-
Hadoop集群搭建
Hadoop集群搭建
Hadoop集群简介
- Hadoop集群包括两个集群: HDFS集群、YARN集群
- 两个集群逻辑上分离、通常物理上在一起
- 两个集群都是标准的主从架构集群
-
HDFS集群(分布式存储)
主角色:NameNode
从角色:DataNode
主角色辅助角色:SecondaryNameNode -
YARN集群(资源管理、调度)
主角色:ResourceManager
从角色:NodeManager
如何理解两个集群逻辑上分离
两个集群互相之间没有依赖、互不影响
如何理解两个集群物理上在一起
某些角色进程往往部署在同一台物理服务器上
为什么没有MapReduce集群?
MapReduce是计算框架、代码层面的组件,没有集群一说

Hadoop部署模式
-
单机模式
一个机器运行1个Java进程,所有角色在一个进程中运行,主要用于调试
-
伪分布式
一个机器运行多个进程,每个角色一个进程,主要用于调试
-
集群模式
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署不同的机器上。
-
HA高可用
在集群模式的基础上为单点故障部署备份角色,形成主备架构,实现容错。
Hadoop源码编译
- 安装包、源码包下载地址
- 为什么要重新编译Hadoop源码
匹配不同操作系统本地库环境,Hadoop某些操作比如压缩、IO需要调用系统本地库(.so|.dll)修改源码、重构源码 - 如何编译Hadoop
源码包根目录下文件: BUILDING.txt
编译Hadoop3.2.4
-
编译环境:Centos7
-
依赖版本:
-
编译源码版本:Hadoop3.2.4-src
统一工作目录
mkdir -p /export/server/ # 软件安装路径 mkdir -p /export/data/ # 数据存储路径 mkdir -p /export/software/ # 安装包存放路径- 1
- 2
- 3
创建安装目录
mkdir -p /export/server cd /export/server- 1
- 2
将之前下载的所有依赖放在当前目录
/export/server中安装编译依赖
yum install gcc gcc-c++ make autoconf automake libtool curl lzo-devel zlib-devel openssl openssl-devel ncurses-devel snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst zlib -y yum install -y doxygen cyrus-sasl* saslwrapper-devel*- 1
- 2
- 3
之所以没有使用yum安装cmake、snappy、maven、protobuf,是因为yum中的版本太低,无法正常编译Hadoop,所以某些依赖需要手动安装合适的版本。
安装cmake
tar -zxvf cmake-3.24.3.tar.gz cd cmake-3.24.3 ./configure make && make install- 1
- 2
- 3
- 4
验证
[root@node1 ~]# cmake -version cmake version 3.24.3 CMake suite maintained and supported by Kitware (kitware.com/cmake).- 1
- 2
- 3
- 4
安装snappy
卸载之前安装的
rm -rf /usr/local/lib/libsnappy* rm -rf /lib64/libsnappy*- 1
- 2
上传解压
tar -zxvf snappy-1.1.3.tar.gz- 1
编译安装
cd /export/server/snappy-1.1.3 ./configure make && make install- 1
- 2
- 3
验证安装
[root@node1 ~]# ls -lh /usr/local/lib |grep snappy -rw-r--r--. 1 root root 511K 11月 16 23:17 libsnappy.a -rwxr-xr-x. 1 root root 955 11月 16 23:17 libsnappy.la lrwxrwxrwx. 1 root root 18 11月 16 23:17 libsnappy.so -> libsnappy.so.1.3.0 lrwxrwxrwx. 1 root root 18 11月 16 23:17 libsnappy.so.1 -> libsnappy.so.1.3.0 -rwxr-xr-x. 1 root root 253K 11月 16 23:17 libsnappy.so.1.3.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
安装配置JDK 1.8
解压安装包
tar -zxvf jdk-8u341-linux-x64.tar.gz- 1
配置环境变量
vim ~/.bash_profile- 1
在文件末加上以下内容
export JAVA_HOME=/export/server/jdk1.8.0_341 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/libdt.jar:$JAVA_HOME/lib/tools.jar- 1
- 2
- 3
加载环境变量
source ~/.bash_profile- 1
验证是否安装成功
[root@node1 server]# java -version java version "1.8.0_341" Java(TM) SE Runtime Environment (build 1.8.0_341-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.341-b10, mixed mode)- 1
- 2
- 3
- 4
安装配置maven
解压安装包
tar -zxvf apache-maven-3.8.6-bin.tar.gz- 1
配置环境变量
vim ~/.bash_profile- 1
在
.bash_profile文件末添加以下内容export MAVEN_HOME=/export/server/apache-maven-3.8.6 export MAVEN_OPTS="-Xms256m -Xmx512m" export PATH=:$MAVEN_HOME/bin:$PATH- 1
- 2
- 3
加载环境变量
source ~/.bash_profile- 1
验证
[root@node1 server]# mvn -v Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63) Maven home: /export/server/apache-maven-3.8.6 Java version: 1.8.0_341, vendor: Oracle Corporation, runtime: /export/server/jdk1.8.0_341/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "linux", version: "3.10.0-1160.el7.x86_64", arch: "amd64", family: "unix"- 1
- 2
- 3
- 4
- 5
- 6
添加maven阿里云镜像仓库,提高编译速度
vim /export/server/apache-maven-3.8.6/conf/settings.xml- 1
在xml的mirrors标签内添加以下内容
<mirror> <id>alimavenid> <name>aliyun mavenname> <url>http://maven.aliyun.com/nexus/content/groups/public/url> <mirrorOf>centralmirrorOf> mirror>- 1
- 2
- 3
- 4
- 5
- 6
安装Protobuf3.19.6
解压
tar -zxvf protobuf-all-3.19.6.tar.gz- 1
编译安装
cd /export/server/protobuf-3.19.6 ./autogen.sh ./configure make && make install- 1
- 2
- 3
- 4
验证
[root@node1 protobuf-3.19.6]# protoc --version libprotoc 3.19.6- 1
- 2
编译Hadoop
解压
tar -zxvf hadoop-3.2.4-src.tar.gz- 1
编译
cd /export/server/hadoop-3.2.4-src mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib- 1
- 2
参数说明:
Pdist,native :把重新编译生成的hadoop动态库;
DskipTests :跳过测试
Dtar :最后把文件以tar打包
Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】
Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径集群部署Hadoop3.2.4
集群角色规划
服务器 运行角色 node1.vbox.cn namenode datenode resourcemanager nodemanager node2.vbox.cn secondarynamenode datanode nodemanager node3.vbox.cn datenode nodemanager 服务器基础环境准备
-
创建三台虚拟机
通过Oracle VM VirtualBox创建3台Centos7虚拟机
修改hostname(三台机器都需要修改)
[root@node1 ~]# vim /etc/hostname [root@node1 ~]# cat /etc/hostname node1.vbox.cn- 1
- 2
- 3
-
修改Hosts映射
vim /etc/hosts- 1
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.2.29 node1 node1.vbox.cn 192.168.2.30 node2 node2.vbox.cn 192.168.2.31 node3 node3.vbox.cn- 1
- 2
- 3
- 4
- 5
三台机器都需要修改
-
关闭防火墙
关闭防火墙
禁止防火墙自启systemctl stop firewalld systemctl disable firewalld- 1
- 2
三台机器都需要操作
-
ssh免密登录
node1
ssh-keygen -t rsa -C "node1@example.com"- 1
node2
ssh-keygen -t rsa -C "node2@example.com"- 1
node3
ssh-keygen -t rsa -C "node3@example.com"- 1
复制ssh到其他主机
ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id node3- 1
- 2
- 3
至少需要完成从node1 -> node1,node2,node3的免密登录
-
集群时间同步
yum -y install ntpdate ntpdate ntp4.aliyun.com- 1
- 2
每台机器都进行时间同步
-
JDK1.8安装
cd /export/server tar -zxvf jdk-8u341-linux-x64.tar.gz scp -r jdk1.8.0_341 node2:/export/server/ scp -r jdk1.8.0_341 node2:/export/server/- 1
- 2
- 3
- 4
在每台机器的
~/.bash_profile都设置环境变量export JAVA_HOME=/export/server/jdk1.8.0_341 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/libdt.jar:$JAVA_HOME/lib/tools.jar- 1
- 2
- 3
-
上传、解压Hadoop3.2.4安装包
上传之前编译好了的Hadoop3.2.4到node1,并解压。
tar -zxvf hadoop-3.2.4.tar.gz -C /export/server/- 1
-
hadoop目录结构
目录 说明 bin Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 etc Hadoop配置文件所在的目录 include 对外提供的编程库文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 lib 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 libexec 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 sbin Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动、关闭脚本 share Hadoop各个模块编译后的jar包所在目录,官方自带示例。 -
编辑Hadoop配置文件
-
hadoop-env.sh
cd /export/server/hadoop-3.2.4/etc/hadoop/ vim hadoop-env.sh- 1
- 2
在文件末尾加上以下内容
# 配置JAVA_HOME export JAVA_HOME=/export/server/jdk1.8.0_341 # 设置用户以执行对应角色shell命令 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
core-site.xml
cd /export/server/hadoop-3.2.4/etc/hadoop/ vim core-site.xml- 1
- 2
在configuration标签中添加以下内容
<property> <name>fs.defaultFSname> <value>hdfs://node1.vbox.cn:8020value> property> <property> <name>hadoop.tmp.dirname> <value>/export/data/hadoop-3.2.4value> property> <property> <name>hadoop.http.staticuser.username> <value>rootvalue> property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
-
hdfs-site.xml
cd /export/server/hadoop-3.2.4/etc/hadoop/ vim hdfs-site.xml- 1
- 2
在configuration标签中添加以下内容
<property> <name>dfs.namenode.secondary.http-addressname> <value>node2.vbox.cn:9868value> property>- 1
- 2
- 3
- 4
- 5
-
mapred-site.xml
cd /export/server/hadoop-3.2.4/etc/hadoop/ vim mapred-site.xml- 1
- 2
在configuration标签中添加以下内容
<property> <name>mapreduce.framework.namename> <value>yarnvalue> property> <property> <name>mapreduce.jobhistory.addressname> <value>node1.vbox.cn:10020value> property> <property> <name>mapreduce.jobhistory.webapp.addressname> <value>node1.vbox.cn:19888value> property> <property> <name>yarn.app.mapreduce.am.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property> <property> <name>mapreduce.map.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property> <property> <name>mapreduce.reduce.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
-
yarn-site.xml
cd /export/server/hadoop-3.2.4/etc/hadoop/ vim yarn-site.xml- 1
- 2
在configuration标签中添加以下内容
<property> <name>yarn.resourcemanager.hostnamename> <value>node1.vbox.cnvalue> property> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.scheduler.minimum-allocation-mbname> <value>256value> property> <property> <name>yarn.scheduler.maximum-allocation-mbname> <value>512value> property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
workers
cd /export/server/hadoop-3.2.4/etc/hadoop/ vim workers- 1
- 2
在
workers文件中添加主机名称或IPnode1.vbox.cn node2.vbox.cn node3.vbox.cn- 1
- 2
- 3
-
-
分发同步安装包
在node1机器上将Hadoop安装包scp同步到其他机器上
cd /export/server/ scp -r hadoop-3.2.4 node2:/export/server/ scp -r hadoop-3.2.4 node3:/export/server/- 1
- 2
- 3
- 4
-
配置Hadoop环境变量
在node1上配置Hadoop环境变量
vim ~/.bash_profile export HADOOP_HOME=/export/server/hadoop-3.2.4 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- 1
- 2
- 3
再其他三台机器执行同样的操作并加载环境变量
source ~/.bash_profile- 1
验证
[root@node1 hadoop]# hadoop version Hadoop 3.2.4 Source code repository Unknown -r Unknown Compiled by root on 2022-11-17T10:35Z Compiled with protoc 2.5.0 From source with checksum ee031c16fe785bbb35252c749418712 This command was run using /export/server/hadoop-3.2.4/share/hadoop/common/hadoop-common-3.2.4.jar- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
NameNode format(格式化操作)
首次启动HDFS时,必须对其进行格式化操作
format本质上是初始化工作,进行HDFS清理和准备工作
hdfs namenode -format- 1
当格式化日志中出现以下内容说明格式化成功

-
Hadoop集群启动关闭-手动逐个进程启停
每台机器上每次手动启动关闭一个角色进程
-
HDFS集群
hdfs --daemon start namenode|datanode|secondarynamenode hdfs --daemon stop namenode|datanode|secondarynamenode- 1
- 2
-
YARN集群
yarn --daemon start resourcemanager|nodemanager yarn --daemon stop resourcemanager|nodemanager- 1
- 2
在node1中启动
hdfs --daemon start namenode hdfs --daemon start datanode yarn --daemon start resourcemanager yarn --daemon start nodemanager jps- 1
- 2
- 3
- 4
- 5
[root@node1 hadoop-3.2.4]# hdfs --daemon start namenode [root@node1 hadoop-3.2.4]# hdfs --daemon start datanode [root@node1 hadoop-3.2.4]# yarn --daemon start resourcemanager [root@node1 hadoop-3.2.4]# yarn --daemon start nodemanager [root@node1 hadoop-3.2.4]# jps 2066 NameNode 2163 DataNode 2260 ResourceManager 2516 NodeManager 2605 Jps- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在node2中启动
hdfs --daemon start datanode hdfs --daemon start secondarynamenode yarn --daemon start nodemanager jps- 1
- 2
- 3
- 4
[root@node2 ~]# hdfs --daemon start datanode [root@node2 ~]# hdfs --daemon start secondarynamenode [root@node2 ~]# yarn --daemon start nodemanager [root@node2 ~]# jps 2451 Jps 2340 NodeManager 2262 SecondaryNameNode 2157 DataNode- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在node3中启动
hdfs --daemon start datanode yarn --daemon start nodemanager jps- 1
- 2
- 3
[root@node3 ~]# hdfs --daemon start datanode [root@node3 ~]# yarn --daemon start nodemanager [root@node3 ~]# jps 1605 NodeManager 1690 Jps 1518 DataNode- 1
- 2
- 3
- 4
- 5
- 6
-
-
Hadoop集群启动关闭-shell脚本一键启停
在node1上,使用自带的shell脚本一键启动
前提:配置好机器之间的SSH免密登录和workers文件。
-
HDFS集群
start-dfs.sh
stop-dfs.sh
-
YARN集群
start-yarn.sh
stop-yarn.sh
-
Hadoop集群
start-all.sh
stop-all.sh
-
Hadoop Web UI页面-HDFS集群
其中node1.vbox.cn是namenode运行所在集群的主机名或者IP
如果使用主机名访问,得修改Windows中的hosts文件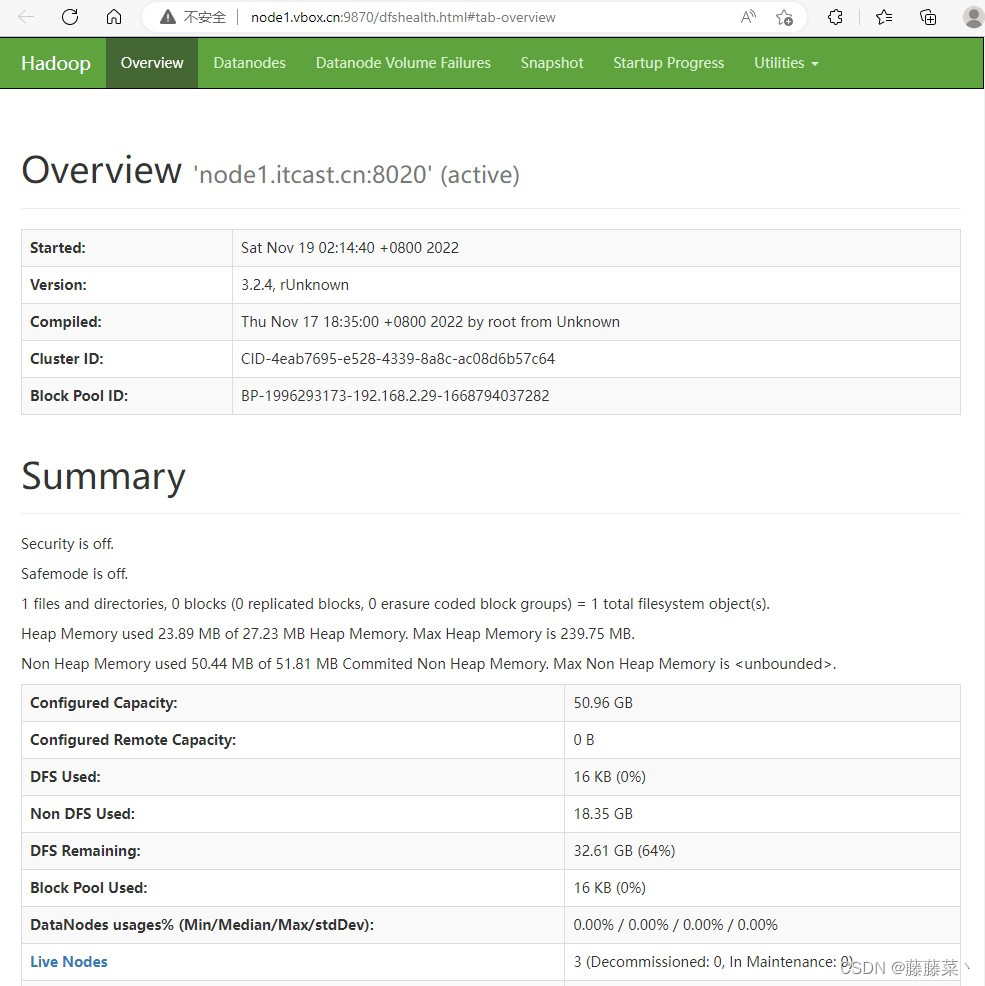
Hadoop Web UI页面-YARN集群
其中node1.vbox.cn是resourcemanager运行所在机器的主机名或者IP
如果使用主机名访问,得修改Windows中的hosts文件
-
相关阅读:
什么是 RPA?
【数据结构初阶】常见的排序算法
计算机脚本的概念,如何编写、使用脚本 (Script)?
Red Hat 8 启动没有进入GUI图形界面
诊断数据库ODX—数据库框架(基于ISO22901详解)
Vue项目
vue2.0 使用可选链操作符
java毕业设计在线视频教育平台Mybatis+系统+数据库+调试部署
[附源码]Python计算机毕业设计Django求职招聘网站
Impeller-Flutter的新渲染引擎
- 原文地址:https://blog.csdn.net/Star_SDK/article/details/127932072
