-
16.一篇文章学会django模型的使用
1.django模型简单示例
1.1 创建django项目
创建完项目,还需要创建django子项目
django-admin startproject model_study cd .\model_study\ python manage.py startapp model_app- 1
- 2
- 3

1.2配置应用
将模型对应的应用程序(刚刚创建的子应用)添加到项目的settings中:
INSTALLED_APPS = [ 'model_app',# 一定要加逗号!!!!! ]- 1
- 2
- 3
在settings中配置正确的数据库连接
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'django_model_study', 'USER': 'root', 'PASSWORD':'root', 'HOST':'127.0.0.1', 'PORT':'3306', } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
安装对应数据库的驱动
pip install mysqlclient==2.0.3- 1
1.3 预备迁移
在项目根目录的cmd中运行
python manage.py makemigrations model_app- 1
- model_app是子应用的名称,如果不指定,那么就是对所有
- INSTALLED_APPS 中的应用都进行预备迁移
指定该命令后,在对应的子应用下的 migrations 中会生成一个对应的迁移文件
1.4编写模型
在子应用的models.py中
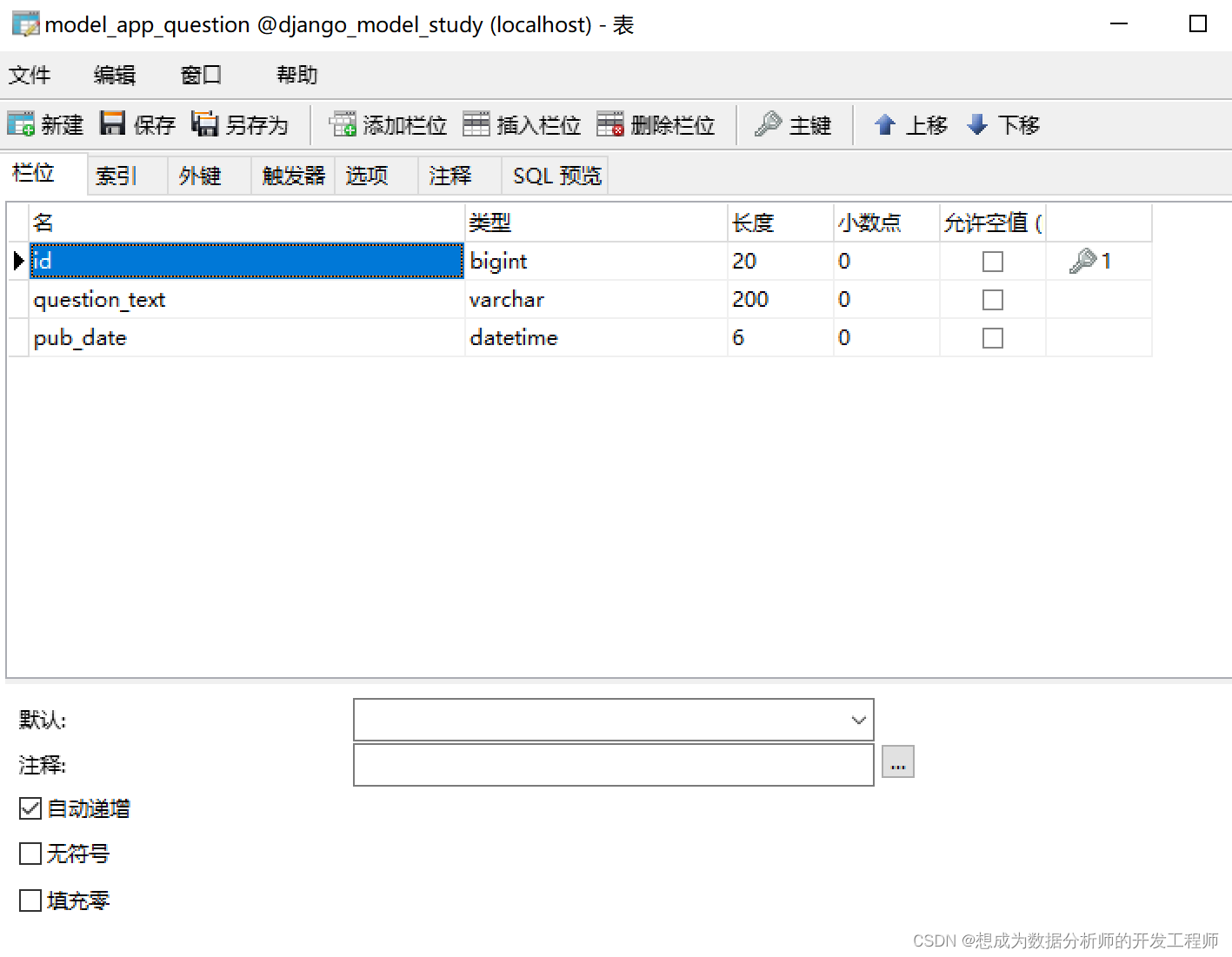
from django.db import models # Create your models here. class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField()- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.5 正式迁移
python manage.py migrate model_app- 1
1.6 效果展示
2.django模型修改后重新应用
2.1概述
不管是新增模型,还是修改已有模型后,在编写完模型后,只需要重复1.3预备迁移和正式迁移步骤,会在migrations中自动生成新的迁移文件。即自动实现数据库中的表结构、表关系等信息的修改
2.2 在1.4基础上继续修改已有模型代码
from django.db import models # Create your models here. class Question(models.Model): question_title = models.CharField(max_length=20) question_text = models.CharField(max_length=200) pub_date = models.DateTimeField()- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.3预备迁移与正式迁移
在项目根目录的cmd中运行
python manage.py makemigrations model_app- 1
此时出现报错
You are trying to add a non-nullable field ‘question_title’ to question without a default; we can’t do that (the database
needs something to populate existing rows).
Please select a fix:- Provide a one-off default now (will be set on all existing rows with a null value for this column)
- Quit, and let me add a default in models.py
Select an option:
大概意思就是,本身已有的字段,需要为新的字段设置一个默认值,此时我们给新字段多加一个空值。
修改模型代码如下
from django.db import models # Create your models here. class Question(models.Model): question_title = models.CharField(max_length=20, default='') question_text = models.CharField(max_length=200) pub_date = models.DateTimeField()- 1
- 2
- 3
- 4
- 5
- 6
- 7
再次执行预备迁移命令
执行正式迁移命令python manage.py migrate model_app- 1
2.4效果展示

3.Django逆向从数据库表生成模型类
3.1创建新的Django应用
创建新的Django项目(reverse_model_study)与子应用(model_app)方法参考1.1,配置方法参考1.2
3.2 在navicat中新建表
创建新的数据库,然后新建表

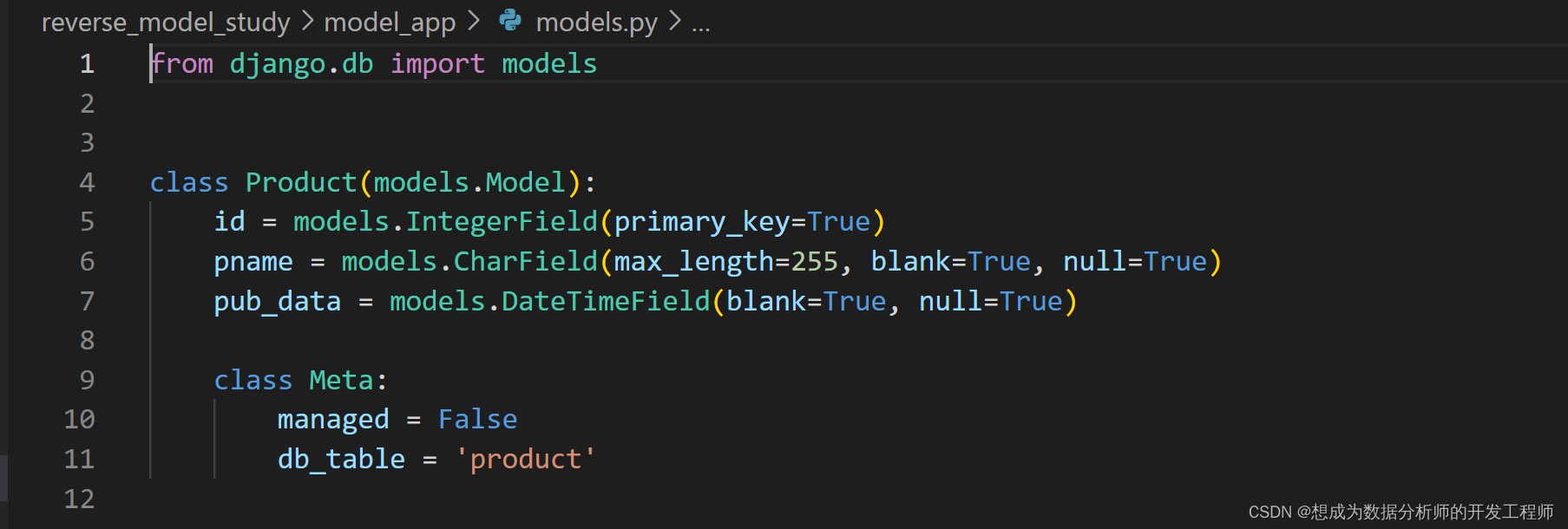
3.2生成模型类
在根目录的cmd中运行:
python manage.py inspectdb > model_app/models.py- 1
偶遇报错django.db.utils.OperationalError: unable to open database file
解决方法:发现是在1.2中的配置mysql出现错误,splite没改成mysql3.3自动生成表结构
4.Django项目使用sqlite3数据库
4.1 准备项目
按照1.1方法创建django项目,并配置应用(不配置数据库的)
4.2 创建模型类
在子应用的models中
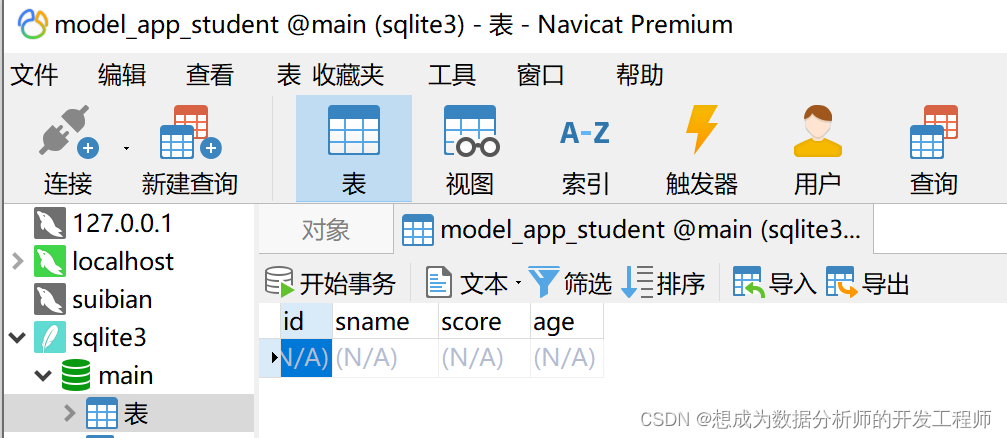
from django.db import models # Create your models here. # 创建模型类 class Student(models.Model): sname = models.CharField(max_length=20) score = models.CharField(max_length=20) age = models.CharField(max_length=20)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.3 预备迁移与正式迁移
参考1.3与1.5即可
偶遇报错:model_app.Student.score: (fields.E120) CharFields must define a ‘max_length’ attribute.
原因是我的模型中对CharFild的score并没有给最大长度限制(上面的已修改)4.4 效果展示
5.字段Field
5.1 字段命名限制
-
字母,数字,下划线,首字母不能是数字
-
字段名称不能是Python保留字
-
由于Django查询查找语法的工作方式,字段名称不能在一行中包含多个下划线,譬如“abc__123”就是不允许的,一个下划线是可以的’abc_123’
5.2 AutoField、ID、主键PRIMARY_KEY
默认会自动创建一个自增,主键的id列
如果指定了 primary_key 为其它列,那么不会自动创建id列
可以在模型中指定(自动生成主键):
id = models.AutoField(primary_key=True)- 1
5.3常见的Filed
所有的Field类型,见 官方网址

特殊使用:uuid不加括号import uuid from django.db import models class MyUUIDModel(models.Model): # uuid.uuid4 千万别写成 uuid.uuid4() ,不要写 () id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)- 1
- 2
- 3
- 4
- 5
- 6
5.4 Field常见参数
- max_length:字段最大长度,用于字符串等,字符串类型CharField必须设置该值
- null:如果True,Django将在数据库中存储NULL空值。默认是False
- blank:如果True,该字段被允许为空白(“”)。默认是False。请注意,这不同于null。null纯粹是与数据库相关的,而blank与验证相关。如果一个字段有blank=True,表单验证将允许输入一个空值。如果一个字段有blank=False,该字段将是必需的。
- choices:示例:YEAR_IN_SCHOOL_CHOICES = ((‘FR’, ‘Freshman’),(‘SO’, ‘Sophomore’),(‘JR’, ‘Junior’),(‘SR’, ‘Senior’),(‘GR’, ‘Graduate’)) ,中文示例:SEX_CHOICES=((1, ‘男’),(2, ‘女’)),元组中的第一个元素是将存储在数据库中的值,第二个元素是将在页面中显示的值,最常见用于下拉选择框select
- default:字段的默认值
- help_text:用于显示额外的“帮助”文本
- primary_key:如果True,这个字段是模型的主键,默认是False
- unique:如果True,该字段在整个表格中必须是唯一的
- verbose_name:详细字段名,不指定则是属性名的小写,并且用 空格 替换 ‘_’
6.模型之间的关系
6.1 模型一对多关系映射
概述
-
主外关系中,关联操作最常用的是: models.CASCADE 级联删除(主表子表一起删) 和 models.SET_NULL 设置为null
-
一对多关系中,ForeignKey 写在一对多关系中,多的那个模型中
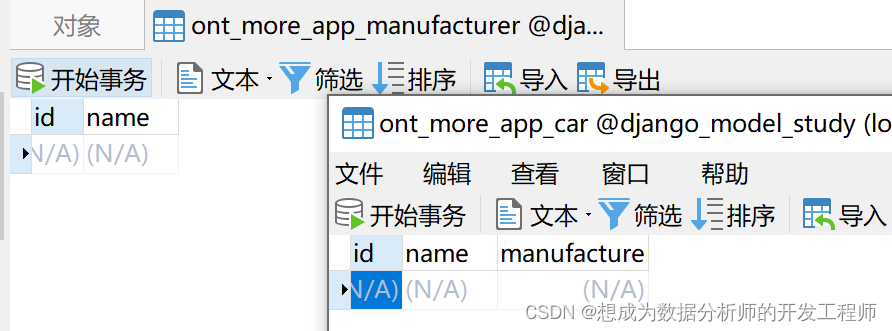
例如:使用django.db.models.ForeignKey,例如,如果一个Car模型有一个Manufacturer,也就是说,一个Manufacturer可以对应多个汽车,但Car只有一个汽车生产商Manufacturer。Car的数量是多种,所以他是外键。
from django.db import models # Create your models here. # 主表 class Manufacturer(models.Model): name = models.CharField(max_length=20) # 子表 class Car(models.Model): # 外键名是对应类名的小写 # on_delete 是必须属性(级联删除) manufacturer = models.ForeignKey(Manufacturer, on_delete=models.CASCADE) name = models.CharField(max_length=20)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
效果展示
6.2 模型一对一关系映射
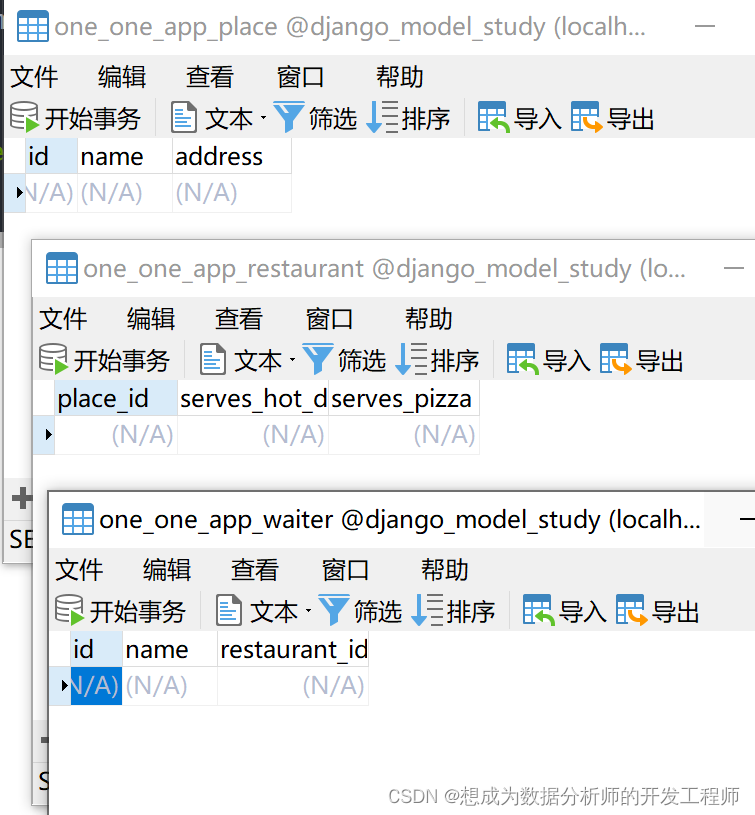
使用django.dbOneToOneField,例如,地址Place和餐馆Restaurant是一对一关系,而餐馆Restaurant和服务员Waiter是一对多关系
6.3 模型多对多关系映射
自关联
对于多对多表,例如学生表,一个学生可能会有多位好友。然而好友和学生都是同属于学生表的,这个就是最简易的多对多表——其实他们都是通过生成一张中间表(会自动生成),拆分成一对多的关系进行存储from django.db import models # Create your models here. class Student(models.Model): name = models.CharField(max_length=20) friends = models.ManyToManyField("self")- 1
- 2
- 3
- 4
- 5
- 6
- 7
简易多对多
对于教室和老师关系,每个老师需要在多个教室上课,每个教室会有多个老师来上课。from django.db import models class SchoolClass(models.Model): name = models.CharField(max_length=20) class Teacher(models.Model): name = models.CharField(max_length=20) school_class = models.ManyToManyField(SchoolClass)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

自定义中间表
不使用Django中自动生成的中间表:
人与组之间的关系也是一种多对多关系from django.db import models class Person(models.Model): first_name = models.CharField(max_length=50) last_name = models.CharField(max_length=50) class Group(models.Model): name = models.CharField(max_length=128) # through: 中间表的名称, through_fields:中间表的字段(为两张主表的小写名称为外键) members = models.ManyToManyField(Person,through='Membership', through_fields=('group', 'person') ) class Membership(models.Model): group = models.ForeignKey(Group, on_delete=models.CASCADE) person = models.ForeignKey(Person, on_delete=models.CASCADE) level = models.IntegerField(default=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
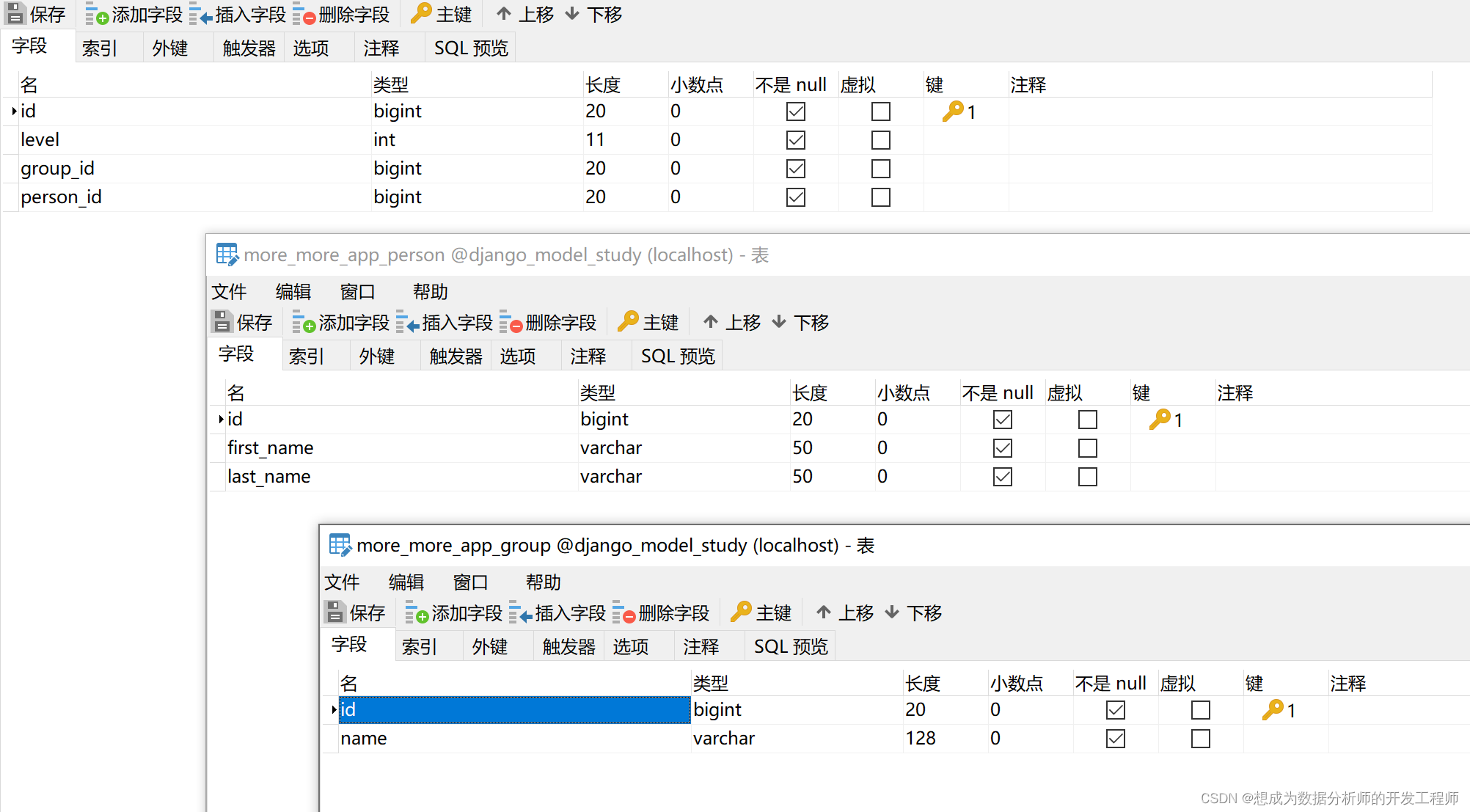
- 通过 through=‘Membership’ 指定Membership作为中间表
- 通过 through_fields=(‘group’, ‘person’) 指定中间模型的属性
- 一般需要自定义中间表时,都是有额外的字段,譬如 level = models.IntegerField(default=1)
7.Django模型之方法
除了运行程序时,可以测试模型,还可以在根目录的cmd执行:
先进入父级目录,执行以下代码python manage.py shell- 1
打开django脚本控制台,测试执行模型的方法,会比启动项目更方便
模型对象中有一个objects属性,该属性是管理器Manager类型的对象,几乎所有的方法都是通过该对象执行的,具体见下面的代码:
7.1 新增数据
具体的字段可以从第6点中查看,在VSCode的终端运行
普通模型插入
save或createfrom model_app.models import *# model_app是子级目录,models是他模型存储的文件名 # 方法1:create Question.objects.create(question_title='insert1',question_text='insert_content',pub_date='2020-1-1') # 方法2:save p1=Question(question_title='insert1',question_text='insert_content',pub_date='2020-1-1') p1.save()- 1
- 2
- 3
- 4
- 5
- 6
一对一关系插入
首先,先增加未使用OneToOneField这一方,查询出来后作为一个对象,作为字段插入另一个使用OneToOneField这一方from one_one_app.models import * # 插入一方数据 Place.objects.create(name='北京',address='北京饭店') # 方法1: #先获取到一中一方数据为一个对象:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
一对多关系插入
方法1:还是按照一对一方式
方法2:先添加其中一方,然后再创建多方对象,设置外键(可以选择直接给主表的对象,也可以赋值关联的外键),保存对象
这里就演示方法2# 方法1: r = Restaurant.objects.get(pk=1) #先查询 Waiter.objects.create(restaurant=r,name="小张") # 插入 # 方法2:赋值外键为对象 r = Restaurant.objects.get(pk=1) #先查询 W = Waiter(name="小李") W.restaurant = r W.save() # 方法2:赋值外键为主键id w = Waiter(name="小王") w.restaurant_id = 1 w.save()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
多对多关系插入
先对两张主表进行插入数据,用普通模型插入方式,再获取其中一方的对象,使用set方法为中间表赋值。
给中间表赋值有两种方法,一种是set,一种是add。set在二次插入时,会重新赋值,add是增加,遇到重复则保留。# 先对主表分别插入 Teacher.objects.create(name="李老师") Teacher.objects.create(name="王老师") Teacher.objects.create(name="张老师") SchoolClass.objects.create(name="班级1") SchoolClass.objects.create(name="班级2") SchoolClass.objects.create(name="班级3") # 使用set添加中间表 t = Teacher.objects.get(pk=1) t.school_class.set([1,2,3]) t.school_class.set([1,2]) # 执行完发现,上一条语句内容被覆盖 # 使用add添加中间表 t = Teacher.objects.get(pk=2) t.school_class.add(1,2,3) t.school_class.add(1,2) # 执行完发现,上一条语句内容不会被覆盖- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
7.2 查询数据
7.2.1 常规查询与过滤器
- 大部分检索是懒惰执行的,只在真实获取值的时候,才会去连接数据库获取数据
- 查询集通过过滤器进行查询,允许链式调用
- pk是主键的别名(primary key),如果真实主键是id,那么 pk 和 id 使用是一样的效果
# get 获取一个对象 # 查询主键等于 1 的 , 如果主键是ID,也可以使用 id=1 # 如果条件找不到对应的记录,会抛出 DoesNotExist 错误 # 如果条件找到多个记录,会抛出 MultipleObjectsReturned 错误 >>> from model_app.models import Question >>> Question.objects.get(id=1)[ [ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
7.2.2 字段查找
字段查找
-
字段检索,是在字段名后加 ‘__’ 双下划线,再加关键字,类似 SQL 语句中的 where 后面的部分, 如: 字段名__关键字
-
在查找中指定的字段必须是模型字段的名称,但有一个例外,如果是ForeignKey字段,则是属性名+ ‘_id’: Entry.objects.filter(blog_id=4) , 定义的 ForeignKey是 blog
-
完整的字段检索文档:
https://docs.djangoproject.com/en/2.2/ref/models/querysets/#field-lookups
常见的字段检索:
exact :判断是否等于value,一般不使用,而直接使用 ‘=’
contains:是否包含,大小写敏感,如果需要不敏感的话,使用icontains
startswith:以value开头,大小写敏感
endwith:以value结尾,大小写敏感
in:是否包含在范围内
isnull:是否为null, 如:filter(name__isnull=Flase)
gt:大于,如:filter(sage__gt=30) , 年龄大于30
gte:大于等于
lt:小于
lte:小于等于
>>> Question.objects.filter(id__exact=1)[ [ [ []> >>> Question.objects.filter(question_text__icontains='I') [ []> >>> Question.objects.filter(question_text__istartswith='I') [ [ [ []> >>> Question.objects.filter(question_text__isnull=False) [ [ [ [ [ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
7.2.3 日期时间的过滤
year/month/day/week_day/hour/minute/second:时间查询,如: filter(pub_date__year=2015) 年份是2015的, filter(pub_date__day=15) 天数是15的
#时间可以直接使用gt gte lt lte Account.objects.filter(register_date__gt='2021-7-1') #__range查询某个时间段 Account.objects.filter(register_date__range=('2021-7-1','2021-7-7')) #查询某年某月某日 __date Account.objects.filter(register_date__date='2021-7-6')[ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
7.2.4 order_by排序
# 正序排列 >>> Question.objects.order_by('pub_date')[ [ [ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7.2.5 查询的其他方法
# count() 对结果集统计 count = Person.objects.filter(pub_date__year=2006).count() #reverse() 对结果集进行反转 注意使用reverse必须先排序 #比如要取数据的最后10条,可以先反转再切片 Account.objects.all().order_by('id').reverse()[:1] # first() 返回结果集的第一个对象 person = Person.objects.filter(pub_date__year=2006).first() person = Person.objects.first() # last() 返回结果集的最后一个对象 person = Person.objects.filter(pub_date__year=2006).last() # values() 返回一个 字典对象 列表 person_dict_li = Person.objects.filter(pub_date__year=2006).values() #values()传入字段 Account.objects.all().values('user_name')[{'user_name': 'lili'}, {'user_name': 'tom'}, {'user_name': '李四'}]> Account.objects.all().values('user_name','register_date') [{'user_name': '李四', 'register_date': datetime.datetime(2021, 7, 1, 3, 18, 18, tzinfo= )}, {'user_name': 'tom', 'register_date': datetime.datetime(2021, 7, 6, 1, 52, 54, 5896, tzinfo= )}, {'user_name': 'lili', 'register_date': datetime.datetime(2021, 7, 6, 2, 10, 42, 927481, tzinfo= )}]> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
只有真正取值时候,才会连接数据库获取数据——懒惰查询
7.2.6 多对象关联查询
当我们需要在一对一关系、一对多关系、多对多关系中获取数据时,这就需要使用我们的多对象关联查询
- 一对一关系,通过一个模型获取另一个模型
得先判定当前表是否有关联关系,是两种方法:
# 通过关联的方式,过滤数据 >>> Restaurant.objects.filter(place__address__startswith='北京')[ [ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 一对多关系,通过一个模型获取另一个模型
得先判定当前表是否有关联关系,是两种方法:
# 先获取id=1的餐厅信息,再查询到其中的关联的waiter表中的所有信息 >>> r = Restaurant.objects.get(pk=1) >>> r.waiter_set.all()[ - 1
- 2
- 3
- 4
- 5
- 多对多关系,通过一个模型获取另一个模型
得先判定当前表是否有关联关系,是两种方法:
# 当前表存在关联关系(ManyToManyField):直接调用关联关系字段 >>> t = Teacher.objects.first() >>> t[ [ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
7.2.7 聚合函数
使用aggregate()函数返回聚合函数的值
常用的聚合函数有:Avg、Count、Max、Min、Sum
>>> from model_app.models import * >>> from django.db.models import * # 常规查询 >>> Question.objects.aggregate(Max('id')) {'id__max': 6} # 设置结果名称 >>> Question.objects.aggregate(idMax=Max('id')) {'idMax': 6} # 连续使用聚合函数 >>> Question.objects.aggregate(idMax=Max('id'), idMin=Min('id'), idAvg=Avg('id')) {'idMax': 6, 'idMin': 1, 'idAvg': 3.5}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
7.2.8 分组查询
使用annotate()函数实现分组查询,得配合其他函数:
- annotate:用于分组,配合 Avg,Count等聚合函数,如:annotate(max=Max(‘age’))
- filter: 用于过滤,在 annotate之前使用表示 where 条件,在annotate之后使用表示having条件
- values:在annotate之前使用表示分组字段,在annotate之后使用表示取值
# 对于每个老师都有不同的班级,每个班级都有不同的老师,是多对多关系 # 查询每个班级有多少位老师(存在关联关系,就可以利用中间表取查询统计) Teacher.objects.values('school_class').annotate(tcount=Count('id'))[{'school_class': 1, 'tcount': 2}, {'school_class': 2, 'tcount': 2}, {'school_class': 3, 'tcount': 1}, {'school_class': None, 'tcount': 1}]> # 查询每个老师教了多少班级(不存在关联关系字段,先通过班级关联另一张表,再过滤) >>> SchoolClass.objects.values('teacher').annotate(tcount=Count('id')) [{'teacher': 1, 'tcount': 2}, {'teacher': 2, 'tcount': 3}]> # 过滤 ,结果一样,但是第二种的效率更高(where效率高于having) >>> SchoolClass.objects.values('teacher').annotate(tcount=Count('id')).filter(name__contains='班级2') [{'teacher': 1, 'tcount': 1}, {'teacher': 2, 'tcount': 1}]> >>> SchoolClass.objects.values('teacher').filter(name__contains='班级2').annotate(tcount=Count('id')) [{'teacher': 1, 'tcount': 1}, {'teacher': 2, 'tcount': 1}]> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
7.3 修改数据
单条语句修改,获取对象后,直接对对象的属性名进行修改,再save
多条语句修改,先获取多条语句对象,再使用update就行>>> q = Question.objects.first() >>> q.question_title = 'update title' >>> q.save() >>> Question.objects.filter(pub_date__day='1').update(question_title='update titles') 2- 1
- 2
- 3
- 4
- 5
7.4 删除数据
删除数据直接获取对象,然后执行delete方法即可
>>> Question.objects.filter(pub_date__day='1').delete() (2, {'model_app.Question': 2})- 1
- 2
7.5 刷新对象
当我们从数据库先获取了一个对象,但是如果这之后进行了修改,需要刷新对象,重新获取。就避免了再一次的编写获取对象的代码
>>> q = Question.objects.first() >>> q.question_text 'insert2_content' # 此时在navicat中修改数据,发现还是没变化 >>> q.question_text 'insert2_content' >>> q.refresh_from_db() >>> q.question_text 'insert2_content7777'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7.6 模型Q对象的使用
Q对象就是完成过滤时的且、或、非等操作
filter() 等方法中的关键字参数查询都是并且(‘AND’)的, 如果你需要执行更复杂的查询(例如or语句),那么可以使用Q 对象。 Q 对象 (django.db.models.Q) 对象用于封装一组关键字参数,可以使用 & 和 | 操作符组合起来,当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
>>> from django.db.models import Q >>> Question.objects.filter(Q(pub_date__year='2021') | Q(question_text__startswith='O'))[ [ [ [ [ " , line 1 Question.objects.filter(pub_date__year='2021',Q(pub_date__year='2021')) ^ SyntaxError: positional argument follows keyword argument- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
7.7 模型F对象的使用
模型的属性名出现在操作符的右边,就使用F对象进行包裹
# 找出女生数量大于男生数量的年级 # 对应sql:select * from grade where girlnum > boynum grades = Grade.objects.filter(girlnum__gt=F('boynum'))- 1
- 2
- 3
# 找出女生数量大于 男生数量+10 的年级 # 对应的sql: select * from grade where girlnum > boynum + 10 Grade.objects.filter(girlnum__gt=F('boynum') + 10) # 所有书籍的价格 +1 # 对应的 sql: update book set price = price + 1 Book.objects.update(price=F("price")+1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
8.sql语句的使用
8.1通过模型使用sql
通过raw函数执行原始的sql语句进行查询
# 定义个 person 模型 class Person(models.Model): first_name = models.CharField() last_name = models.CharField() birth_date = models.DateField() # 执行 原始 SQL # 表名前面必须加 应用名myapp,即在数据库中的真实表名,否则会抛出异常 for p in Person.objects.raw('SELECT * FROM myapp_person'): print(p) # 字段先后顺序没关系 Person.objects.raw('SELECT id, first_name, last_name, birth_date FROM myapp_person') # 等同于 Person.objects.raw('SELECT last_name, birth_date, first_name, id FROM myapp_person') # 可以从其他表格中查询出匹配 person 模型的记录集 # 总之最终的数据集的结构必须和 Person一样 Person.objects.raw('SELECT first AS first_name, last AS last_name,bd AS birth_date,pk AS id,FROM some_other_table') # 返回的结果集一样可以执行切片 first_person = Person.objects.raw('SELECT * FROM myapp_person')[0] # 但是上述语句会返回所有结果,基于节省传输的需要,在数据库缩小结果集范围更正确 first_person = Person.objects.raw('SELECT * FROM myapp_person LIMIT 1')[0] # 传递参数 lname = 'Doe' Person.objects.raw('SELECT * FROM myapp_person WHERE last_name = %s', [lname])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
不应用模型,直接执行sql
from django.db import connection def my_custom_sql(obj): with connection.cursor() as cursor: cursor.execute("UPDATE bar SET foo = 1 WHERE baz = %s", [obj.baz]) cursor.execute("SELECT foo FROM bar WHERE baz = %s", [obj.baz]) row = cursor.fetchone() return row- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
相关阅读:
Java-lambda表达式
知识点滴 - 有关剧本的网站
领域知识图谱的医生推荐系统:利用BERT+CRF+BiLSTM的医疗实体识别,建立医学知识图谱,建立知识问答系统
Python安装教程(Windows10系统)
SkyWalking快速上手(二)——架构剖析1
Redis客户端RedisTemplate入门学习
思腾合力GPU服务器
产品设计与用户体验 优漫动游
处暑(Limit of Heat )节到了,应了解的生活常识
【C++学习第八讲】简单变量(二)
- 原文地址:https://blog.csdn.net/m0_63953077/article/details/127908912