-
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(三)

前言
本项目依赖于Keras深度学习模型,旨在对手语进行分类和实时识别。为了实现这一目标,项目结合了OpenCV库的相关算法,用于捕捉手部的位置,从而能够对视频流和图像中的手语进行实时识别。
首先,项目使用OpenCV库中的算法来捕捉视频流或图像中的手部位置。这可以涉及到肤色检测、运动检测或者手势检测等技术,以精确定位手语手势。
接下来,项目利用CNN深度学习模型,对捕捉到的手语进行分类,经过训练,能够将不同的手语手势识别为特定的类别或字符。
在实时识别过程中,视频流或图像中的手语手势会传递给CNN深度学习模型,模型会进行推断并将手势识别为相应的类别。这使得系统能够实时地识别手语手势并将其转化为文本或其他形式的输出。
总的来说,本项目结合了计算机视觉和深度学习技术,为手语识别提供了一个实时的解决方案。这对于听觉障碍者和手语使用者来说是一个有益的工具,可以帮助他们与其他人更轻松地进行交流和理解。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。

系统流程图
系统流程如图所示。

运行环境
本部分包括 Python 环境、TensorFlow环境、 Keras环境和Android环境。
模块实现
本项目包括6个模块:数据预处理、数据增强、模型构建、模型训练及保存、模型评估和模型测试,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
在Kaggle上下载相应的数据集,下载地址为https://www.kaggle.com/ardamavi/sign-language-digits-dataset。
详见博客。
2. 数据增强
为方便展示生成图片的效果及对参数进行微调,本项目未使用keras直接训练生成器,而是先生成一个增强过后的数据集,再应用于模型训练。
详见博客。
3. 模型构建
数据加载进模型之后,需要定义模型结构,并优化损失函数。
详见博客。
4. 模型训练及保存
本部分包括模型训练和模型保存的相关代码。
1)模型训练
定义模型结构后,通过训练集训练模型,使模型能够识别手语数字。此处将使用训练集、验证集和测试集用于拟合并保存模型。在训练模型过程中,为防止训练过度造成的模型准确度下降,还使用了early stopping技术在一定条件下提前终止训练模型。相关代码如下:
from keras.callbacks import EarlyStopping def split_dataset(X, y, test_size=0.3, random_state=42): #分割数据集 X_conv=X.reshape(X.shape[0], X.shape[1], X.shape[2],1) return train_test_split(X_conv,y, stratify=y,test_size=test_size,random_state=random_state) callbacks=None X_train, X_validation, y_train, y_validation = split_dataset(X_added, y_added) X_validation, X_test, y_validation, y_test = split_dataset(X_validation, y_validation) #epochs=80 earlyStopping = EarlyStopping(monitor = 'val_loss', patience=20, verbose = 1) if callbacks is None: callbacks = [earlyStopping] #模型训练 #history = LossHistory() history = model.fit(X_train, y_train, validation_data=(X_validation, y_validation), callbacks=[earlyStopping], epochs=80, verbose=1) test_scores=model.evaluate(X_test, y_test, verbose=0) #模型评估 train_scores=model.evaluate(X_validation, y_validation, verbose=0) print("[INFO]:Train Accuracy:{:.3f}".format(train_scores[1])) print("[INFO]:Validation Accuracy:{:.3f}".format(test_scores[1])) print(plt.plot(history.history["acc"])) print(plt.plot(history.history["val_acc"])) from sklearn.metrics import confusion_matrix #生成混淆矩阵 X_CM=np.reshape(X_test,(X_test.shape[0],64,64,1)) y_pred=model.predict(X_CM) #使用整个数据集的数据进行评估 y_ture=decode_OneHotEncoding(y_test) #One-hot编码的解码 y_ture=correct_mismatches(y_ture) #图像标签的修正 y_pred=decode_OneHotEncoding(y_pred) y_pred=correct_mismatches(y_pred) confusion_matrix(y_ture, y_pred) #绘制混淆矩阵- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
训练过程如图所示。
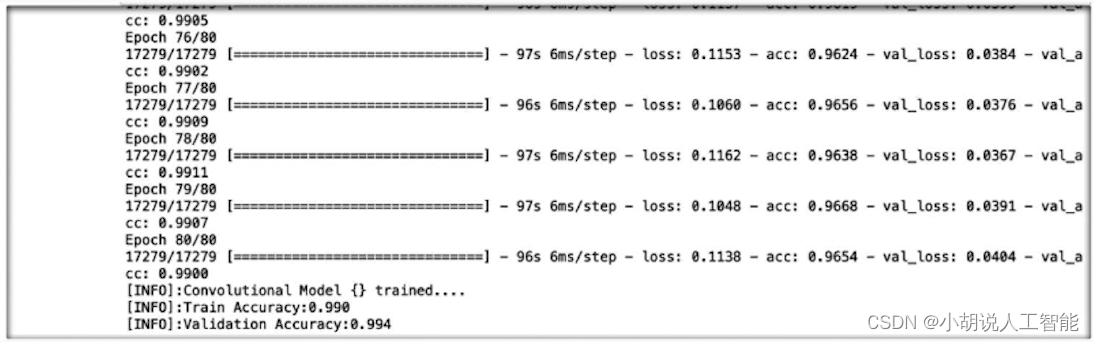
2)模型保存
为使训练的模型能够应用于Android Studio工程,将模型保存为
.pb格式。相关代码如下:from keras.models import Model from keras.layers import * from keras.models import load_model import os import tensorflow as tf def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True): #如果目的路径不存在则新建目的路径 if os.path.exists(output_dir) == False: os.mkdir(output_dir) #根据keras模型构建tensorflow模型 out_nodes = [] for i in range(len(keras_model.outputs)): out_nodes.append(out_prefix+str(i+1)) tf.identity(keras_model.output[i],out_prefix+str(i+ 1)) #将tensorflow模型写入目标文件 sess=K.get_session() from tensorflow.python.framework import graph_util, graph_io init_graph=sess.graph.as_graph_def() main_graph=graph_util.convert_variables_to_constants(sess,init_graph,out_nodes) graph_io.write_graph(main_graph,output_dir,name=model_name,as_text=False) #展示相关信息 if log_tensorboard: from tensorflow.python.tools import import_pb_to_tensorboard import_pb_to_tensorboard.import_to_tensorboard(os.path.join(output_dir,model_name),output_dir) output_dir="/Users/chenjiyan/Desktop/信息系统设计项目" #目的路径 keras_to_tensorflow(model,output_dir=output_dir,model_name="trained_model_imageDataGenerator.pb") print("MODEL SAVED")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
5. 模型评估
由于网络上缺乏手语识别相关模型,为方便在多种模型中选择最优模型,以及进行模型的调优,模型应用于安卓工程之前,需要先在PC设备上使用Python文件进行初步的运行测试,以便验证本方案的手语识别策略是否可行并选择最优的分类模型。具体步骤如下:
(1) 定义皮肤粒子的识别函数,在原图中将不符合肤色检测阈值的区域涂黑。
相关代码如下:
#导入相应包 import cv2 import numpy as np import keras from keras.models import load_model #肤色识别,函数引用自https://blog.csdn.net/qq_23149979/article/details/88569979 def skin(frame): lower = np.array([0, 40, 80], dtype="uint8") upper = np.array([20, 255, 255], dtype="uint8") converted = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) skinMask = cv2.inRange(converted, lower, upper) #构建提取阈值 skinMask = cv2.GaussianBlur(skinMask, (5, 5), 0) skin = cv2.bitwise_and(frame, frame, mask=skinMask) #将不满足条件的区域涂黑 return skin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(2)打开本地摄像头权限,加载训练好的模型,在while()函数中设定识别手部区域的时间间隔。
(3)使用肤色进行轮廓提取,将提取到的区域进行高斯滤波以及二值化,并使用find-Contour()函数进行轮廓提取,对比每个轮廓大小,并将面积小于阈值的连通域忽略。
(4)使用boundingRect()函数提取原图的手部区域后,将所提取到的区域送至训练好的模型进行分类。相关代码如下:
#主函数 def main(): capture = cv2.VideoCapture(0) #model = load_model("/Users/chenjiyan/Desktop/信息系统设计项目/trained_model_ResNet.h5") #加载模型 model = load_model("/Users/chenjiyan/Desktop/信息系统设计项目/trained_model_2.h5") #加载模型 iteator=0 while capture.isOpened(): iteator=iteator+1 if iteator>1000 : iteator=0 pressed_key = cv2.waitKey(1) _, frame1 = capture.read() frame1=cv2.flip(frame1,1) #显示摄像头 #cv2.imshow('Original',frame1) #皮肤粒子识别 frame = skin(frame1) #灰度 frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #高斯滤波 frame = cv2.GaussianBlur(frame, (5, 5), 0) #二值化 ret, frame = cv2.threshold(frame, 50, 255, cv2.THRESH_BINARY) #轮廓 _,contours,hierarchy = cv2.findContours(frame,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) #print("number of contours:%d" % len(contours)) cv2.drawContours(frame, contours, -1, (0, 255, 255), 2) #找到最大区域并填充 area = [] for i in range(len(contours)): area.append(cv2.contourArea(contours[i])) max_idx = np.argmax(area) for i in range(max_idx - 1): cv2.fillConvexPoly(frame, contours[max_idx - 1], 0) cv2.fillConvexPoly(frame, contours[max_idx], 255) #处理后显示 x, y, w, h = cv2.boundingRect(contours[max_idx]) if x>20 :x=x-20 else :x=0 if y>20 :y=y-20 else :y=0 h=h+30 w=w+50 cv2.rectangle(frame1,(x,y),(x+w, y+h),(0,255,0), 2) if iteator%5==0 : #模型预测 chepai_raw = frame1[y:y + h, x:x + w] #提取识别的矩形区域 chepai=cv2.flip(chepai_raw,1) #水平镜像翻转 cv2.imshow("Live",chepai) #显示输入图像 chepai=cv2.resize(chepai,(64,64),interpolation=cv2.INTER_CUBIC) #chepai = np.array(chepai) chepai=cv2.cvtColor(chepai,cv2.COLOR_RGB2GRAY) #转换为灰度图片 chepai=chepai/255 chepai=np.reshape(chepai,(1,64,64,1)) label_map={0:9,1:0, 2:7, 3:6, 4:1, 5:8, 6:4, 7:3, 8:2, 9:5} #result=model.predict_classes(chepai) #由于没有使用model=Sequential()序列化模型,所以不能使用predict_classes result = model.predict(chepai) result=np.argmax(result,axis=1) print(label_map[result[0]]) #显示图像 #cv2.imshow("Live",frame) #轮廓 cv2.imshow('Original',frame1) #原始图像 if pressed_key == 27: break cv2.destroyAllWindows() capture.release()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
相关其它博客
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(一)
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(二)
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(四)
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(五)
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。 -
相关阅读:
半年损失超20亿美元,区块链安全赛道被资本疯抢
SSM - Springboot - MyBatis-Plus 全栈体系(二十九)
【Axure】axure rp 导入元件库和使用,主流元件库下载使用
设计模式-桥接模式
bs4比lxml更好?爬取彩票预测并通过bs4解析
文档管理系统对会计部门的重要性
48页智慧城市规划蓝图 解决方案
【学习笔记】CF573E Bear and Bowling
基于变因子加权学习与邻代维度交叉策略的改进乌鸦算法求解单目标优化问题含Matlab代码
LeetCode_并查集_DFS_中等_2316.统计无向图中无法互相到达点对数
- 原文地址:https://blog.csdn.net/qq_31136513/article/details/133076925
