-
ES8生产实践——pod日志采集(ELK方案)
ELK方案采集介绍
方案简介
面对大规模集群海量日志采集需求时,filebeat相较于fluent bit拥有更高的性能,因此可以通过daemonset方式在每个k8s节点运行一个filebeat日志采集容器,用于采集业务容器产生的日志并暂存到kafka消息队列中。借助Kafka的Consumer Group技术部署多个logstash副本,由logstash集群逐个消费并写入ES,防止瞬间高峰导致直接写入ES失败,提升数据处理能力和高可用性。
采集方案

Kafka部署
生产环境推荐的kafka部署方式为operator方式部署,Strimzi是目前最主流的operator方案。集群数据量较小的话,可以采用NFS共享存储,数据量较大的话可使用local pv存储。
部署operator
operator部署方式为helm或yaml文件部署,此处以helm方式部署为例:
[root@tiaoban kafka]# helm repo add strimzi https://strimzi.io/charts/ "strimzi" has been added to your repositories [root@tiaoban kafka]# helm install strimzi -n kafka strimzi/strimzi-kafka-operator NAME: strimzi LAST DEPLOYED: Sun Oct 8 21:16:31 2023 NAMESPACE: kafka STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Thank you for installing strimzi-kafka-operator-0.37.0 To create a Kafka cluster refer to the following documentation. https://strimzi.io/docs/operators/latest/deploying.html#deploying-cluster-operator-helm-chart-str [root@tiaoban strimzi-kafka-operator]# kubectl get pod -n kafka NAME READY STATUS RESTARTS AGE strimzi-cluster-operator-56fdbb99cb-gznkw 1/1 Running 0 17m- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
查看示例文件
Strimzi官方仓库为我们提供了各种场景下的示例文件,资源清单下载地址:https://github.com/strimzi/strimzi-kafka-operator/releases
[root@tiaoban kafka]# ls strimzi-kafka-operator [root@tiaoban kafka]# wget https://github.com/strimzi/strimzi-kafka-operator/releases/download/0.37.0/strimzi-0.37.0.tar.gz [root@tiaoban kafka]# tar -zxf strimzi-0.37.0.tar.gz [root@tiaoban kafka]# cd strimzi-0.37.0/examples/kafka [root@tiaoban kafka]# ls kafka-ephemeral-single.yaml kafka-ephemeral.yaml kafka-jbod.yaml kafka-persistent-single.yaml kafka-persistent.yaml nodepools- 1
- 2
- 3
- 4
- 5
- 6
- 7
- kafka-persistent.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点的持久集群。(推荐)
- kafka-jbod.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点(每个节点使用多个持久卷)的持久集群。
- kafka-persistent-single.yaml:部署具有单个 ZooKeeper 节点和单个 Kafka 节点的持久集群。
- kafka-ephemeral.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点的临时群集。
- kafka-ephemeral-single.yaml:部署具有三个 ZooKeeper 节点和一个 Kafka 节点的临时群集。
创建pvc资源
此处以nfs存储为例,提前创建pvc资源,分别用于3个zookeeper和3个kafka持久化存储数据使用。
[root@tiaoban kafka]# cat kafka-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: data-my-cluster-zookeeper-0 namespace: kafka spec: storageClassName: nfs-client accessModes: - ReadWriteOnce resources: requests: storage: 100Gi --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: data-my-cluster-zookeeper-1 namespace: kafka spec: storageClassName: nfs-client accessModes: - ReadWriteOnce resources: requests: storage: 100Gi --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: data-my-cluster-zookeeper-2 namespace: kafka spec: storageClassName: nfs-client accessModes: - ReadWriteOnce resources: requests: storage: 100Gi --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: data-0-my-cluster-kafka-0 namespace: kafka spec: storageClassName: nfs-client accessModes: - ReadWriteOnce resources: requests: storage: 100Gi --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: data-0-my-cluster-kafka-1 namespace: kafka spec: storageClassName: nfs-client accessModes: - ReadWriteOnce resources: requests: storage: 100Gi --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: data-0-my-cluster-kafka-2 namespace: kafka spec: storageClassName: nfs-client accessModes: - ReadWriteOnce resources: requests: storage: 100Gi- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
部署kafka和zookeeper
参考官方仓库的kafka-persistent.yaml示例文件,部署三个 ZooKeeper 和三个 Kafka 节点的持久集群。
[root@tiaoban kafka]# cat kafka.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster namespace: kafka spec: kafka: version: 3.5.1 replicas: 3 listeners: - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true config: offsets.topic.replication.factor: 3 transaction.state.log.replication.factor: 3 transaction.state.log.min.isr: 2 default.replication.factor: 3 min.insync.replicas: 2 inter.broker.protocol.version: "3.5" storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false zookeeper: replicas: 3 storage: type: persistent-claim size: 100Gi deleteClaim: false entityOperator: topicOperator: {} userOperator: {}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
访问验证
查看资源信息,已成功创建相关pod和svc资源。
[root@tiaoban kafka]# kubectl get pod -n kafka NAME READY STATUS RESTARTS AGE my-cluster-entity-operator-7c68d4b9d9-tg56j 3/3 Running 0 2m15s my-cluster-kafka-0 1/1 Running 0 2m54s my-cluster-kafka-1 1/1 Running 0 2m54s my-cluster-kafka-2 1/1 Running 0 2m54s my-cluster-zookeeper-0 1/1 Running 0 3m19s my-cluster-zookeeper-1 1/1 Running 0 3m19s my-cluster-zookeeper-2 1/1 Running 0 3m19s strimzi-cluster-operator-56fdbb99cb-gznkw 1/1 Running 0 97m [root@tiaoban kafka]# kubectl get svc -n kafka NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-cluster-kafka-bootstrap ClusterIP 10.99.246.133 <none> 9091/TCP,9092/TCP,9093/TCP 3m3s my-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,8443/TCP,9092/TCP,9093/TCP 3m3s my-cluster-zookeeper-client ClusterIP 10.109.106.29 <none> 2181/TCP 3m28s my-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 3m28s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
部署kafka-ui
创建configmap和ingress资源,在configmap中指定kafka连接地址。以traefik为例,创建ingress资源便于通过域名方式访问。
[root@tiaoban kafka]# cat kafka-ui.yaml apiVersion: v1 kind: ConfigMap metadata: name: kafka-ui-helm-values namespace: kafka data: KAFKA_CLUSTERS_0_NAME: "kafka-cluster" KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: "my-cluster-kafka-brokers.kafka.svc:9092" AUTH_TYPE: "DISABLED" MANAGEMENT_HEALTH_LDAP_ENABLED: "FALSE" --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: name: kafka-ui namespace: kafka spec: entryPoints: - web routes: - match: Host(`kafka-ui.local.com`) kind: Rule services: - name: kafka-ui port: 80 [root@tiaoban kafka]# kubectl apply -f kafka-ui.yaml configmap/kafka-ui-helm-values created ingressroute.traefik.containo.us/kafka-ui created- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
helm方式部署kafka-ui并指定配置文件
[root@tiaoban kafka]# helm install kafka-ui kafka-ui/kafka-ui -n kafka --set existingConfigMap="kafka-ui-helm-values" NAME: kafka-ui LAST DEPLOYED: Mon Oct 9 09:56:45 2023 NAMESPACE: kafka STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: 1. Get the application URL by running these commands: export POD_NAME=$(kubectl get pods --namespace kafka -l "app.kubernetes.io/name=kafka-ui,app.kubernetes.io/instance=kafka-ui" -o jsonpath="{.items[0].metadata.name}") echo "Visit http://127.0.0.1:8080 to use your application" kubectl --namespace kafka port-forward $POD_NAME 8080:8080- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
访问验证,添加hosts记录
192.168.10.100 kafka-ui.local.com,然后访问测试。

filebeat部署配置
资源清单
- rbac.yaml:创建filebeat用户和filebeat角色,并授予filebeat角色获取集群资源权限,并绑定角色与权限。
apiVersion: v1 kind: ServiceAccount metadata: name: filebeat namespace: elk --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: filebeat namespace: elk rules: - apiGroups: ["","apps","batch"] resources: ["*"] verbs: - get - watch - list --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: filebeat namespace: elk subjects: - kind: ServiceAccount name: filebeat namespace: elk roleRef: kind: ClusterRole name: filebeat apiGroup: rbac.authorization.k8s.io- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- filebeat-conf.yaml:使用filebeat.autodiscover方式自动获取pod日志,避免新增pod时日志采集不到的情况发生,并将日志发送到kafka消息队列中。
apiVersion: v1 kind: ConfigMap metadata: name: filebeat-config namespace: elk data: filebeat.yml: |- filebeat.autodiscover: providers: # 启用自动发现采集pod日志 - type: kubernetes node: ${NODE_NAME} hints.enabled: true hints.default_config: type: container paths: - /var/log/containers/*${data.kubernetes.container.id}.log exclude_files: ['.*filebeat-.*'] # 排除filebeat自身日志采集 multiline: # 避免日志换行 pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}' negate: true match: after processors: - add_kubernetes_metadata: # 增加kubernetes的属性 in_cluster: true host: ${NODE_NAME} matchers: - logs_path: logs_path: "/var/log/containers/" - drop_event: # 不收集debug日志 when: contains: message: "DEBUG" output.kafka: hosts: ["my-cluster-kafka-brokers.kafka.svc:9092"] topic: "pod_logs" partition.round_robin: reachable_only: false required_acks: -1 compression: gzip monitoring: # monitoring相关配置 enabled: true cluster_uuid: "ZUnqLCRqQL2jeo5FNvMI9g" elasticsearch: hosts: ["https://elasticsearch-es-http.elk.svc:9200"] username: "elastic" password: "2zg5q6AU7xW5jY649yuEpZ47" ssl.verification_mode: "none"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- filebeat.yaml:使用daemonset方式每个节点运行一个filebeat容器,并挂载filebeat配置文件、数据目录、宿主机日志目录。
apiVersion: apps/v1 kind: DaemonSet metadata: name: filebeat namespace: elk labels: app: filebeat spec: selector: matchLabels: app: filebeat template: metadata: labels: app: filebeat spec: serviceAccountName: filebeat dnsPolicy: ClusterFirstWithHostNet containers: - name: filebeat image: harbor.local.com/elk/filebeat:8.9.1 args: ["-c","/etc/filebeat/filebeat.yml","-e"] env: - name: NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName securityContext: runAsUser: 0 resources: limits: cpu: 500m memory: 1Gi volumeMounts: - name: timezone mountPath: /etc/localtime - name: config mountPath: /etc/filebeat/filebeat.yml subPath: filebeat.yml - name: data mountPath: /usr/share/filebeat/data - name: containers mountPath: /var/log/containers readOnly: true - name: logs mountPath: /var/log/pods volumes: - name: timezone hostPath: path: /usr/share/zoneinfo/Asia/Shanghai - name: config configMap: name: filebeat-config - name: data hostPath: path: /var/lib/filebeat-data type: DirectoryOrCreate - name: containers hostPath: path: /var/log/containers - name: logs hostPath: path: /var/log/pods- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
访问验证
查看pod信息,在集群每个节点上运行了一个filebeat采集容器。
[root@tiaoban ~]# kubectl get pod -n elk | grep filebeat filebeat-8p24s 1/1 Running 0 29s filebeat-chh9b 1/1 Running 0 29s filebeat-dl28d 1/1 Running 0 29s filebeat-gnkt6 1/1 Running 0 29s filebeat-m4rfx 1/1 Running 0 29s filebeat-w4pdz 1/1 Running 0 29s- 1
- 2
- 3
- 4
- 5
- 6
- 7
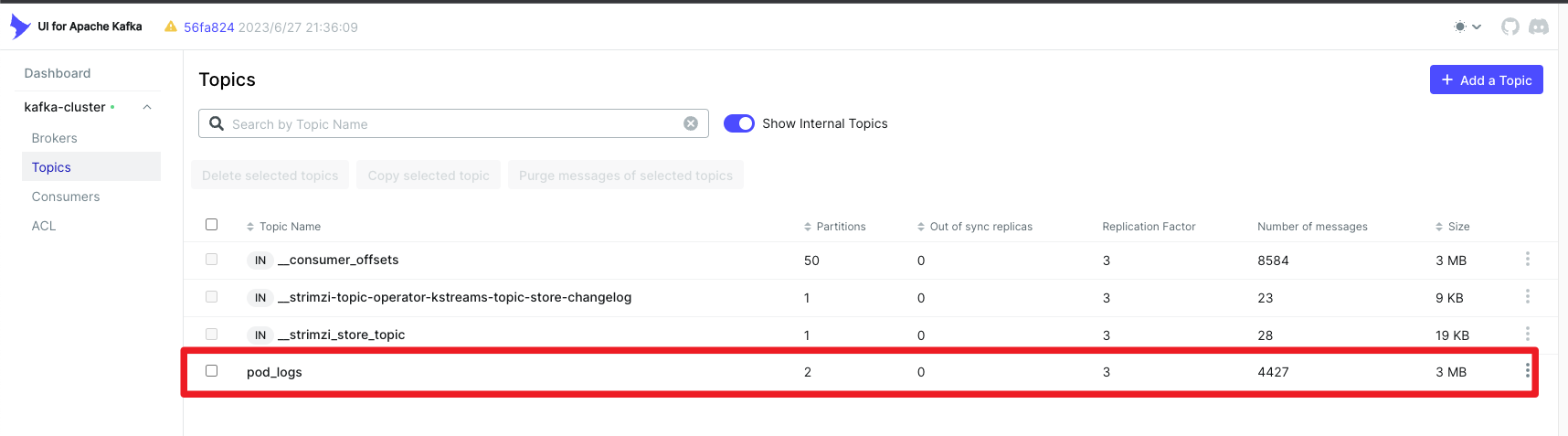
查看kafka topic信息,已经成功创建了名为pod_logs的topic,此时我们调整partitions为2,方便logstash多副本消费。
logstash部署配置
构建镜像
由于logstash镜像默认不包含geoip地理位置数据库文件,如果需要解析ip位置信息时会存在解析失败的情况。因此需要提前构建包含geoip数据库文件的logstash镜像,并上传至harbor仓库中。
[root@tiaoban elk]# cat Dockerfile FROM docker.elastic.co/logstash/logstash:8.9.1 ADD GeoLite2-City.mmdb /etc/logstash/GeoLite2-City.mmdb [root@tiaoban elk]# docker build -t harbor.local.com/elk/logstash:v8.9.1 . [root@tiaoban elk]# docker push harbor.local.com/elk/logstash:v8.9.1- 1
- 2
- 3
- 4
- 5
资源清单
- logstash-log4j2.yaml:容器方式运行时,logstash日志默认使用的console输出, 不记录到日志文件中, logs目录下面只有gc.log,我们可以通过配置log4j2设置,将日志写入到文件中,方便fleet采集分析logstash日志。
apiVersion: v1 kind: ConfigMap metadata: name: logstash-log4j2 namespace: elk data: log4j2.properties: | status = error name = LogstashPropertiesConfig appender.console.type = Console appender.console.name = plain_console appender.console.layout.type = PatternLayout appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c]%notEmpty{[%X{pipeline.id}]}%notEmpty{[%X{plugin.id}]} %m%n appender.json_console.type = Console appender.json_console.name = json_console appender.json_console.layout.type = JSONLayout appender.json_console.layout.compact = true appender.json_console.layout.eventEol = true appender.rolling.type = RollingFile appender.rolling.name = plain_rolling appender.rolling.fileName = ${sys:ls.logs}/logstash-plain.log appender.rolling.filePattern = ${sys:ls.logs}/logstash-plain-%d{yyyy-MM-dd}-%i.log.gz appender.rolling.policies.type = Policies appender.rolling.policies.time.type = TimeBasedTriggeringPolicy appender.rolling.policies.time.interval = 1 appender.rolling.policies.time.modulate = true appender.rolling.layout.type = PatternLayout appender.rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c]%notEmpty{[%X{pipeline.id}]}%notEmpty{[%X{plugin.id}]} %m%n appender.rolling.policies.size.type = SizeBasedTriggeringPolicy appender.rolling.policies.size.size = 100MB appender.rolling.strategy.type = DefaultRolloverStrategy appender.rolling.strategy.max = 30 appender.rolling.avoid_pipelined_filter.type = PipelineRoutingFilter appender.json_rolling.type = RollingFile appender.json_rolling.name = json_rolling appender.json_rolling.fileName = ${sys:ls.logs}/logstash-json.log appender.json_rolling.filePattern = ${sys:ls.logs}/logstash-json-%d{yyyy-MM-dd}-%i.log.gz appender.json_rolling.policies.type = Policies appender.json_rolling.policies.time.type = TimeBasedTriggeringPolicy appender.json_rolling.policies.time.interval = 1 appender.json_rolling.policies.time.modulate = true appender.json_rolling.layout.type = JSONLayout appender.json_rolling.layout.compact = true appender.json_rolling.layout.eventEol = true appender.json_rolling.policies.size.type = SizeBasedTriggeringPolicy appender.json_rolling.policies.size.size = 100MB appender.json_rolling.strategy.type = DefaultRolloverStrategy appender.json_rolling.strategy.max = 30 appender.json_rolling.avoid_pipelined_filter.type = PipelineRoutingFilter appender.routing.type = PipelineRouting appender.routing.name = pipeline_routing_appender appender.routing.pipeline.type = RollingFile appender.routing.pipeline.name = appender-${ctx:pipeline.id} appender.routing.pipeline.fileName = ${sys:ls.logs}/pipeline_${ctx:pipeline.id}.log appender.routing.pipeline.filePattern = ${sys:ls.logs}/pipeline_${ctx:pipeline.id}.%i.log.gz appender.routing.pipeline.layout.type = PatternLayout appender.routing.pipeline.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %m%n appender.routing.pipeline.policy.type = SizeBasedTriggeringPolicy appender.routing.pipeline.policy.size = 100MB appender.routing.pipeline.strategy.type = DefaultRolloverStrategy appender.routing.pipeline.strategy.max = 30 rootLogger.level = ${sys:ls.log.level} rootLogger.appenderRef.console.ref = ${sys:ls.log.format}_console rootLogger.appenderRef.rolling.ref = ${sys:ls.log.format}_rolling rootLogger.appenderRef.routing.ref = pipeline_routing_appender # Slowlog appender.console_slowlog.type = Console appender.console_slowlog.name = plain_console_slowlog appender.console_slowlog.layout.type = PatternLayout appender.console_slowlog.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %m%n appender.json_console_slowlog.type = Console appender.json_console_slowlog.name = json_console_slowlog appender.json_console_slowlog.layout.type = JSONLayout appender.json_console_slowlog.layout.compact = true appender.json_console_slowlog.layout.eventEol = true appender.rolling_slowlog.type = RollingFile appender.rolling_slowlog.name = plain_rolling_slowlog appender.rolling_slowlog.fileName = ${sys:ls.logs}/logstash-slowlog-plain.log appender.rolling_slowlog.filePattern = ${sys:ls.logs}/logstash-slowlog-plain-%d{yyyy-MM-dd}-%i.log.gz appender.rolling_slowlog.policies.type = Policies appender.rolling_slowlog.policies.time.type = TimeBasedTriggeringPolicy appender.rolling_slowlog.policies.time.interval = 1 appender.rolling_slowlog.policies.time.modulate = true appender.rolling_slowlog.layout.type = PatternLayout appender.rolling_slowlog.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %m%n appender.rolling_slowlog.policies.size.type = SizeBasedTriggeringPolicy appender.rolling_slowlog.policies.size.size = 100MB appender.rolling_slowlog.strategy.type = DefaultRolloverStrategy appender.rolling_slowlog.strategy.max = 30 appender.json_rolling_slowlog.type = RollingFile appender.json_rolling_slowlog.name = json_rolling_slowlog appender.json_rolling_slowlog.fileName = ${sys:ls.logs}/logstash-slowlog-json.log appender.json_rolling_slowlog.filePattern = ${sys:ls.logs}/logstash-slowlog-json-%d{yyyy-MM-dd}-%i.log.gz appender.json_rolling_slowlog.policies.type = Policies appender.json_rolling_slowlog.policies.time.type = TimeBasedTriggeringPolicy appender.json_rolling_slowlog.policies.time.interval = 1 appender.json_rolling_slowlog.policies.time.modulate = true appender.json_rolling_slowlog.layout.type = JSONLayout appender.json_rolling_slowlog.layout.compact = true appender.json_rolling_slowlog.layout.eventEol = true appender.json_rolling_slowlog.policies.size.type = SizeBasedTriggeringPolicy appender.json_rolling_slowlog.policies.size.size = 100MB appender.json_rolling_slowlog.strategy.type = DefaultRolloverStrategy appender.json_rolling_slowlog.strategy.max = 30 logger.slowlog.name = slowlog logger.slowlog.level = trace logger.slowlog.appenderRef.console_slowlog.ref = ${sys:ls.log.format}_console_slowlog logger.slowlog.appenderRef.rolling_slowlog.ref = ${sys:ls.log.format}_rolling_slowlog logger.slowlog.additivity = false logger.licensereader.name = logstash.licensechecker.licensereader logger.licensereader.level = error # Silence http-client by default logger.apache_http_client.name = org.apache.http logger.apache_http_client.level = fatal # Deprecation log appender.deprecation_rolling.type = RollingFile appender.deprecation_rolling.name = deprecation_plain_rolling appender.deprecation_rolling.fileName = ${sys:ls.logs}/logstash-deprecation.log appender.deprecation_rolling.filePattern = ${sys:ls.logs}/logstash-deprecation-%d{yyyy-MM-dd}-%i.log.gz appender.deprecation_rolling.policies.type = Policies appender.deprecation_rolling.policies.time.type = TimeBasedTriggeringPolicy appender.deprecation_rolling.policies.time.interval = 1 appender.deprecation_rolling.policies.time.modulate = true appender.deprecation_rolling.layout.type = PatternLayout appender.deprecation_rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c]%notEmpty{[%X{pipeline.id}]}%notEmpty{[%X{plugin.id}]} %m%n appender.deprecation_rolling.policies.size.type = SizeBasedTriggeringPolicy appender.deprecation_rolling.policies.size.size = 100MB appender.deprecation_rolling.strategy.type = DefaultRolloverStrategy appender.deprecation_rolling.strategy.max = 30 logger.deprecation.name = org.logstash.deprecation, deprecation logger.deprecation.level = WARN logger.deprecation.appenderRef.deprecation_rolling.ref = deprecation_plain_rolling logger.deprecation.additivity = false logger.deprecation_root.name = deprecation logger.deprecation_root.level = WARN logger.deprecation_root.appenderRef.deprecation_rolling.ref = deprecation_plain_rolling logger.deprecation_root.additivity = false- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- logstash-conf.yaml:修改Logstash配置,禁用默认的指标收集配置,并指定es集群uuid。
apiVersion: v1 kind: ConfigMap metadata: name: logstash-config namespace: elk data: logstash.conf: | api.enabled: true api.http.port: 9600 xpack.monitoring.enabled: false monitoring.cluster_uuid: "ZUnqLCRqQL2jeo5FNvMI9g"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- pod-pipeline.yaml:配置pipeline处理pod日志规则,从kafka读取数据后移除非必要的字段,然后写入ES集群中。
apiVersion: v1 kind: ConfigMap metadata: name: logstash-pod-pipeline namespace: elk data: pipeline.conf: | input { kafka { bootstrap_servers=>"my-cluster-kafka-brokers.kafka.svc:9092" auto_offset_reset => "latest" topics=>["pod_logs"] codec => "json" group_id => "pod" } } filter { mutate { remove_field => ["agent","event","ecs","host","[kubernetes][labels]","input","log","orchestrator","stream"] } } output{ elasticsearch{ hosts => ["https://elasticsearch-es-http.elk.svc:9200"] data_stream => "true" data_stream_type => "logs" data_stream_dataset => "pod" data_stream_namespace => "elk" user => "elastic" password => "2zg5q6AU7xW5jY649yuEpZ47" ssl_enabled => "true" ssl_verification_mode => "none" } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- pod-logstash.yaml:部署2副本的logstash容器,挂载pipeline、log4j2、logstash配置文件、日志路径资源。
apiVersion: apps/v1 kind: Deployment metadata: name: logstash-pod namespace: elk spec: replicas: 2 selector: matchLabels: app: logstash-pod template: metadata: labels: app: logstash-pod monitor: enable spec: securityContext: runAsUser: 0 containers: - image: harbor.local.com/elk/logstash:v8.9.1 name: logstash-pod resources: limits: cpu: "1" memory: 1Gi args: - -f - /usr/share/logstash/pipeline/pipeline.conf env: - name: XPACK_MONITORING_ENABLED value: "false" ports: - containerPort: 9600 volumeMounts: - name: timezone mountPath: /etc/localtime - name: config mountPath: /usr/share/logstash/config/logstash.conf subPath: logstash.conf - name: log4j2 mountPath: /usr/share/logstash/config/log4j2.properties subPath: log4j2.properties - name: pipeline mountPath: /usr/share/logstash/pipeline/pipeline.conf subPath: pipeline.conf - name: log mountPath: /usr/share/logstash/logs volumes: - name: timezone hostPath: path: /usr/share/zoneinfo/Asia/Shanghai - name: config configMap: name: logstash-config - name: log4j2 configMap: name: logstash-log4j2 - name: pipeline configMap: name: logstash-pod-pipeline - name: log hostPath: path: /var/log/logstash type: DirectoryOrCreate- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- logstash-svc.yaml:创建svc资源,用于暴露logstash监控信息接口。
apiVersion: v1 kind: Service metadata: name: logstash-monitor namespace: elk spec: selector: monitor: enable ports: - port: 9600 targetPort: 9600- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
添加监控指标采集
在fleet集成策略中安装logstash集群,并配置metrics接口地址为http://logstash-monitor.elk.svc:9600

访问验证
查看pod信息,已正常运行2副本的logstash。
[root@tiaoban ~]# kubectl get pod -n elk | grep logstash logstash-pod-7bb6f6c8c6-ffc4b 1/1 Running 0 58s logstash-pod-7bb6f6c8c6-qv9kd 1/1 Running 0 58s- 1
- 2
- 3
登录kibana查看监控信息,已成功采集filebeat和logstash指标和日志数据。

查看数据流信息,已成功创建名为logs-pod-elk的数据流。

查看数据流内容,成功存储解析了pod所在节点、namespace、container、日志内容等数据。

自定义日志解析
需求分析
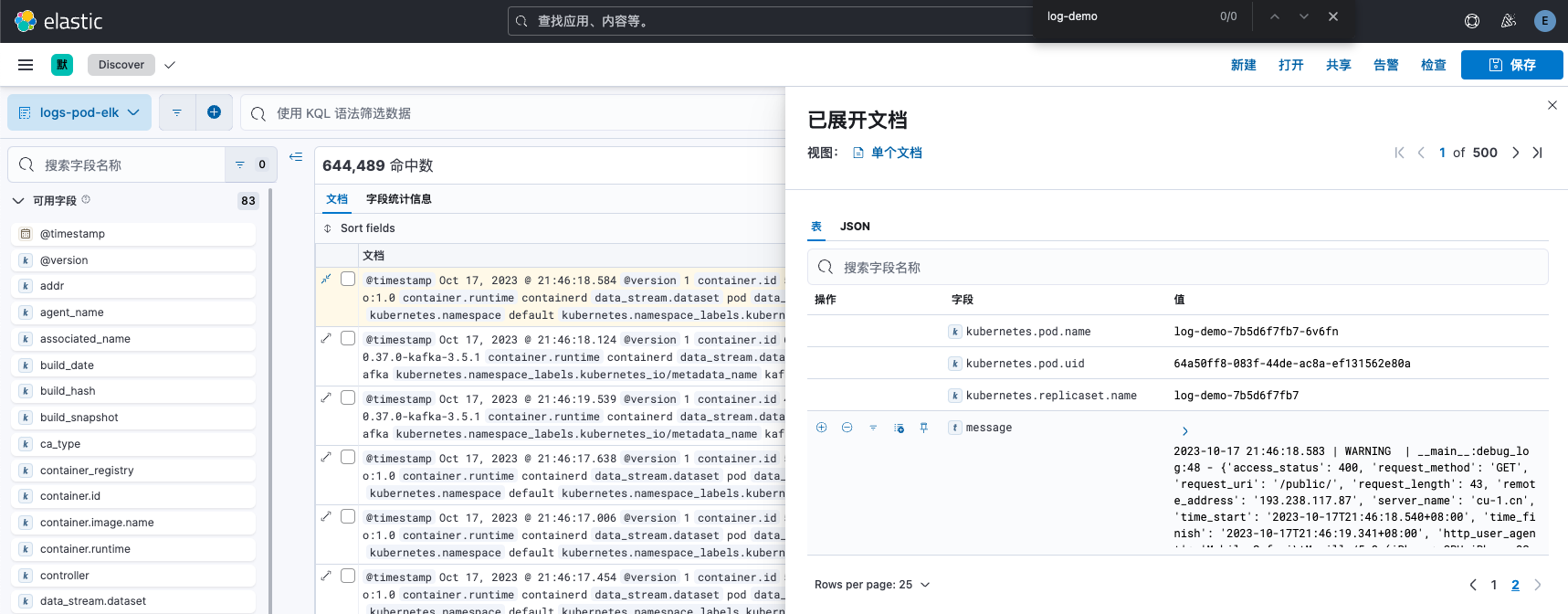
默认情况下,fluent bit会采集所有pod日志信息,并自动添加namespace、pod、container等信息,所有日志内容存储在log字段中。
以log-demo应为日志为例,将所有日志内容存储到log字段下,如果想要按条件筛选分析日志数据时,无法很好的解析日志内容,因此需要配置logstash解析规则,实现日志自定义日志内容解析。
资源清单
- myapp-pipeline.yaml:从kafka中读取数据,当匹配到[kubernetes][deployment][name]字段值为log-demo时,进一步做解析处理,其余日志数据丢弃。logstash详细配置可参考历史文章:https://www.cuiliangblog.cn/detail/article/63
apiVersion: v1 kind: ConfigMap metadata: name: logstash-myapp-pipeline namespace: elk data: pipeline.conf: | input { kafka { bootstrap_servers=>"my-cluster-kafka-brokers.kafka.svc:9092" auto_offset_reset => "latest" topics=>["pod_logs"] codec => "json" group_id => "myapp" } } filter { if [kubernetes][deployment][name] == "log-demo" { grok{ match => {"message" => "%{TIMESTAMP_ISO8601:log_timestamp} \| %{LOGLEVEL:level} %{SPACE}* \| (?[__main__:[\w]*:\d*]+) \- %{GREEDYDATA:content}"} } mutate { gsub =>[ "content", "'", '"' ] lowercase => [ "level" ] } json { source => "content" } geoip { source => "remote_address" database => "/etc/logstash/GeoLite2-City.mmdb" ecs_compatibility => disabled } mutate { remove_field => ["agent","event","ecs","host","[kubernetes][labels]","input","log","orchestrator","stream","content"] } } else { drop{} } } output{ elasticsearch{ hosts => ["https://elasticsearch-es-http.elk.svc:9200"] data_stream => "true" data_stream_type => "logs" data_stream_dataset => "myapp" data_stream_namespace => "elk" user => "elastic" password => "2zg5q6AU7xW5jY649yuEpZ47" ssl_enabled => "true" ssl_verification_mode => "none" } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- myapp-logstash.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: logstash-myapp namespace: elk spec: replicas: 2 selector: matchLabels: app: logstash-myapp template: metadata: labels: app: logstash-myapp monitor: enable spec: securityContext: runAsUser: 0 containers: - image: harbor.local.com/elk/logstash:v8.9.1 name: logstash-myapp resources: limits: cpu: "1" memory: 1Gi args: - -f - /usr/share/logstash/pipeline/pipeline.conf env: - name: XPACK_MONITORING_ENABLED value: "false" ports: - containerPort: 9600 volumeMounts: - name: timezone mountPath: /etc/localtime - name: config mountPath: /usr/share/logstash/config/logstash.conf subPath: logstash.conf - name: log4j2 mountPath: /usr/share/logstash/config/log4j2.properties subPath: log4j2.properties - name: pipeline mountPath: /usr/share/logstash/pipeline/pipeline.conf subPath: pipeline.conf - name: log mountPath: /usr/share/logstash/logs volumes: - name: timezone hostPath: path: /usr/share/zoneinfo/Asia/Shanghai - name: config configMap: name: logstash-config - name: log4j2 configMap: name: logstash-log4j2 - name: pipeline configMap: name: logstash-myapp-pipeline - name: log hostPath: path: /var/log/logstash type: DirectoryOrCreate- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
访问验证
查看数据流信息,已成功创建名为logs-myapp-elk的数据流。

查看数据流详细内容,成功解析了日志相关字段数据。

注意事项
kafka partition数配置
需要注意的是每个consumer最多只能使用一个partition,当一个Group内consumer的数量大于partition的数量时,只有等于partition个数的consumer能同时消费,其他的consumer处于等待状态。因此想要增加logstash的消费性能,可以适当的增加topic的partition数量,但kafka中partition数量过多也会导致kafka集群故障恢复时间过长。
logstash副本数配置
Logstash副本数=kafka partition数/每个logstash线程数(默认为1,数据量大时可增加线程数,建议不超过4)
完整资源清单
本实验案例所有yaml文件已上传至git仓库。访问地址如下:
github
https://github.com/cuiliang0302/blog-demo
gitee
https://gitee.com/cuiliang0302/blog_demo
参考文档
helm部署Strimzi:https://strimzi.io/docs/operators/latest/deploying#deploying-cluster-operator-helm-chart-str
filebeat通过自动发现采集k8s日志:https://www.elastic.co/guide/en/beats/filebeat/current/configuration-autodiscover-hints.html
kubernetes集群运行filebeat:https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
filebeat处理器新增kubernetes元数据信息:https://www.elastic.co/guide/en/beats/filebeat/current/add-kubernetes-metadata.html
filebeat丢弃指定事件:https://www.elastic.co/guide/en/beats/filebeat/current/drop-event.html查看更多
微信公众号
微信公众号同步更新,欢迎关注微信公众号《崔亮的博客》第一时间获取最近文章。
博客网站
崔亮的博客-专注devops自动化运维,传播优秀it运维技术文章。更多原创运维开发相关文章,欢迎访问https://www.cuiliangblog.cn
-
相关阅读:
VsCode搭建Java开发环境 vscode搭建java开发环境 vscode springboot 搭建springboot
小国王——状压DP
Day 44 Ansible自动化运维
2023-10-11 python-windows平台-安装-记录
C#程序随系统启动例子 - 开源研究系列文章
JUC并发编程系列详解篇十二(synchronized底层原理进阶)
Python绘制各种图形(模板)
13薪|18k-30k -JAVA开发工程师[北京市 - 海淀区]
伴随对象的初始化
Vue路由重复点击报错解决
- 原文地址:https://blog.csdn.net/qq_33816243/article/details/133934539
