-
【Redis】List类型和底层原理
List类型
1.List介绍
单键多值
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
列表的最大长度为
2^32 - 1,也即每个列表支持超过40 亿个元素。它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

1.1常用命令
**插入:**lpush/rpush … 从左边/右边插入一个或多个值。
**取数据:**lpop/rpop 从左边/右边吐出一个值。值在键在,值取完键销毁。

索引
- lrange
按照索引下标获得元素(从左到右)

- lrange mylist 0 -1 0左边第一个,-1右边第一个,(0 -1表示获取所有)
- lindex 按照索引下标获得元素(从左到右)

**llen 获得列表长度 **
linsert <key> before <value> <newvalue>在<value>的后面插入<newvalue>插入值 lrem <key><n><value>从左边删除n个value(从左到右) lset<key> <index> <value>将列表key下标为index的值替换成value- 1
- 2
- 3
- 4
- 5
2.List底层实现
list底层数据结构为ziplist和quicklist。
快速列表quicklistquicklist = 链表+ziplist
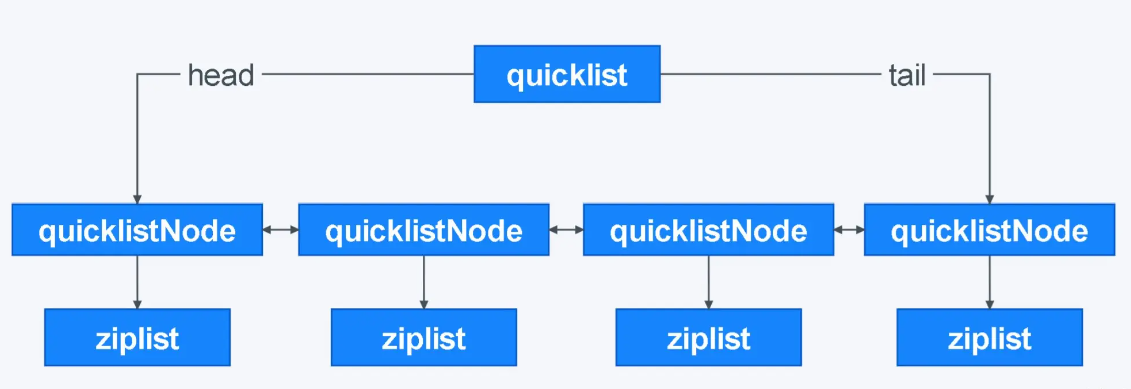
- 在列表元素较少的情况下,会使用一块连续的内存存储,**这个结构就是ziplist,**即压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存
- 当数据量变多时,会改成quicklist
3.ziplist剖析
3.1ziplist结构
压缩列表(ziplist)是哈希键的底层实现之一。它是经过特殊编码的双向链表,和整数集合(intset)一样,是为了提高内存的存储效率而设计的。当保存的对象是小整数值,或者是长度较短的字符串,那么redis就会使用压缩列表来作为哈希键的实现。
ziplist的结构
struct ziplist<T> { int32 zlbytes; // 整个压缩列表占用字节数 int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点 int16 zllength; // 元素个数 T[] entries; // 元素内容列表,挨个挨个紧凑存储 int8 zlend; // 标志压缩列表的结束,值恒为 0xFF }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

- zlbytes:占4个字节,记录整个压缩列表占用的内存字节数。
- zltail_offset:占4个字节,记录压缩列表尾节点entryN距离压缩列表的起始地址的字节数。
- zllength:占2个字节,记录了压缩列表的节点数量。
- entry[1-N]:长度不定,保存数据。
- zlend:占1个字节,保存一个常数255(0xFF),标记压缩列表的末端。
实际上redis并没有提供一个结构体来保存压缩列表的信息,而是用了一组宏对压缩列表进行管理
// ziplist的成员宏定义 // (*((uint32_t*)(zl))) 先对char *类型的zl进行强制类型转换成uint32_t *类型, // 然后在用*运算符进行解引用取内容运算,此时zl能访问的内存大小为4个字节。 //zl的类型为char*类型 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) //将zl定位到前4个字节的bytes成员,记录这整个压缩列表的内存字节数 #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) //将zl定位到4字节到8字节的tail_offset成员,记录着压缩列表尾节点距离列表的起始地址的偏移字节量 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) //将zl定位到8字节到10字节的length成员,记录着压缩列表的节点数量 #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) //压缩列表表头(以上三个属性)的大小10个字节 #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) //返回压缩列表首节点的地址 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) //返回压缩列表尾节点的地址 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1) //返回end成员的地址,一个字节。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

3.2创建一个空的ziplist
unsigned char *ziplistNew(void) { //创建并返回一个新的压缩列表 //ZIPLIST_HEADER_SIZE是压缩列表的表头大小,1字节是末端的end大小 unsigned int bytes = ZIPLIST_HEADER_SIZE+1; unsigned char *zl = zmalloc(bytes); //为表头和表尾end成员分配空间 ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); //将bytes成员初始化为bytes=11 ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); //空列表的tail_offset成员为表头大小为10 ZIPLIST_LENGTH(zl) = 0; //节点数量为0 zl[bytes-1] = ZIP_END; //将表尾end成员设置成默认的255 return zl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- intrev32ifbe()是封装的宏,用来根据主机的字节序按需要进行字节大小端的转换。
3.3ziplist的元素节点结构
redis对于压缩列表节点定义了一个zlentry的结构,用来管理节点的所有信息。
typedef struct zlentry { /* */ } zlentry;- 1
- 2
- 3
- 4
虽然定义了这个结构体,但是Redis并没有使用zlentry对元素列表进行管理。因为该结构体存储短字符串和小整数太浪费空间。【一个结构体在32位机下的大小是28字节,意味着管理一个元素要多付出28字节内存】
因此,在redis中,并没有定义结构体来进行操作,也是定义了一些宏,压缩列表的节点真正的结构如下图所示:

- prevlen:记录前驱节点的长度(保证了从后往前遍历)
prevlen属性的大小与前驱节点大小有关:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
- encoding:记录当前节点的value成员的数据类型以及长度。
- entry_data:保存字节数组或整数数据。
struct entry { int<var> prevlen; // 前一个 entry 的字节长度 int<var> encoding; // 元素类型编码 var entry_data; // 元素内容 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.4ziplisqt的连锁更新
ziplist的底层结构图

压缩列表除了查找复杂度高的问题,还存在一个问题,连锁更新问题:
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
前面提到,prevlen属性的大小与前驱节点大小有关:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
假设当前ziplist有多个大小在250~253字节中间的元素,元素的prevlen属性大小为1字节

这时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,即新节点将成为 e1 的前置节点,因为ziplist是一段连续的内存空间,所以后续的元素都需要更新:
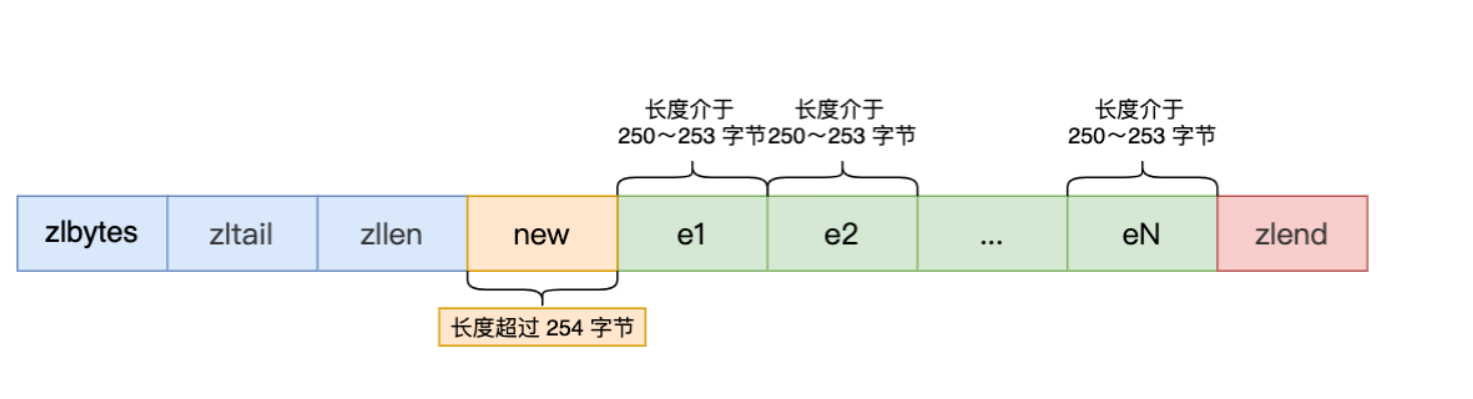
因为 e1 节点的 prevlen 属性只有 1 个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作,并将 e1 节点的 prevlen 属性从原来的 1 字节大小扩展为 5 字节大小,修改后e1的大小也大于了253字节,所以e2的prevlen大小也会被修改为5字节…

这种在特殊情况下产生的连续多次空间扩展操作就叫做「连锁更新」
3.5ziplist的缺陷
ziplist是一段连续的内存空间,所以对ziplist空间扩展会导致空间的重新分配和拷贝。
**如果发生了连锁更新,**可能会导致多次空间扩展和拷贝,这就会直接影响到压缩列表的访问性能。
4.quicklist剖析
quickList就是一个标准的双向链表的配置,有head 有tail;每一个节点是一个quicklistNode,包含prev和next指针。而每一个quicklistNode 包含 一个ziplist,*zp 压缩链表里存储键值。所以quicklist是对ziplist进行一次封装,使用小块的ziplist来既保证了少使用内存,也保证了性能。
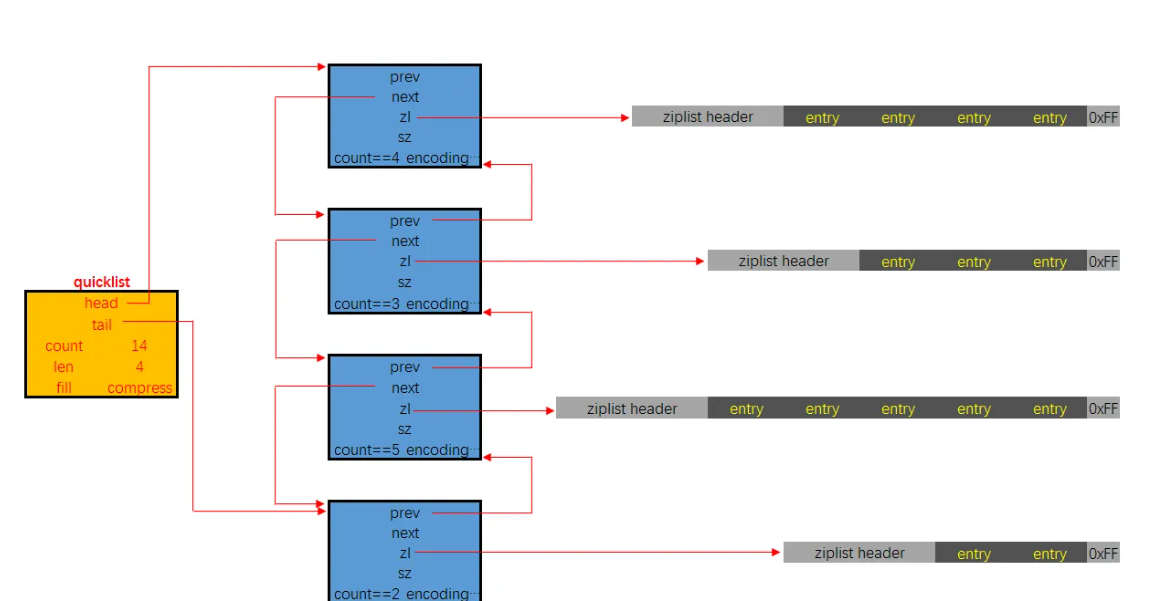
4.1quicklist表头结构
typedef struct quicklist { //指向头部(最左边)quicklist节点的指针 quicklistNode *head; //指向尾部(最右边)quicklist节点的指针 quicklistNode *tail; //ziplist中的entry节点计数器 unsigned long count; /* total count of all entries in all ziplists */ //quicklist的quicklistNode节点计数器 unsigned int len; /* number of quicklistNodes */ //保存ziplist的大小,配置文件设定,占16bits int fill : 16; /* fill factor for individual nodes */ //保存压缩程度值,配置文件设定,占16bits,0表示不压缩 unsigned int compress : 16; /* depth of end nodes not to compress;0=off */ } quicklist;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
quicklist节点结构
typedef struct quicklistNode { struct quicklistNode *prev; //前驱节点指针 struct quicklistNode *next; //后继节点指针 //不设置压缩数据参数recompress时指向一个ziplist结构 //设置压缩数据参数recompress指向quicklistLZF结构 unsigned char *zl; //压缩列表ziplist的总长度 unsigned int sz; /* ziplist size in bytes */ //ziplist中包的节点数,占16 bits长度 unsigned int count : 16; /* count of items in ziplist */ //表示是否采用了LZF压缩算法压缩quicklist节点,1表示压缩过,2表示没压缩,占2 bits长度 unsigned int encoding : 2; /* RAW==1 or LZF==2 */ //表示一个quicklistNode节点是否采用ziplist结构保存数据,2表示压缩了,1表示没压缩,默认是2,占2bits长度 unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */ //标记quicklist节点的ziplist之前是否被解压缩过,占1bit长度 //如果recompress为1,则等待被再次压缩 unsigned int recompress : 1; /* was this node previous compressed? */ //测试时使用 unsigned int attempted_compress : 1; /* node can't compress; too small */ //额外扩展位,占10bits长度 unsigned int extra : 10; /* more bits to steal for future usage */ } quicklistNode;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
基于上面两个结构体,quicklist的大致结构为下图:

5.List的应用场景----消息队列
消息队列在存取消息时,需要满足下面三个条件:消息保序、处理重复的消息和保证消息的可靠性。
5.1保证消息保序
List可以基于生产者消费者模型保证消息保序
List 本身就是按先进先出的顺序对数据进行存取的,所以,如果使用 List 作为消息队列保存消息的话,就已经能满足消息保序的需求了。

- 生产者使用
LPUSH key value[value...]将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息。 - 消费者使用
RPOP key依次读取队列的消息,先进先出。
消费者读取数据时,有一个潜在的性能风险点
在生产者往 List 中写入数据时,List 并不会主动地通知消费者有新消息写入,如果消费者想要及时处理消息,就需要在程序中不停地调用
RPOP命令。即便是消息已经处理完了,也会不断的调用RPOP命令。这就会导致消费者程序的 CPU 一直消耗在执行 RPOP 命令上,带来不必要的性能损失。
- 为了解决这个问题,Redis提供了一个
BRPOP命令,BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。避免了CPU不断调用RPOP命令的性能消耗。

5.2处理重复的消息
消费者要实现重复消息的判断,需要 2 个方面的要求:
- 每个消息都有一个全局的 ID。
- 消费者要记录已经处理过的消息的 ID。当收到一条消息后,消费者程序就可以对比收到的消息 ID 和记录的已处理过的消息 ID,来判断当前收到的消息有没有经过处理。如果已经处理过,那么,消费者程序就不再进行处理了。
但是 List 并不会为每个消息生成 ID 号,所以我们需要自行为每个消息生成一个全局唯一ID,生成之后,我们在用 LPUSH 命令把消息插入 List 时,需要在消息中包含这个全局唯一 ID。
LPUSH mq "111000102:stock:99"- 1
5.3保证消息的可靠性
如果消费者程序在处理消息的过程出现了故障或宕机,就会导致消息没有处理完成,那么,消费者程序再次启动后,就没法再次从 List 中读取消息了。
为了留存消息,List 类型提供了
brpoplpush命令,这个命令的作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存作为备份。5.List作为消息队列的缺陷
- List不支持多个消费者消费同一条信息。
- lrange
-
相关阅读:
Android 桌面小组件使用
Java 异常处理通关指南
循环结构 while dowhile for
kafka中partition数量与消费者对应关系以及Java实践(Spring 版本)
10-Element UI
某云负载均衡获取客户端真实IP的问题
精准诊断,精确治疗,智芯传感ZXPA侵入式压力传感器为心血管疾病患者带来福音
Chrome 103支持使用本地字体,纯前端导出PDF优化
docker笔记
y131.第七章 服务网格与治理-Istio从入门到精通 -- Istio Security基础(十七)
- 原文地址:https://blog.csdn.net/qq_53893431/article/details/128146831
