-
CNN学习笔记
目录
提高模型鲁棒性(抗干扰能力),非线性表达能力,缓解梯度消失问题、加 速模型收敛
如何理解卷积层和池化层?
卷积层 池化层 卷积层用来提取特征 池化层可以减少参数数量。 使用卷积核来提取特征的,卷积核可以说是一个矩阵。假如我们设置一个卷积核为3*3的矩阵,而我们图片为一个分辨率5*5的图片。那么卷积核的任务就如下所示:
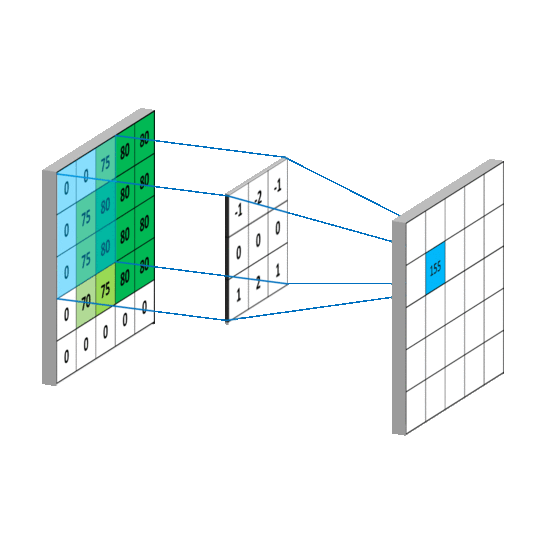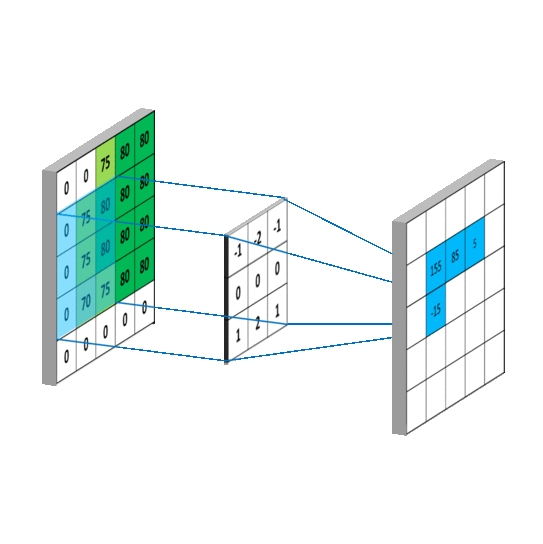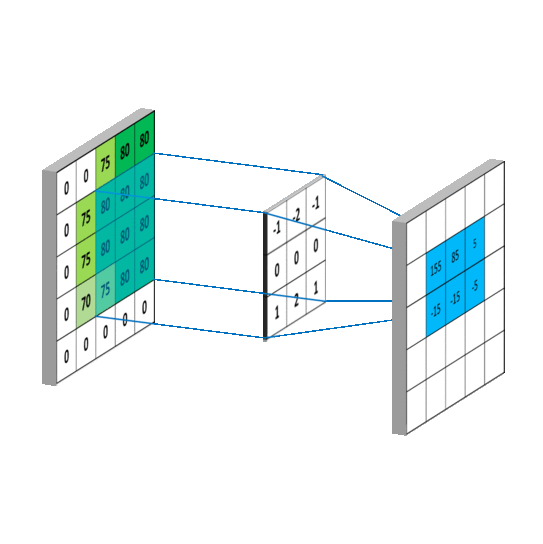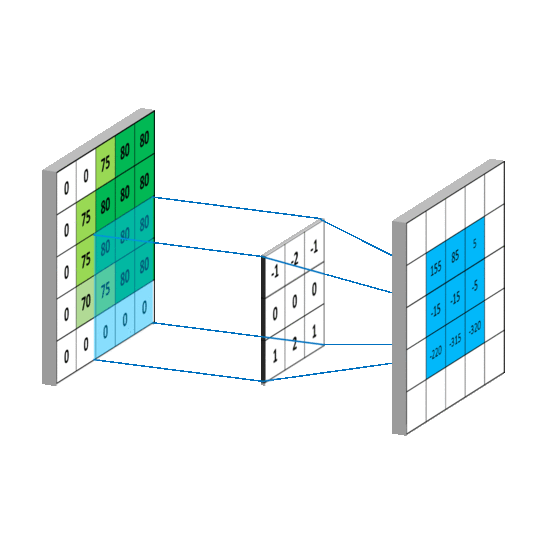
一般我们有最大池化和平均池化,而最大池化就我认识来说是相对多的。需要注意的是,池化层一般放在卷积层后面。所以池化层池化的是卷积层的输出!


卷积层还有另外两个很重要的参数:步长和padding。
所谓的步长就是控制卷积核移动的距离。在上面的例子看到,卷积核都是隔着一个像素进行映射的,那么我们也可以让它隔着两个、三个,而这个距离被我们称作步长。
而padding就是我们对数据做的操作。一般有两种,一种是不进行操作,一种是补0使得卷积后的激活映射尺寸不变。上面我们可以看到5*5*3的数据被3*3的卷积核卷积后的映射图,形状为3*3,即形状与一开始的数据不同。有时候为了规避这个变化,我们使用“补0”的方法——即在数据的外层补上0。


池化层也有padding的选项。但都是跟卷积层一样的,在外围补0,然后再池化。 卷积层和池化层部分总结(类型,区别,卷积核是否越大越好,减少卷积层参数量方法总结归纳,提高卷积神经网络的泛化能力)
机器视角:长文揭秘图像处理和卷积神经网络架构
卷积神经网络 - 基础知识
激活函数的作用是什么?
激活函数(加入非线性因素)
激活函数是为了解决对隐藏变量使用按元素运算的非线性函数进行变换,然后再作为下一个全连接层的输入。单层感知机只能表示线性空间,不能线性划分。激活函数是连接感知机和神经网络的桥梁。

提高模型鲁棒性(抗干扰能力),非线性表达能力,缓解梯度消失问题、加 速模型收敛
将当前特征空间映射转换到另一个空间,让数据能够更好的被分类
非线性激活函数
假若网络中全部是线性部件,那么线性的组合还是线性,与单独一个线 性分类器无异。
网络更加强大,学习复杂的事物,复杂的表单数据,从输入输出之间生 成非线性映射。
使用AI Studio使用CNN实现猫狗分类:
实践总体过程和步骤如下图

- #导入需要的包
- import paddle as paddle
- import paddle.fluid as fluid
- import numpy as np
- from PIL import Image
- import matplotlib.pyplot as plt
- import os
- BATCH_SIZE = 128
- #用于训练的数据提供器
- train_reader = paddle.batch(
- paddle.reader.shuffle(paddle.dataset.cifar.train10(),
- buf_size=128*100),
- batch_size=BATCH_SIZE)
- #用于测试的数据提供器
- test_reader = paddle.batch(
- paddle.dataset.cifar.test10(),
- batch_size=BATCH_SIZE)
- def convolutional_neural_network(img):
- # 第一个卷积-池化层
- conv_pool_1 = fluid.nets.simple_img_conv_pool(
- input=img, # 输入图像
- filter_size=5, # 滤波器的大小
- num_filters=20, # filter 的数量。它与输出的通道相同
- pool_size=2, # 池化核大小2*2
- pool_stride=2, # 池化步长
- act="relu") # 激活类型
- conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
- # 第二个卷积-池化层
- conv_pool_2 = fluid.nets.simple_img_conv_pool(
- input=conv_pool_1,
- filter_size=5,
- num_filters=50,
- pool_size=2,
- pool_stride=2,
- act="relu")
- conv_pool_2 = fluid.layers.batch_norm(conv_pool_2)
- # 第三个卷积-池化层
- conv_pool_3 = fluid.nets.simple_img_conv_pool(
- input=conv_pool_2,
- filter_size=5,
- num_filters=50,
- pool_size=2,
- pool_stride=2,
- act="relu")
- # 以softmax为激活函数的全连接输出层,10类数据输出10个数字
- prediction = fluid.layers.fc(input=conv_pool_3, size=10, act='softmax')
- return prediction
- #定义输入数据
- data_shape = [3, 32, 32]
- images = fluid.layers.data(name='images', shape=data_shape, dtype='float32')
- label = fluid.layers.data(name='label', shape=[1], dtype='int64')
- # 获取分类器,用cnn进行分类
- predict = convolutional_neural_network(images)
- # 获取损失函数和准确率
- cost = fluid.layers.cross_entropy(input=predict, label=label) # 交叉熵
- avg_cost = fluid.layers.mean(cost) # 计算cost中所有元素的平均值
- acc = fluid.layers.accuracy(input=predict, label=label) #使用输入和标签计算准确率
- # 定义优化方法
- optimizer =fluid.optimizer.Adam(learning_rate=0.001)
- optimizer.minimize(avg_cost)
- print("完成")
- # 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
- use_cuda = True
- place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
- # 创建执行器,初始化参数
- exe = fluid.Executor(place)
- exe.run(fluid.default_startup_program())
- all_train_iter=0
- all_train_iters=[]
- all_train_costs=[]
- all_train_accs=[]
- def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
- plt.title(title, fontsize=24)
- plt.xlabel("iter", fontsize=20)
- plt.ylabel("cost/acc", fontsize=20)
- plt.plot(iters, costs,color='red',label=label_cost)
- plt.plot(iters, accs,color='green',label=lable_acc)
- plt.legend()
- plt.grid()
- plt.show()
- EPOCH_NUM = 20
- model_save_dir = "/home/aistudio/work/catDogModel"
- # 获取测试程序
- test_program = fluid.default_main_program().clone(for_test=True)
- for pass_id in range(EPOCH_NUM):
- # 开始训练
- for batch_id, data in enumerate(train_reader()): #遍历train_reader的迭代器,并为数据加上索引batch_id
- train_cost,train_acc = exe.run(program=fluid.default_main_program(),#运行主程序
- feed=feeder.feed(data), #喂入一个batch的数据
- fetch_list=[avg_cost, acc]) #fetch均方误差和准确率
- all_train_iter=all_train_iter+BATCH_SIZE
- all_train_iters.append(all_train_iter)
- all_train_costs.append(train_cost[0])
- all_train_accs.append(train_acc[0])
- #每100次batch打印一次训练、进行一次测试
- if batch_id % 100 == 0:
- print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
- (pass_id, batch_id, train_cost[0], train_acc[0]))
- # 开始测试
- test_costs = [] #测试的损失值
- test_accs = [] #测试的准确率
- for batch_id, data in enumerate(test_reader()):
- test_cost, test_acc = exe.run(program=test_program, #执行测试程序
- feed=feeder.feed(data), #喂入数据
- fetch_list=[avg_cost, acc]) #fetch 误差、准确率
- test_costs.append(test_cost[0]) #记录每个batch的误差
- test_accs.append(test_acc[0]) #记录每个batch的准确率
- # 求测试结果的平均值
- test_cost = (sum(test_costs) / len(test_costs)) #计算误差平均值(误差和/误差的个数)
- test_acc = (sum(test_accs) / len(test_accs)) #计算准确率平均值( 准确率的和/准确率的个数)
- print('Test:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, test_cost, test_acc))
- #保存模型
- # 如果保存路径不存在就创建
- if not os.path.exists(model_save_dir):
- os.makedirs(model_save_dir)
- print ('save models to %s' % (model_save_dir))
- fluid.io.save_inference_model(model_save_dir,
- ['images'],
- [predict],
- exe)
- print('训练模型保存完成!')
- draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
- def load_image(file):
- #打开图片
- im = Image.open(file)
- #将图片调整为跟训练数据一样的大小 32*32, 设定ANTIALIAS,即抗锯齿.resize是缩放
- im = im.resize((32, 32), Image.ANTIALIAS)
- #建立图片矩阵 类型为float32
- im = np.array(im).astype(np.float32)
- #矩阵转置
- im = im.transpose((2, 0, 1))
- #将像素值从【0-255】转换为【0-1】
- im = im / 255.0
- #print(im)
- im = np.expand_dims(im, axis=0)
- # 保持和之前输入image维度一致
- print('im_shape的维度:',im.shape)
- return im
- with fluid.scope_guard(inference_scope):
- #从指定目录中加载 推理model(inference model)
- [inference_program, # 预测用的program
- feed_target_names, # 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
- fetch_targets] = fluid.io.load_inference_model(model_save_dir,#fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。
- infer_exe) #infer_exe: 运行 inference model的 executor
- infer_path=['dog1.jpg','dog2.jpg','dog3.jpg','Cat1.jpg','Cat2.jpg','Cat3.jpg']
- label_list = [
- "airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse",
- "ship", "truck"
- ]
- predict_result = []
- for image in infer_path:
- img = Image.open(image)
- plt.imshow(img)
- plt.show()
- img = load_image(image)
- results = infer_exe.run(inference_program, #运行预测程序
- feed={feed_target_names[0]: img}, #喂入要预测的img
- fetch_list=fetch_targets) #得到推测结果
- predict_result.append(label_list[np.argmax(results[0])])
- print("infer results: \n", predict_result)
-
相关阅读:
Scala入门
讲解Windows系统中如何使用Python读取图片的元数据【Metadata】
网页js版音频数字信号处理:H5录音+特定频率信号的特征分析和识别提取
开源日报 0825 | 简化开发过程,提升Swift应用性能的扩展工具库
window 11 wsl 安装docker
slate源码解析(三)- 定位
洛谷千题详解 | P1016 [NOIP1999 提高组] 旅行家的预算【C++、Java、Python语言】
刷题记录:牛客NC19975[HAOI2008]移动玩具
Oracle 学习之 DML 语句
UGUI交互组件InputField
- 原文地址:https://blog.csdn.net/qq_63202674/article/details/127871756
