-
搭建伪分布式Hadoop
文章目录
一、Hadoop部署模式
(一)独立模式
- 在独立模式下,所有程序都在单个JVM上执行,调试Hadoop集群的MapReduce程序也非常方便。一般情况下,该模式常用于学习或开发阶段进行调试程序。
(二)伪分布式模式
- 在伪分布式模式下, Hadoop程序的守护进程都运行在一台节点上,该模式主要用于调试Hadoop分布式程序的代码,以及程序执行是否正确。伪分布式模式是完全分布式模式的一个特例。
(三)完全分布式模式
- 在完全分布式模式下,Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
二、搭建伪分布式Hadoop
(一)登录虚拟机
- 登录ied虚拟机

(二)上传安装包
-
上传jdk和hadoop安装包

-
查看上传的安装包

(三)配置免密登录
1、生成密钥对
- 执行命令:
ssh-keygen
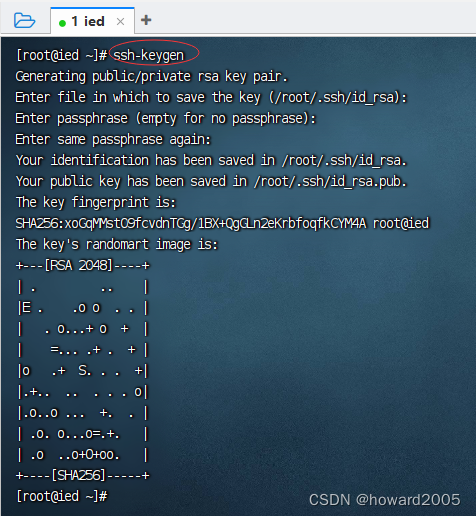
- 执行命令后,连续敲回车,生成节点的公钥和私钥,生成的密钥文件会自动放在/root/.ssh目录下。

2、将生成的公钥发送到本机
- 执行命令:
ssh-copy-id root@ied

3、验证虚拟机是否能免密登录自己
- 执行命令:
ssh ied

(四)配置JDK
1、解压到指定目录
(1)解压到指定目录
- 执行命令:
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local

(2)查看java解压目录
- 执行命令:
ll /usr/local/jdk1.8.0_231
2、配置JDK环境变量
- 执行命令:
vim /etc/profile

export JAVA_HOME=/usr/local/jdk1.8.0_231 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar- 1
- 2
- 3
- 存盘退出

3、让环境变量配置生效
- 执行命令:
source /etc/profile

- 查看环境变量
JAVA_HOME

4、查看JDK版本
- 执行命令:
java -version

5、玩一玩Java程序
- 编写源程序,执行命令:
vim HelloWorld.java

- 编译成字节码文件,执行命令:
javac HelloWorld.java

- 解释执行类,执行命令:
java HelloWorld

(五)配置Hadoop
1、解压hadoop安装包
(1)解压到指定目录
- 执行命令:
tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local

(2)查看hadoop解压目录
- 执行命令:
ll /usr/local/hadoop-3.3.4

(3)常用目录和文件
- bin目录 - 存放命令脚本

- etc/hadoop目录 - 存放hadoop的配置文件
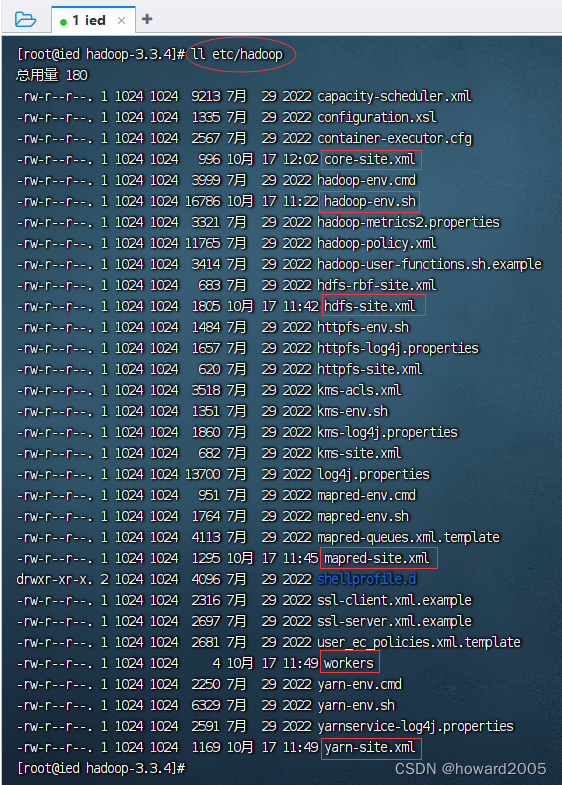
- lib目录 - 存放hadoop运行的依赖jar包

- sbin目录 - 存放启动和关闭Hadoop等命令

- libexec目录 - 存放的也是hadoop命令,但一般不常用

2、配置hadoop环境变量
- 执行命令:
vim /etc/profile

export HADOOP_HOME=/usr/local/hadoop-3.3.4 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 说明:hadoop 2.x用不着配置用户,只需要前两行即可
3、让环境变量配置生效
- 执行命令:
source /etc/profile

4、查看hadoop版本
- 执行命令:
hadoop version

5、编辑Hadoop环境配置文件 - hadoop-env.sh
- 执行命令:
cd etc/hadoop,进入hadoop配置目录

- 执行命令:
vim hadoop-env.sh,添加三条环境变量配置

- 存盘退出后,执行命令
source hadoop-env.sh,让配置生效

6、编辑Hadoop核心配置文件 - core-site.xml
- 执行命令:
vim core-site.xml

<configuration> <property> <name>fs.defaultFSname> <value>hdfs://ied:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/usr/local/hadoop-3.3.4/tmpvalue> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 由于配置了IP地址主机名映射,因此配置HDFS老大节点可用
hdfs://ied:9000,否则必须用IP地址hdfs://192.168.1.100:9000

7、编辑HDFS配置文件 - hdfs-site.xml
- 执行命令:
vim hdfs-site.xml

<configuration> <property> <name>dfs.namenode.name.dirname> <value>/usr/local/hadoop-3.3.4/tmp/namenodevalue> property> <property> <name>dfs.datanode.data.dirname> <value>/usr/local/hadoop-3.3.4/tmp/datanodevalue> property> <property> <name>dfs.namenode.secondary.http-addressname> <value>ied:50090value> property> <property> <name>dfs.namenode.http-addressname> <value>0.0.0.0:9870value> property> <property> <name>dfs.replicationname> <value>1value> property> <property> <name>dfs.permissions.enabledname> <value>falsevalue> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
8、编辑MapReduce配置文件 - mapred-site.xml
- 执行命令:
vim mapred-site.xml

<configuration> <property> <name>mapreduce.framework.namename> <value>yarnvalue> property> <property> <name>yarn.app.mapreduce.am.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property> <property> <name>mapreduce.map.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property> <property> <name>mapreduce.reduce.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 后三个属性如果不设置,在运行Hadoop自带示例的词频统计时,会报错:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
9、编辑YARN配置文件 - yarn-site.xml
- 执行命令:
vim yarn-site.xml
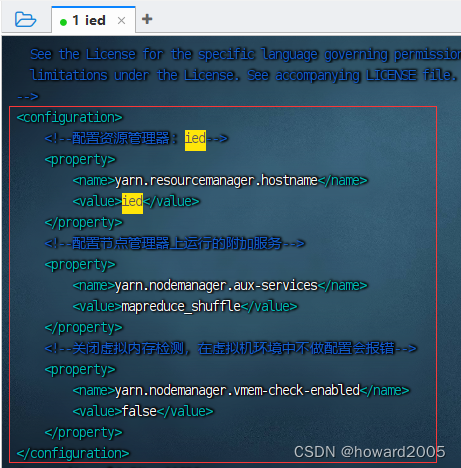
<configuration> <property> <name>yarn.resourcemanager.hostnamename> <value>iedvalue> property> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.nodemanager.vmem-check-enabledname> <value>falsevalue> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
10、编辑workers文件确定数据节点
- 说明:hadoop-2.x里配置
slaves文件,hadoop-3.x里配置workers文件 - 执行命令:
vim workers

- 只有1个数据节点,正好跟副本数配置的1一致
(六)格式化名称节点
- 执行命令:
hdfs namenode -format



Storage directory /usr/local/hadoop-3.3.4/tmp/namenode has been successfully formatted.表明名称节点格式化成功。
(七)启动Hadoop服务
1、启动hdfs服务
- 执行命令:
start-dfs.sh

2、启动yarn服务
- 执行命令:
start-yarn.sh

3、查看Hadoop进程
-
执行命令:
jps

-
说明:
start-dfs.sh与start-yarn.sh可以用一条命令start-all.sh来替换

(八)查看Hadoop WebUI
- 在浏览器里访问
http://ied:9870

- 查看文件系统

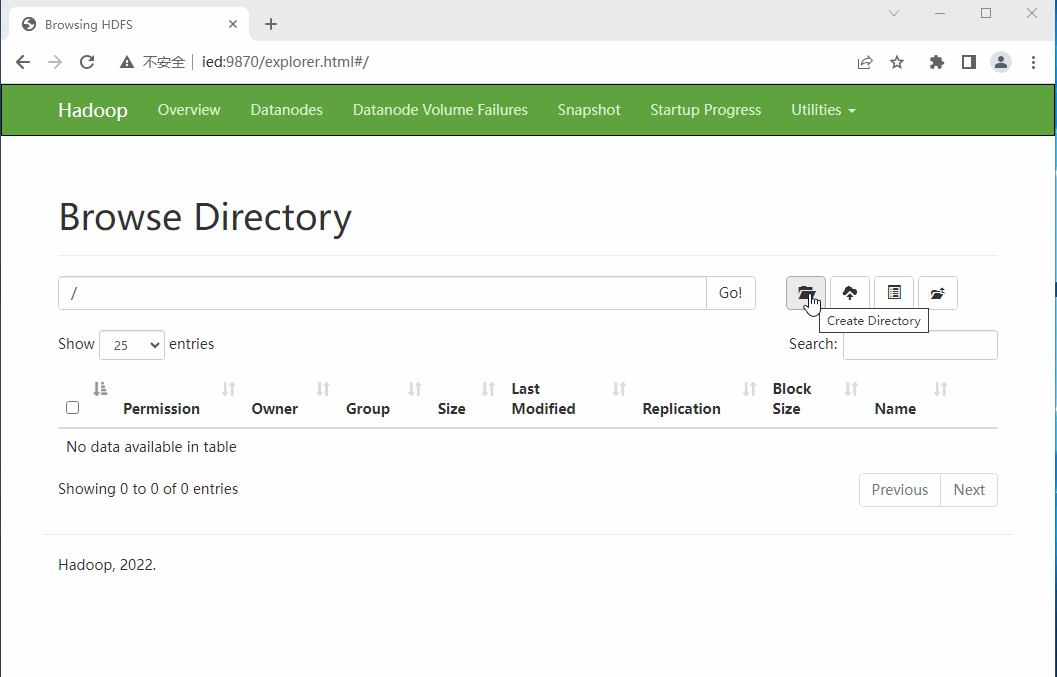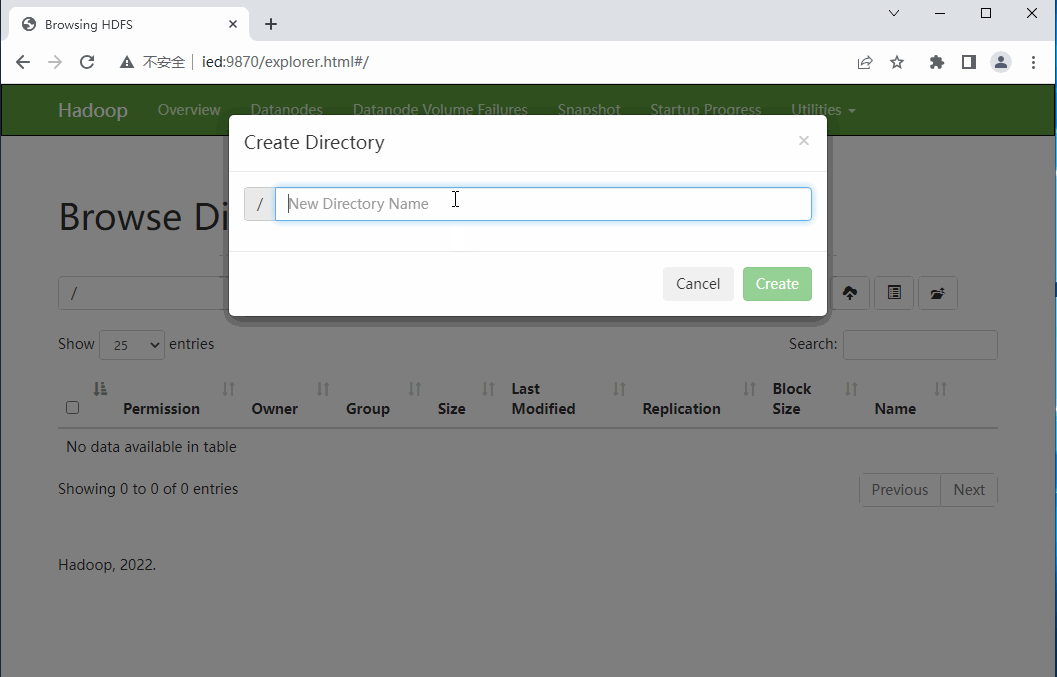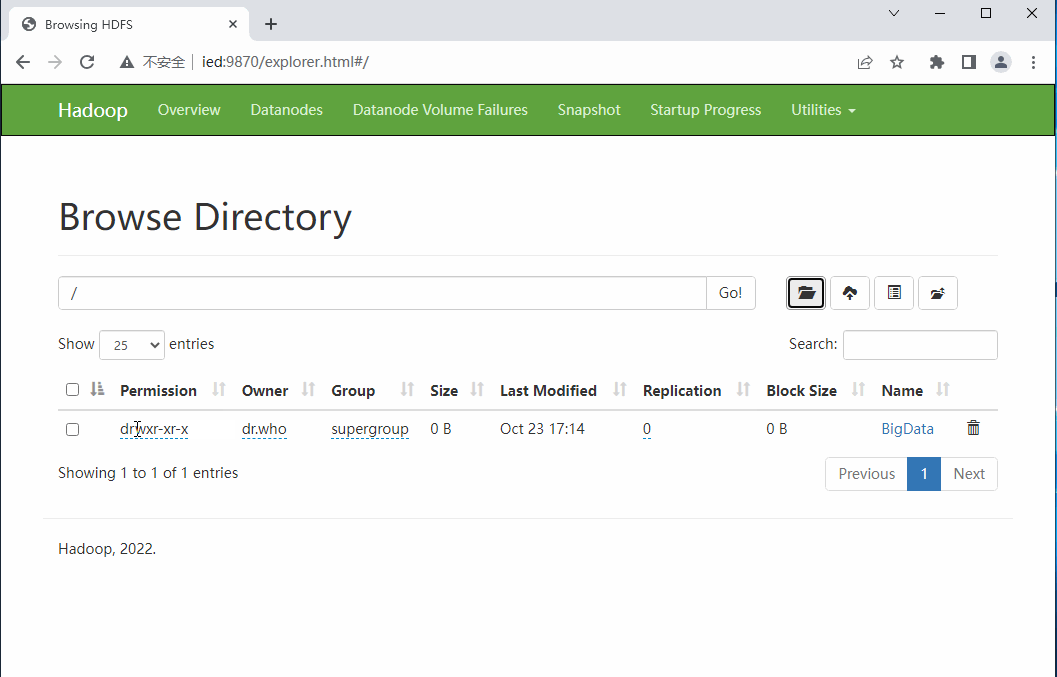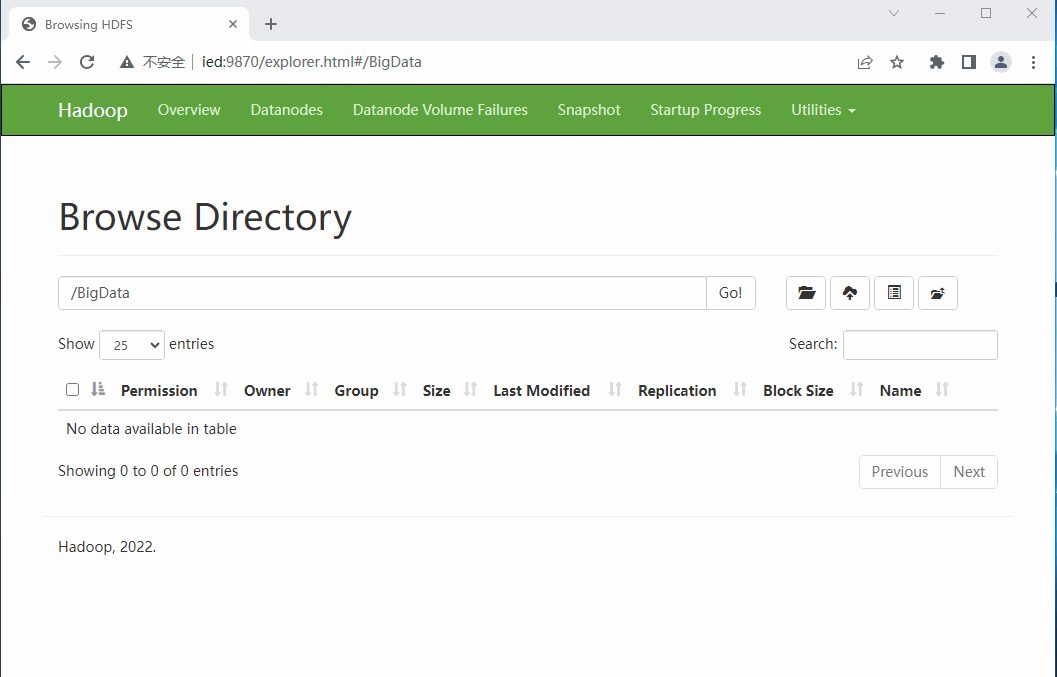
- 根目录下没有任何内容
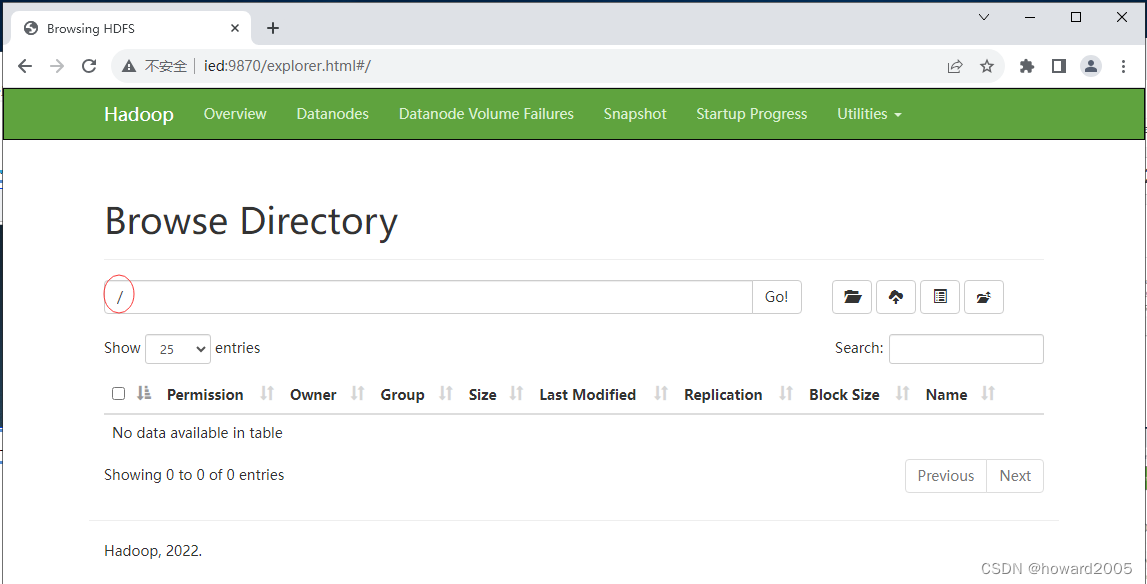
- 创建目录 -
BigData
- 上传一个大文件 -
hadoop安装包

- Hadoop3.x里文件块尺寸 - 128MB,安装包有673.24MB,需要切分成6块


- 删除文件和目录

(九)关闭Hadoop服务
1、关闭hdfs服务
- 执行命令:
stop-dfs.sh

2、关闭yarn服务
-
执行命令:
stop-yarn.sh

-
说明:
stop-dfs.sh与stop-yarn.sh可以用一条命令stop-all.sh来替换

-
相关阅读:
招标人对称重系统一般有什么要求
CSS页面基本布局
NPDP 02组合管理
Java 异常处理
Hadoop集群搭建
Spring依赖注入、循环依赖——三级缓存
JS模块化—CJS&AMD&CMD&ES6-前端面试知识点查漏补缺
vue生命周期详解
宋浩高等数学笔记(三)微分中值定理
受欢迎的奶牛
- 原文地址:https://blog.csdn.net/howard2005/article/details/133884240
