-
kafka中partition数量与消费者对应关系以及Java实践(Spring 版本)


kafka是由Apache软件基金会开发的一个开源流处理平台。kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。分区理解
kafka中partition类似数据库中的分表数据,可以起到水平扩展数据的目的,比如有a,b,c,d,e,f 6个数据,某个topic有两个partition,一般情况下partition-0存储a,c,e3个数据,partition-1存储b,d,f另外3个数据。
消费者组数量的不同以及partition数量的不同对应着不同的消费情况,下面分别进行梳理之:
一、单播模式,只有一个消费者组
1. topic只有1个partition
(1)topic只有1个partition,该组内有多个消费者时,此时同一个partition内的消息只能被该组中的一个consumer消费。当消费者数量多于partition数量时,多余的消费者是处于空闲状态的,如图1所示。topic,pis-business只有一个partition,并且只有1个group,G1,该group内有多个consumer,只能被其中一个消费者消费,其他的处于空闲状态。

2. topic有多个partition,该组内有多个消费者
该topic有多个partition,该组内有多个消费者,
-
第一种场景:
比如pis-business 有3个partition,该组内有2个消费者,那么可能就是C0对应消费p0,p1内的数据,c1对应消费p2的数据; -
第二种场景:
如果有3个消费者,就是一个消费者对应消费一个partition内的数据了这种模式在集群模式下使用是非常普遍的,比如我们可以起3个服务,对应的topic设置3个partiition,这样就可以实现并行消费,大大提高处理消息的效率。
二、广播模式,多个消费者组
如果想实现广播的模式就需要设置多个消费者组,这样当一个消费者组消费完这个消息后,丝毫不影响其他组内的消费者进行消费,这就是广播的概念。
2.1. 多个消费者组,1个partition
该topic内的数据被多个消费者组同时消费,当某个消费者组有多个消费者时也只能被一个消费者消费,如图所示:

2.2. 多个消费者组,多个partition
该topic内的数据可被多个消费者组多次消费,在一个消费者组内,每个消费者又可对应该topic内的一个或者多个partition并行消费,如图所示:
三、Java实践-producer
这里使用Java服务进行实践,模拟3个parition,然后同一个组内有3个消费者的情况:
3.1. 引入依赖
<!--kafka-spring 集成--> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.3.10.RELEASE</version> </dependency> <!--自定义kafka序列化消息和反序列化消息用途--> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.5.4</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.83</version> </dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.2. 导入配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:context="http://www.springframework.org/schema/context" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- 1.定义producer的参数 --> <bean id="producerProperties" class="java.util.HashMap"> <constructor-arg> <map> <!-- 配置kafka的broke --> <entry key="bootstrap.servers" value="192.168.105.125:9092,192.168.105.129:9092,192.168.105.130:9092"/> <!-- 配置组--> <entry key="max.request.size" value="10000"/> <entry key="acks" value="-1"/> <entry key="retries" value="3"/> <entry key="batch.size" value="4096"/> <entry key="linger.ms" value="10000"/> <entry key="buffer.memory" value="40960"/> <entry key="key.serializer" value="org.apache.kafka.common.serialization.StringSerializer"/> <entry key="value.serializer" value="com.gblfy.kafka.encode.EncodeingKafka"/> <!--自定义的kafka反序列化类--> </map> </constructor-arg> </bean> <!-- 2.创建 kafkaTemplate 需要使用的 producerFactory Bean --> <bean id="producerFactory" class="org.springframework.kafka.core.DefaultKafkaProducerFactory"> <constructor-arg ref="producerProperties"/> </bean> <!-- 3.创建 kafkaTemplate Bean,使用的时候只需要注入这个bean,即可使用kafkaTemplate的 send 消息方法 --> <bean id="kafkaTemplate" class="org.springframework.kafka.core.KafkaTemplate"> <constructor-arg ref="producerFactory"/> <constructor-arg name="autoFlush" value="true"/> <property name="defaultTopic" value="pis-business"/> </bean> </beans>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
3.3. kafka工具类
package com.gblfy.kafka; import org.apache.kafka.clients.producer.RecordMetadata; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.support.SendResult; import org.springframework.stereotype.Service; import org.springframework.util.concurrent.ListenableFuture; /** * kafka发送工具类 * * @author gblfy * @date: 2022-11-18 **/ @Service public class KafkaProducerService { @Autowired private KafkaTemplate kafkaTemplate; // @Autowired // private xxxMapper xxxMMapper;TODO 数据库轨迹Mapper /** * @param topic topic分区 * @param message kafka消息 * @return 发送Kafka成功并返回请求响应信息 */ public void sendMessageForgetResult(String topic, String message) { try { System.out.println("---------topic-------" + topic); ListenableFuture<SendResult<String, String>> listenableFuture = kafkaTemplate.send(topic, message); SendResult<String, String> sendResult = listenableFuture.get(); RecordMetadata recordMetadata; if (sendResult != null) { recordMetadata = sendResult.getRecordMetadata(); System.out.println("发送成功!"); System.out.println("topic:" + recordMetadata.topic()); System.out.println("partition:" + recordMetadata.partition()); System.out.println("offset:" + recordMetadata.offset()); } // TODO 设置消息发送状态 // TODO 更新数据落库 } catch (Exception e) { e.printStackTrace(); System.out.println("--------kafka发送失败---------!"); // TODO 设置消息发送状态 // TODO 更新数据落库 } System.out.println("发送成功!"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
3.4. 发送消息
package com.gblfy.producer; import com.alibaba.fastjson.JSON; import com.gblfy.kafka.KafkaProducerService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import java.util.HashMap; import java.util.Map; /** * 监听类的实现 * * @author gblfy * @date 2022-11-18 */ @RestController @RequestMapping("kafka") public class KafkaProducer { @Autowired private KafkaProducerService kafkaProducerService; //kafka发送的主题 public static final String KAFKA_TOPIC = "pis-business"; /** * 消息发送 * http://localhost:8080/springmvc-producer/kafka/producer?value=123 */ @GetMapping("producer") public String producer(@RequestParam String value) { Map map = new HashMap<>(); map.put("key", value); String message = JSON.toJSONString(map); // 发送kafka kafkaProducerService.sendMessageForgetResult(KAFKA_TOPIC, message); return "已发送"; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
3.5. 消息序列化
package com.gblfy.kafka.encode; import com.gblfy.kafka.BeanUtils; import org.apache.kafka.common.serialization.Serializer; import org.springframework.stereotype.Component; import java.util.Map; @Component public class EncodeingKafka implements Serializer<Object> { @Override public void configure(Map configs, boolean isKey) { } @Override public byte[] serialize(String topic, Object data) { return BeanUtils.bean2Byte(data); } /* * producer调用close()方法是调用 */ @Override public void close() { System.out.println("EncodeingKafka is close"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
四、Java实践-producer
这里使用Java服务进行实践,模拟3个parition,然后同一个组内有3个消费者的情况:
4.1. 引入依赖
<!--kafka-spring 集成--> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.3.10.RELEASE</version> </dependency> <!--自定义kafka序列化消息和反序列化消息用途--> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.5.4</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.83</version> </dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4.2. 导入配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <context:annotation-config/> <!-- 1.定义 consumer 的参数 --> <bean id="consumerProperties1" class="java.util.HashMap"> <constructor-arg> <map> <entry key="bootstrap.servers" value="192.168.105.125:9092,192.168.105.129:9092,192.168.105.130:9092"/> <entry key="group.id" value="pis "/> <entry key="enable.auto.commit" value="false"/> <entry key="request.timeout.ms" value="65000"/> <entry key="session.timeout.ms" value="63000"/> <entry key="key.deserializer" value="org.apache.kafka.common.serialization.StringDeserializer"/> <entry key="value.deserializer" value="com.gblfy.kafka.encode.DecodeingKafka"/> <entry key="auto.offset.reset" value="earliest"/><!--后加上的属性--> </map> </constructor-arg> </bean> <!-- 2.创建 consumerFactory bean --> <bean id="consumerFactory1" class="org.springframework.kafka.core.DefaultKafkaConsumerFactory"> <constructor-arg ref="consumerProperties1"/> </bean> <!-- 3.配置消费端 Kafka 监听实现类(自己实现) --> <bean id="kafkaConsumerListener" class="com.gblfy.kafka.listener.KafkaConsumerListener"/> <!-- 4.消费者容器配置 --> <bean id="containerProperties1" class="org.springframework.kafka.listener.config.ContainerProperties"> <constructor-arg name="topics"> <list> <!-- 这里可以是多个主题--> <value>pis-business</value> </list> </constructor-arg> <property name="messageListener" ref="kafkaConsumerListener"/> <!-- 设置如何提交offset 手动提交 --> <property name="ackMode" value="MANUAL_IMMEDIATE"/> </bean> <!-- 5.消费者并发消息监听容器 --> <bean id="messageListenerContainer" class="org.springframework.kafka.listener.KafkaMessageListenerContainer"> <constructor-arg ref="consumerFactory1"/> <constructor-arg ref="containerProperties1"/> </bean> <!-- 消费者容器配置信息 --> <bean id="kafkaConsumerProperties1" class="org.springframework.kafka.listener.config.ContainerProperties"> <constructor-arg name="topics" value="pis-bussiness"/><!--topic对应的名称--> <property name="messageListener" ref="kafkaConsumerListener"/> <!-- 设置如何提交offset 手动提交 --> <property name="ackMode" value="MANUAL_IMMEDIATE"/> </bean> <bean id="ListenerContainer1" class="org.springframework.kafka.listener.ConcurrentMessageListenerContainer"> <constructor-arg ref="consumerFactory1"/> <constructor-arg ref="kafkaConsumerProperties1"/> <!--禁止自动启动--> <!--<property name="autoStartup" value="false" />--> <property name="concurrency" value="1"/> <!--单线程消费 --> </bean> </beans>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
4.3. kafka监听
package com.gblfy.kafka.listener; import com.alibaba.fastjson.JSONObject; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.kafka.listener.AcknowledgingMessageListener; import org.springframework.kafka.support.Acknowledgment; /** * 监听类的实现 * * @author gblfy * @date 2022-11-18 */ public class KafkaConsumerListener implements AcknowledgingMessageListener<String, String> { @Override public void onMessage(ConsumerRecord<String, String> data, Acknowledgment acknowledgment) { String topic = data.topic(); System.out.println("消费的topic主题:-----" + topic); System.out.println("消费-----" + data.partition() + "分区的消息"); System.out.println("offset-----" + data.offset()); System.out.println("message-----" + data.value()); /*获取kafka数据*/ JSONObject pardeData = (JSONObject) JSONObject.parse(data.value()); String value1 = pardeData.getString("key"); System.out.println("value1-----" + value1); // TODO 业务逻辑处理 //消费完成后提交offset if (acknowledgment != null) { acknowledgment.acknowledge(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
4.4. kafka消息反序列化
package com.gblfy.kafka.encode; import com.gblfy.kafka.BeanUtils; import org.apache.kafka.common.serialization.Deserializer; import org.springframework.stereotype.Component; import java.util.Map; @Component public class DecodeingKafka implements Deserializer<Object> { @Override public void configure(Map<String, ?> configs, boolean isKey) { } @Override public Object deserialize(String topic, byte[] data) { return BeanUtils.byte2Obj(data); } @Override public void close() { } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
4.5. 通用工具类
生产者和消费者一样
package com.gblfy.kafka; import java.io.*; public class BeanUtils { private BeanUtils() {} /** * 对象序列化为byte数组 * * @param obj * @return */ public static byte[] bean2Byte(Object obj) { byte[] bb = null; try (ByteArrayOutputStream byteArray = new ByteArrayOutputStream(); ObjectOutputStream outputStream = new ObjectOutputStream(byteArray)){ outputStream.writeObject(obj); outputStream.flush(); bb = byteArray.toByteArray(); } catch (IOException e) { e.printStackTrace(); } return bb; } /** * 字节数组转为Object对象 * * @param bytes * @return */ public static Object byte2Obj(byte[] bytes) { Object readObject = null; try (ByteArrayInputStream in = new ByteArrayInputStream(bytes); ObjectInputStream inputStream = new ObjectInputStream(in)){ readObject = inputStream.readObject(); } catch (Exception e) { e.printStackTrace(); } return readObject; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
五、集群测试
5.1. 创建kafka主题
创建kafka主题名称为pis-business
分区3个 副本数量3个kafka-topics.sh -zookeeper 192.168.105.125:2181 --create --partitions 3 --replication-factor 3 --topic pis-business- 1
5.2. 启动一个生产者

5.3. 启动3个消费者
这里使用同一个消费者项目,启动一个项目后修改端口依次启动,端口分别为8081、082、8083

5.4. 发送消息测试
-
发送3笔消息
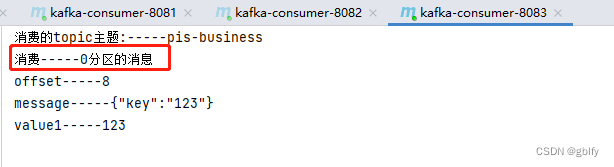
消费者1 端口8081 消费的分区2的消息

消费者2 端口8082消费的分区1的消息

消费者3 端口8083 消费的分区0的消息
-发送5笔消息
清空控制台,重新发送5笔消息测试
消费者1 端口8081 消费的分区2的1笔消息

消费者2 端口8082消费的分区1的2笔消息
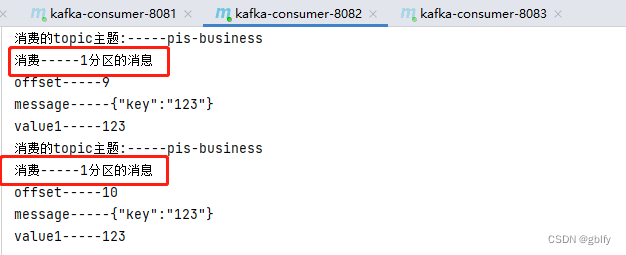
消费者3 端口8083 消费的分区0的2笔消息

5.5. 数据分析总结
从第二轮测试结果数据分析来看:
生产者:投递5笔消息,有2笔投递到了分区模型0中,有2笔投递到了分区模型1中,有1笔投递到了分区模型2中。消费者:
消费1端口8081分区模型2中1笔消息,
消费2端口8082分区模型1中2笔消息,
消费3端口8083分区模型0中2笔消息,
从消费者消费来看,是按照分区模型来消费的,起到了均衡消费的效果,目前没有出现,一个消费者消费不同分取模型中的消息对吧。- 总结
所以在微服务的集群中,我们可以通过给topic设置多个partition,然后让每一个实例对应消费1个partition的数据,从而实现并行的处理数据,可以显著地提高处理消息的速度。
六、命令版本集群验证
6.1. 创建kafka主题
创建kafka主题名称为pis-business
分区3个 副本数量3个kafka-topics.sh -zookeeper 192.168.105.125:2181 --create --partitions 3 --replication-factor 3 --topic pis-business- 1
6.2. 发送5笔消息
kafka-console-producer.sh --broker-list 192.168.105.125:9092 --topic pis-business- 1
消息内容
1 2 3 4 5- 1
- 2
- 3
- 4
- 5

6.3. 克隆3个终端窗口模拟消费者
bin/kafka-console-consumer.sh --bootstrap-server 192.168.105.125:9092 --from-beginning --topic pis-business- 1



6.4. 数据分析总结
消费者1消费消息数量2笔,消息内容为2和5
消费者2消费消息数量2笔,消息内容为1和4
消费者3消费消息数量1笔,消息内容为36.5. 总结
所以在微服务的集群中,我们可以通过给topic设置多个partition,然后让每一个实例对应消费1个partition的数据,从而实现并行的处理数据,可以显著地提高处理消息的速度。
6.6. 使用kafkaManager为topic增加partition数量

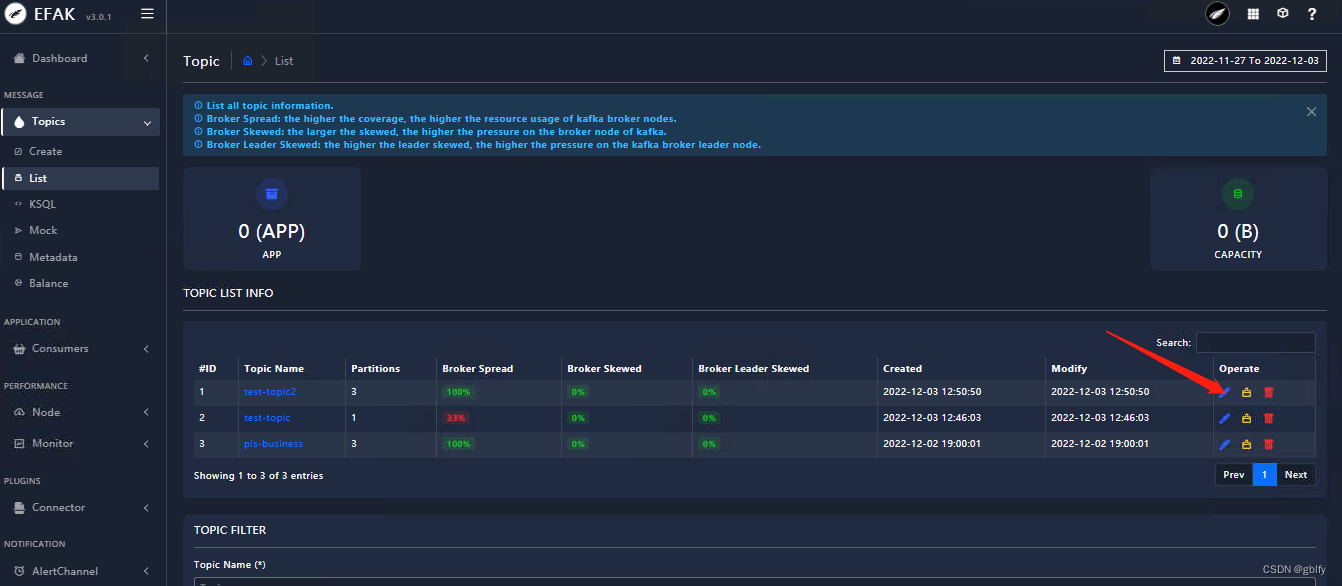

首先点击 Add Partitions 增加partition的数量,然后点击Generate Partition Assignments ,此时系统自动会为每个分区下的副本分配broker, 最后点击 Reassign Partitions,可以平衡集群的负载 。
-
-
相关阅读:
Matlab写入nc文件遇到‘Start+count exceeds dimension bound (NC_EEDGE)‘问题的解决办法
基于Python的大区域SPI标准降水指数自动批量化处理
运动想象 (MI) 分类学习系列 (16) :LMDA-Net
java基础10题
21、Flink 大状态调优
Vue整合Markdown组件+SpringBoot文件上传+代码差异对比
招投标系统简介 招投标系统源码 java招投标系统 招投标系统功能设计
【CT】LeetCode手撕—42. 接雨水
MySQL
四大场景化模型算法搞定贷中营销场景|实操与效果比对
- 原文地址:https://blog.csdn.net/weixin_40816738/article/details/128154237
