这段代码用于从 ‘SpanList’ 或者 ‘PageCache’ 中获取一个 ‘Span’ 用于内存分配。如果 ‘SpanList’ 中没有可用的 ‘Span’,则会通过 ‘PageCache’ 创建新的 ‘Span’,再将其切分为小块内存,用于后续的对象分配。这个策略保证了内存分配的高效性,尤其在多线程环境下。
- 把大块内存切分成自由链表
-
首先,通过 ‘span->_page_id’ 计算出大块内存的起始地址 ‘start’。‘span->_page_id’ 存储了页号,而 ‘PAGE_SHIFT’ 是一个位移常量,用于将页号左移得到实际的内存地址。这样,‘start’ 指向了大块内存的起始地址

start+=size,往后挪了一个单位,然后依次链接 -
接下来,通过 ‘span->_n’ 计算出大块内存的总大小 ‘bytes’。同样,‘span->_n’ 表示了内存块的数量,乘以 ‘PAGE_SHIFT’ 得到总的字节数。
-
然后,定义一个指针 ‘end’,它指向大块内存的结束地址。这是通过将 ‘start’ 和 ‘bytes’ 相加得到的,确定了大块内存的范围。
-
设置 ‘span->_freeList’ 指向 ‘start’,表示自由链表的头部。这时链表还为空,所以 ‘start’ 就是链表的唯一节点。
-
接下来,使用 ‘while’ 循环遍历大块内存的地址范围,从 ‘start’ 开始,直到 ‘start’ 指向了 ‘end’ 为止。
-
在循环中,每次迭代都会将下一个内存块的地址(‘start’)链接到当前内存块的末尾(通过 ‘NextObj(tail) = start’)。‘tail’ 指向当前内存块的末尾,所以这里设置 ‘NextObj(tail)’ 会连接到下一个内存块。然后,‘tail’ 移动到下一个内存块的末尾。
-
同时,‘start’ 也向后移动一个内存块的大小(‘start += size’),以准备链接下一个内存块。
-
循环结束后,大块内存已经被切分成多个小块,并且这些小块通过 ‘NextObj’ 链接在一起,形成了一个自由链表。
总之,这段代码通过计算大块内存的起始地址和总大小,然后使用循环将这个大块内存切分成多个小块,并通过自由链表链接在一起。这个自由链表将用于对象的内存分配,保证了内存的高效使用。

点赞支持持续更新

- PageCache结构逻辑图:
-
相关阅读:
记一次 Android 周期性句柄泄漏的排查
Mac 解决command not find : maven
C++对象模型(12)-- 构造函数语义学:构造函数
猴赛雷 ! 上次我见过这么厉害的安全测试实战演练还是上次!
uni-app 分包
Postman接口Mock Server服务器设置
递归、搜索与回溯算法:综合练习
深度学习基础知识 Dataset 与 DataLoade的用法解析
洛必达法则讲解和例题
C++读取注册表
- 原文地址:https://blog.csdn.net/weixin_62892290/article/details/133990719
