-
CS224W 7 A General Perspective on Graph Neural Networks
目录
Classical GNN Layers: GraphSAGE
A General GNN Framework
1.GNN Layer = (1)Message +(2) Aggregation
GCN,GraphSAGE,GAT
2.Connect GNN layers into a GNN
依次堆叠GNN layers
添加skip connection的方法
3.Graph augmentation
Graph feature augmentation
Graph structure augmentation
4. 学习目标函数
监督/无监督的目标函数
节点/边/图水平的目标函数

A single GNN layer
基本形式
GNN layer将一组vectors(v的邻居节点L-1层的嵌入 与 节点v L-1层的嵌入)压缩为单个vector

为什么message要包含节点自身v L-1层的嵌入:否则节点v本身的信息会丢失
包含两部分: Message(节点嵌入的转换)与Aggregation(聚合来自不同节点的message)


Classical GNN Layers: GCN
Message:每个节点u,由节点v的度归一化

Aggregation:对来自所有邻居节点的messages求和,再应用激活函数

Classical GNN Layers: GraphSAGE
1.GraphSAGE的Message在AGG(.)中实现。
2.包含两个阶段的Aggregation:聚合邻居节点;聚合节点自身信息

3.AGG方式多样

4.L2Normalization
对每一层的节点使用L2 Normalization
- 没有L2 Normalization,不同节点的embedding有不同规模
- 在有些情况下,加入L2 Normalization后会有性能的提升
- 在L2 Normalization之后,所有向量有相同的L2-norm,都为1

Classical GNN Layers: GAT
动机
在GCN与GraphSAGE中,权重因子
 ,是基于图的结构特性(node degree)决定的,所有节点v的邻居节点u都有相同的重要性。
,是基于图的结构特性(node degree)决定的,所有节点v的邻居节点u都有相同的重要性。不是所有邻居节点都有相同的重要性,所有计算节点的embedding时应遵顼attention策略,为不同邻居节点指定不同的weights。

Attenion Mechanism
1.基于注意力机制计算节点l层的embedding
(1)首先计算注意力系数(attention coefficients)
 。使用注意力机制a,基于节点对u、v的messages计算它们的表明了u的message对节点v的重要性
。使用注意力机制a,基于节点对u、v的messages计算它们的表明了u的message对节点v的重要性
(2)计算最终的attention weight
 ——使用softmax归一化
——使用softmax归一化(3)基于attention weight
加权求和计算节点v的第l层的embedding
2.注意力机制a的形式
a可以简单的为单层神经网络
a具有要训练的参数,和其它参数联合训练,例如
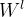

Multi-head attention
多头注意力机制不同组的α由不同的function a组成,最后计算节点v的第l层的embedding,可以拼接或者求和。

Attenion Mechanism的优点
允许为不同邻居节点指定不同的重要性值
计算效率高。可以从图中所有边并行的计算attentional coefficients;Aggregation可以对所有节点并行计算。
只关注局部邻居节点。

ps:重要性可能不对称,我给你的信息很重要,但你的信息对我来说不重要
GNN Layer in Practice
可以在单层GNN layer里添加现代的深度学习模块,非常有效。

1.BN
对embedding的每一个维度进行normilzation

2.Dropout
Dropout用于message function里的线性层

3.Activation

Stacking Layers of a GNN
有两种将GNN layers连接成GNNd 方法:依次堆叠layer;添加skip connections
Stack layers sequentially
结构

Over-smoothing Problem
不是GNN layers堆叠的越深越好
1.定义
所有节点的embeddings收敛到相同的值,但是期望的是节点有不同的embedding。
2.原因
Receptive field:决定感兴趣的节点的embedding的节点集。当K层GNN时,每个节点的Receptive field有K-hop的neighborhood。
如果两个节点的Receptive field高度重叠,那么它们的embeddings高度相似。
堆叠许多GNN layers——节点有highly overlapped receptive field——节点embeddings高度相似——出现Over-smoothing Problem

3.解决方法
(1)谨慎加GNN layers
不像NN(例如CNN),加入更多的GNN layers不总是有帮助
step1:分析解决问题必要的receptive field
step2:设置GNN layers的数量比receptive field稍微多一点
(2)Expressive Power for Shallow GNNS——当GNN layers很少时增加表达能力
- 方法1:增加每一层GNN layer的表达力
原来的每个transformation或者aggregation都是one linear layer,可以将transformation或者aggregation变为DNN

- 方法2:添加不传递message的layers
一个GNN不需要只包含GNN layers,例如,可以在GNN layers之前或之后添加MLP作为预处理层或者后处理层。预处理在编码node features时很重要;后处理在基于embeddings推理或转换时很重要。

(3)Add skip connections in GNNs——当问题需要许多GNN layers时
从过度平滑观察:在早期的GNN层的节点嵌入有时可以更好地区分节点
解决方案:我们可以通过在 GNN 中添加shortcuts,增加早期层对最终节点嵌入的影响。

skip connections创造了混合模型:混合两个不同的层或者模型——上一层和当前层message的加权和


-
相关阅读:
fastadmin笔记,fastadmin表格功能
linux——信号
实现一个类 支持100个线程同时向银行账户存入一元钱
Opengl Fence 内部实现
加速鸿蒙生态共建,蚂蚁mPaaS助力鸿蒙原生应用开发创新
C++阶段03笔记01【内存分区模型、引用、函数提高】
PAT A1014 Waiting in Line
【深度学习】多任务学习 多个数据集 数据集漏标
《痞子衡嵌入式半月刊》 第 49 期
C# 方法参数out(实现int.Tyrparse()方法)
- 原文地址:https://blog.csdn.net/zhangxiaohuiNO1/article/details/128032400