-
图床云存储项目课程随堂笔记
这个项目属实重量级,第一遍学习的过程比较懵,只是记录一下随堂笔记。后面理解了项目后端代码流程,再细写几篇博客归纳。
基本单机环境配置
大的项目你可能连配置都配不清楚。
新手必须要心细,因为你错了一步,想要纠错很困难。
项目要求:
理解图床的逻辑
理解目前的不足
- 单线程
- 多线程模式下count
- 项目bug
连接池的使用
使用连接池,加了一些自动归还连接
redis连接池
日志相关 :双缓冲、异步
Linux输入命令时,ctrl+a光标回到行首;ctrl+e光标跳至末尾
nginx端口要修改端口方法
进入/usr/local/nginx目录下
$ sudo vim ./conf/nginx.conf

nginx常用指令:
/usr/local/nginx/sbin/nginx -s reload # 重新载入配置文件 /usr/local/nginx/sbin/nginx -s reopen # 重启 Nginx /usr/local/nginx/sbin/nginx -s stop # 停止 Nginx- 1
- 2
- 3
- 4
- 5

我们ubuntu 152上的mysql登录:
mysql -uroot -p
123456
DBPool.cpp中的my_bool要改为bool
架构分析
存储用多级目录,这样能够减少遍历时间:
例如:
case1:单级目录存1w个文件,平均查找次数为5000次
case2:二级目录每级存100个文件,平均查找次数为 50 + 50 = 100 次
高可用体现在哪里?
-
tracker是集群
-
同一个group的storage的内容是相同的。
同一个group中建议3个storage -
强一致性,弱一致性
-
-
文件上传时:
-
-
如果是强一致性:可靠,等待时间长
-
- 等待其他storage同步完毕
-
弱一致性:效率高,但是数据不可靠
-
- 当前的storage存储完就返回
-
-
-
storage没有主从
-
一个storage可以有多个磁盘,可以提升写入、读取效率。
-
tc-src后台服务器程序源码是我们要掌握的重点
-
token是存储在缓存中

AUTO_REAL_DBCONN(pDBManager, pDBConn);- 1
创建一个对象,当离开调用该语句的函数时(即退出栈)的时候,可以**自动调用析构释放连接****,**见下图

reactor单线程
就是指只能有一个epoll_wait
配置文件的支持
.ini
.conf 自定义的
.json
yaml
工作流程
- main 读取配置文件
- 初始化reactor
- 初始化线程池
- 初始化日志库
- 初始化连接池
- mysql、redis各自独立
HttpConn连接
可能被释放,关闭连接,释放资源,
放入线程池运行的函数,那就不需要它的资源了。
返回json数据,需要封装到http里面
使用redis优化文件数量计数
使用redis记录
- 我的文件数量
- 共享文件数量
- 分享图片数量
要考虑:
Redis没有记录怎么办呢?
redis清空不影响,文件数量是记录的行数,select count(*)获取文件数量
排行榜:文件数量和mysql的数量不匹配
在初始化的时候从mysql加载到redis
文件引用计数多线程问题分析-事务
目前代码,适合放到线程池处理的api
注册:独立注册,没有共享资源,多线程
登录;独立注册,没有共享资源,多线程
log文件夹的日志功能实现可以看一下代码
线程池处理任务,把执行函数给到线程池后,Httpconn释放资源不能影响执行。(不该用)
回发数据,在reactor线程里面回发
发送完数据连接自动关闭。
redis文件数量的问题,如果key被删除怎么办?
多线程file_count引用计数问题
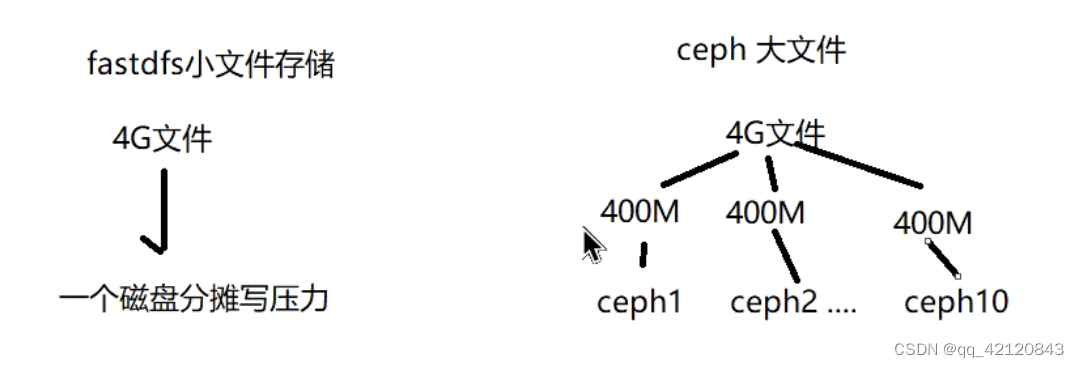
fastdfs
小文件存储

选择存储的group
-
Round robin,所有的group间轮询
-
Specified group,指定某一个确定的group
-
Load balance,选择最大剩余空 间的组上传文件
把文件写到一个storage才会返回一个fileid

ceph适合大文件存储
如果有个4g文件,可配一个ceph集群,每个机器存400M
df(英文全拼:disk free) 命令用于显示目前在 Linux 系统上的文件系统磁盘使用情况统计
- fastdfs没有主从之分,大写为源,小写为副本,只有源可以推送文件给其他服务器。
fastdfs主要掌握内容
原理–能自圆其说
binlog格式设计
发送给不同的storage怎么记录
高可用
- tracker做集群
- storage一般部署3个
高并发
- 写的并发:
- 增加storage不能提高,因为不同storage存的都是相同的数据
- 增加group水平扩展
- 一个storage配置多个硬盘
读的并发:
- 可以通过扩充storage来实现(少写多读的场合)
- 一个storage配置多个硬盘
- 增加group水平扩展
小文件存储
- 小文件查找麻烦(数量过多)
- 对应inode过多
fastdfs是弱一致性
需要特别安全可靠则不合适。
高负载Nginx和文件下载上传原理

upload nginx模块
fastdfs nginx模块
每个storage的服务+fastdfs nginx module
文件上传
http header
http body
分片上传、断点续传
多线程下载
1.
2. 先根据配置的storage路径和fileid查找文件,直接读取发给客户端
3. 通过tracker查看哪些storage可以用 192.168.1.12
a. proxy方式:去12这个机器拉取文件转发给client
b. redirect
返回告诉客户端12这个机器可以拉取文件
客户端去12这个机器拉文件-
proxy,一台机器即可验证token,但是占用带宽 -
redirect,两台机器都要验证,但不会把资源集中在一台机器上 -
body并不都是上传的文件内容,可以有自定义字段以及文件内容
断点下载方式
获取服务器文件大小
发起下载请求文件划分,如10M一个分片
在httpbody自定义字段,user_name + 文件名 + 文件md5,使得唯一
所有分片上传完毕请求合并 (user_name + 文件名 + 文件md5)唯一ID断点续传
加一步,检测对应文件的临时目录是否存在,已经上传了多少分片,唯一ID(user_name + 文件名 + 文件md5)多线程下载

1获取文件大小 951815
2划分内容 951815/5=190363
3每个线程下载对应的区域块
4写入的时候需要加锁,lseek到对应的位置然后写入数据
是否需要临时文件?
答:可以不需要临时文件,分段下载.
是否需要写锁?
性能测试
fastfds只允许上传一份文件
fastdfs本身不支持文件查重
文件是否有上传?
发送md5值—》服务器,把md5存储到redis中做持久化
本机内post测试

如果没注释掉打印语句,即

性能只有500 requests/s

如果注释掉打印语句,性能可以到900 requests/s 。
测试上传
带宽有限制 (外网)
云服务器TPS有时候有限制。
磁盘写入读取有限制可以和面试官说这个项目用来在实验室中分享图片
- KEY uq_md5 ( md5 (8)) – 前缀索引,先匹配md5前8个字符,匹配才继续;并且前面8个字符基本不一样才比较好
RAID
如果磁盘做了RAID,可酌情增大读写线程数,从而发挥磁盘性能图床框架
- 配置文件 xx.conf
- 日志文件
- 端口、线程数量、日志文件名
- mysql、redis
- fastdfs
- 单reactor模型 epoll,随后接入线程池连接池处理
- C++11线程池
- mysql索引优化、事务
- api设计
-
相关阅读:
容易理解的归并排序(C语言)
雷达编程实战之幅度与相位标定
前端工作小结79-重置逻辑
大学生静态HTML鲜花网页设计作品 DIV布局网上鲜花介绍网页模板代码 DW花店网站制作成品 web网页制作与实现
Slurm基本使用
【100个 Unity实用技能】☀️ | Unity 将秒数转化为00:00:00时间格式
一篇文章让你入门【MySQL】
java 版本企业招标投标管理系统源码+多个行业+tbms+及时准确+全程电子化
一天吃透Java集合面试八股文
数据结构实验二 堆栈
- 原文地址:https://blog.csdn.net/qq_42120843/article/details/128027051