-
onnx转换TensorRT的步骤
A. 解析onnx
已有的trt不适配,需要将onnx转为trt
- parse onnx
- serialize trt
- 保存trt文件
注意:如果不使用Int8模式,onnx的parser代码几乎通用
概览
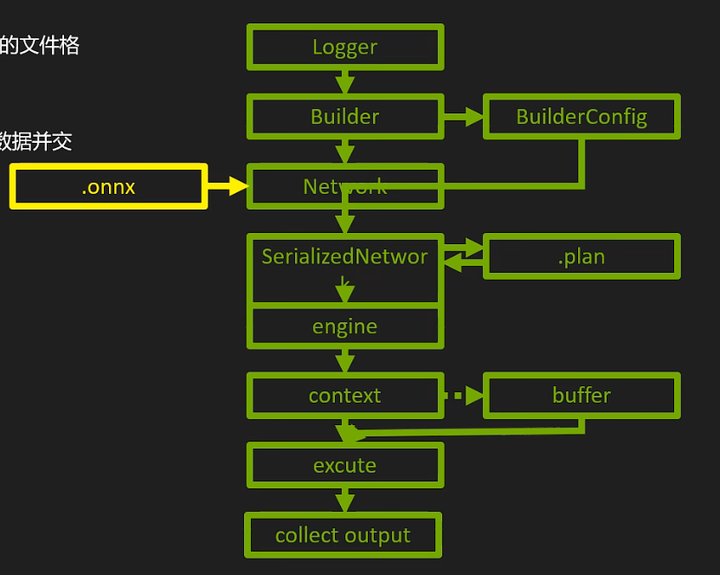
构建阶段
- 建立logger(日志)
- 建立builder(网络元数据)
- 创建network(计算图)(API独需)
- 生成序列化的网络(网络的trt内部表示)
运行阶段
- 建立engine(可执行代码)
- 创建context(gpu进程)
- buffer准备(host+device)
- 拷贝host to device
- 执行推理execute
- 拷贝device to host
- 善后
A.1 构建阶段
1. 创建logger
记录器
getTRTLogger();2. 创建builder
模型搭建的入口,网络的trt内部表示和引擎都是builder的成员方法生成的
builder.create_optimization_profile():创建用于dynamic shape输入的配置器
createInferBuilder()builder.create_network():创建tensorrt网络对象
createNetworkV2()在builderconfig下面进行细节设置
另外builder需要创建optimazation profile
在给定输入张量的最小最常见最大尺寸后,将设置的profile传给config
- auto profile = builder->createOptimizationProfile();
- profile->setDimensions();
- config->addOptimizationProfile(profile);
3. 设置builder config
进行设置网络属性
config=builder.create_builder_config()
auto config = std::unique_ptr<nvinfer1::IBuilderConfig, samplesCommon::InferDeleter>(builder->createBuilderConfig());- 指定构建期可用显存
- 设置标志位开关
- 指定校正器
- 添加用于dynamic shape输入的配置器
- config->addOptimizationProfile(profile);//添加用于dynamic shape输入的配置器
- config->setFlag();
4. 搭建network
创建network(计算图)是API独需的因为其他两种方法使用parser从onnx导入,不用一层层添加
network=builder.create_network()
在onnx-parser中一旦模型parser解析完成,network就自动填好了,成为了serialized network
onnx-parser解析
- createParser(*network, sample::gLogger.getTRTLogger();
-
- parser->parseFromFile(modelFile.c_str(), static_cast
(sample::gLogger.getReportableSeverity()));
A.2 运行阶段 runtime
5. 生成TRT内部表示-serialized network
build_serialized_network(network,config)
6. 生成engine
推理引擎,可执行的代码段
生成engine:
m_engine = std::unique_ptr<nvinfer1::ICudaEngine, samplesCommon::InferDeleter>(builder->buildEngineWithConfig(*network, *config), samplesCommon::InferDeleter());7. 创建context
context即GPU进程
创建context:
python:
engine.create_execution_context()m_context = std::unique_ptr<nvinfer1::IExecutionContext, samplesCommon::InferDeleter>(m_engine->createExecutionContext(), samplesCommon::InferDeleter());绑定输入输出
仅dynamic shape需要
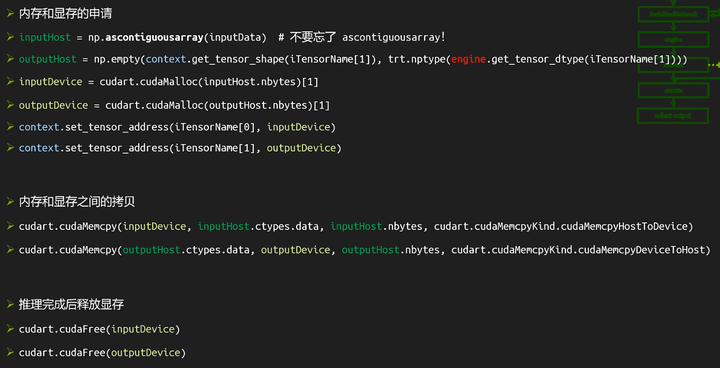
8. 准备buffer
- 内存和显存的分别申请
- 拷贝
- 释放
python:
cudart.cudaMalloc(inputHost.nbytes)[1]课程第四部分会对buffer部分的优化做介绍

9. 执行计算-execute
拷贝到cuda buffer上执行再拷贝回host,这一步一般是B.解析trt中做,但是读取onnx后也可以做

10. 序列化引擎
engine->serialize()11. 导出trt
特殊情况
遇到tensorrt不支持的onnx模型节点
- 修改源模型
- 修改onnx计算图,onnx-surgeon
- tensorrt中实现plugin
- 修改parser:修改源码,重新编译trt,因为tensorrt部分开源
B. 解析trt
已有trt,直接导入然后使用
parse TRT后得到engine和context
1. 创建logger
getTRTLogger()2. 创建cudaruntime
createInferRuntime()3. 解析/反序列化trt文件,生成引擎
runtime->deserializeCudaEngine()4. 创建context
engine->createExecutionContext()5. 使用
-
相关阅读:
Python学习笔记--数量词
机器学习如何做到疫情可视化——疫情数据分析与预测实战
2022-04-03 排查问题要知识沉淀
如何部署和配置IPv6
C/C++ 排序算法总结
关于苏州立讯公司国产替代案例(使用我公司H82409S网络变压器和E1152E01A-YG网口连接器产品)
IDE安装后配置项--类/方法注释
拓扑排序求最长路
C/C++问题:一个指针的大小是多少?怎么理解指针变量的存在
Spring Boot集成Quartz快速入门Demo
- 原文地址:https://blog.csdn.net/weixin_55035144/article/details/133745613