-
Doris---索引
前缀索引
doris中,对于前缀索引有如下约束:
-
他的索引键最大长度是36个字节
-
当他遇到了varchar数据类型的时候,即使没有超过36个字节,也会自动截断
-
示例1:以下表中我们定义了: user_id,age,message作为表的key ;
ColumnName Type user_id BIGINT age INT message VARCHAR(100) max_dwell_time DATETIME min_dwell_time DATETIME 那么,doris为这个表创建前缀索引时,它生成的索引键如下:
user_id(8 Bytes) + age(4 Bytes) + message(prefix 24 Bytes)-
示例2:以下表中我们定义了:age,user_name,message作为表的key
ColumnName Type age INT user_name VARCHAR(20) message VARCHAR(100) max_dwell_time DATETIME min_dwell_time DATETIME 那么,doris为这个表创建前缀索引时,它生成的索引键如下:
age(4 Bytes) +user_name(20 Bytes) 指定key的时候虽然还没有超过36个字节,但是已经遇到了一个varchar字段,它自动截断,不会再往后面取了
当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
SELECT * FROM table WHERE user_id=1829239 and age=20该查询的效率会远高于以下查询:
SELECT * FROM table WHERE age=20;在建表时,正确的选择列顺序,能够极大地提高查询效率。
Bloom Filter 索引
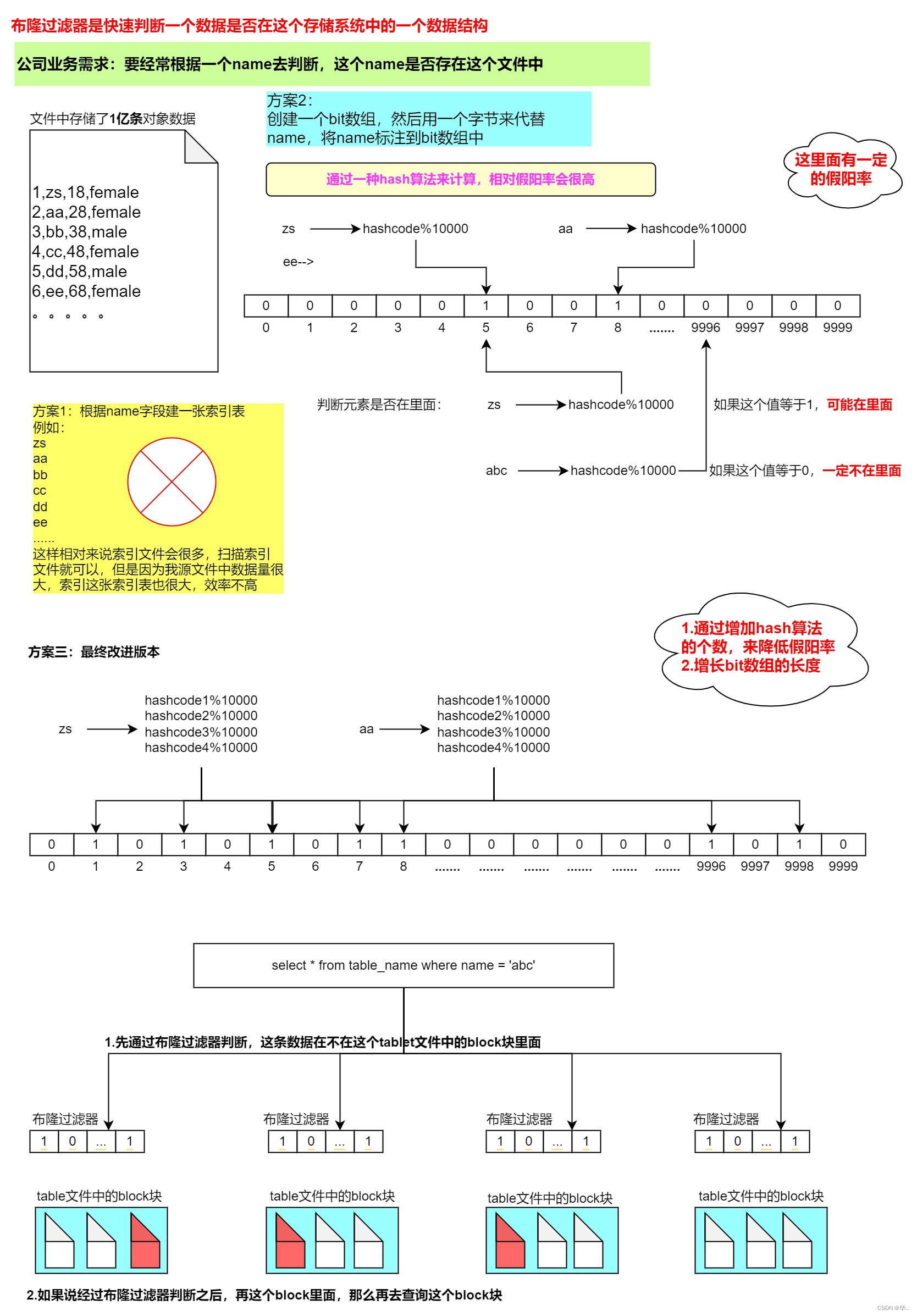
小总结:
-
Bloom Filter 本质上是一种位图结构,用于判断一个值是否存在
-
会产生小概率的误判,因为hash算法天生的碰撞
-
在doris中是以tablet为粒度创建的,给每一个tablet创建一个布隆过滤器索引
创建BloomFilter索引
-
建表的时候指定
- PROPERTIES (
- "bloom_filter_columns"="name,age,uid"
- )
-
alter修改表的时候指定
- ALTER TABLE sale_detail_bloom SET ("bloom_filter_columns" = "k1,k3");
- ALTER TABLE sale_detail_bloom SET ("bloom_filter_columns" = "k1,k4");
- ALTER TABLE sale_detail_bloom SET ("bloom_filter_columns" = "");
Doris BloomFilter适用场景
-
BloomFilter是在无法利用前缀索引的查询场景中,来加快查询速度的。
-
查询会根据该列高频过滤,而且查询条件大多是 in 和 = 过滤。
-
不同于Bitmap, BloomFilter适用于高基数列。比如UserID。因为如果创建在低基数的列上,比如 “性别” 列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义。字段随机
Doris BloomFilter使用注意事项
-
不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引。
-
Bloom Filter索引只对 in 和 = 过滤查询有加速效果。
-
可以通过explain来查看命中了哪种索引 --没办法查看
Bitmap 索引
用户可以通过创建bitmap index 加速查询

创建索引
- CREATE INDEX [IF NOT EXISTS] index_name ON table1 (siteid) USING BITMAP COMMENT 'balabala';
- create index 索引名称 on 表名(给什么字段创建bitmap索引) using bitmap COMMENT 'balabala';
- create index user_id_bitmap on sale_detail_bloom(sku_id) USING BITMAP COMMENT '使用user_id创建的bitmap索引';
查看索引
SHOW INDEX FROM example_db.table_name;删除索引
DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name;注意事项
-
bitmap 索引仅在单列上创建。
-
bitmap 索引能够应用在 Duplicate、Uniq 数据模型的所有列和 Aggregate模型的key列上。
-
bitmap 索引支持的数据类型如下:(老版本只支持bitmap类型)
TINYINT,SMALLINT,INT,BIGINT,CHAR,VARCHAR,DATE,DATETIME,LARGEINT,DECIMAL,BOOL
-
bitmap索引仅在 Segment V2 下生效(Segment V2是升级版本的文件格式)。当创建 index 时,表的存储格式将默认转换为 V2 格式
建表,并且指定索引练习
- -- 数据
- uid name age gender province term
- 1 zss 18 male jiangsu 1
- 2 lss 16 male zhejiang 2
- 3 ww 19 male jiangsu 1
- 4 zll 18 female zhejiang 3
- 5 tqq 17 female jiangsu 2
- 6 aa 18 female jiangsu 2
- 7 bb 17 male zhejiang 3
- 提要求:
- 这张表,以后需要经常按照如下条件查询
- where province = ?
- where province = ? and name = ? -- 前缀索引
- where term = ? bitmap
- where name = ? bloom
- --》如何去建索引呢? 用什么去创建前缀索引 province
- create table index_student(
- `province` varchar(255) comment "省份",
- `name` varchar(255) comment "名字",
- `uid` int comment "用户id",
- `age` int comment "年龄",
- `gender` varchar(255) comment "性别",
- `term` int comment "学期"
- )
- engine=olap
- DUPLICATE KEY(`province`,`name`,`uid`,`age`)
- distributed by hash(`uid`) buckets 2
- properties(
- "bloom_filter_columns"="name"
- );
-
-
相关阅读:
3.5 Option
逻辑回归算法概述
Qt中QTimer定时器的用法
苹果ios系统IPA包企业签名手机下载应用可以有几种方式可以下载到手机?
张跃平教授:无线电科学与技术中的因子4
Sentic GCN (2022 Knowledge-Based Systems)
2023-10-10 mysql-{mysql_rm_db}-失败后回滚-记录
使用 Docker-compose 搭建lnmp
牛血清白蛋白(BSA)修饰脂质体
理德外汇:日本央行刚刚重挫日元,美联储又有了新底气
- 原文地址:https://blog.csdn.net/m0_53400772/article/details/130902108
