-
CVT代码及修改
CVT代码
看一下整体框架的编写,删除掉了初始化等操作,精简代码。from functools import partial from itertools import repeat from torch._six import container_abcs import logging import os from collections import OrderedDict import numpy as np import scipy import torch import torch.nn as nn import torch.nn.functional as F from einops import rearrange from einops.layers.torch import Rearrange from timm.models.layers import DropPath, trunc_normal_ from .registry import register_model class LayerNorm(nn.LayerNorm): """Subclass torch's LayerNorm to handle fp16.""" def forward(self, x: torch.Tensor): orig_type = x.dtype ret = super().forward(x.type(torch.float32)) return ret.type(orig_type) class QuickGELU(nn.Module): def forward(self, x: torch.Tensor): return x * torch.sigmoid(1.702 * x) class Mlp(nn.Module): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x class Attention(nn.Module): def __init__(self, dim_in, dim_out, num_heads, qkv_bias=False, attn_drop=0., proj_drop=0., method='dw_bn', kernel_size=3, stride_kv=1, stride_q=1, padding_kv=1, padding_q=1, with_cls_token=True, **kwargs ): super().__init__() self.stride_kv = stride_kv self.stride_q = stride_q self.dim = dim_out self.num_heads = num_heads # head_dim = self.qkv_dim // num_heads self.scale = dim_out ** -0.5 self.with_cls_token = with_cls_token self.conv_proj_q = self._build_projection( dim_in, dim_out, kernel_size, padding_q, stride_q, 'linear' if method == 'avg' else method ) self.conv_proj_k = self._build_projection( dim_in, dim_out, kernel_size, padding_kv, stride_kv, method ) self.conv_proj_v = self._build_projection( dim_in, dim_out, kernel_size, padding_kv, stride_kv, method ) self.proj_q = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.proj_k = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.proj_v = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim_out, dim_out) self.proj_drop = nn.Dropout(proj_drop) def _build_projection(self, dim_in, dim_out, kernel_size, padding, stride, method): if method == 'dw_bn': proj = nn.Sequential(OrderedDict([ ('conv', nn.Conv2d( dim_in, dim_in, kernel_size=kernel_size, padding=padding, stride=stride, bias=False, groups=dim_in )), ('bn', nn.BatchNorm2d(dim_in)), ('rearrage', Rearrange('b c h w -> b (h w) c')), ])) elif method == 'avg': proj = nn.Sequential(OrderedDict([ ('avg', nn.AvgPool2d( kernel_size=kernel_size, padding=padding, stride=stride, ceil_mode=True )), ('rearrage', Rearrange('b c h w -> b (h w) c')), ])) elif method == 'linear': proj = None else: raise ValueError('Unknown method ({})'.format(method)) return proj def forward_conv(self, x, h, w): if self.with_cls_token: cls_token, x = torch.split(x, [1, h*w], 1) x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w) if self.conv_proj_q is not None: q = self.conv_proj_q(x) else: q = rearrange(x, 'b c h w -> b (h w) c') if self.conv_proj_k is not None: k = self.conv_proj_k(x) else: k = rearrange(x, 'b c h w -> b (h w) c') if self.conv_proj_v is not None: v = self.conv_proj_v(x) else: v = rearrange(x, 'b c h w -> b (h w) c') if self.with_cls_token: q = torch.cat((cls_token, q), dim=1) k = torch.cat((cls_token, k), dim=1) v = torch.cat((cls_token, v), dim=1) return q, k, v def forward(self, x, h, w): if ( self.conv_proj_q is not None or self.conv_proj_k is not None or self.conv_proj_v is not None ): q, k, v = self.forward_conv(x, h, w) q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads) k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads) v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads) attn_score = torch.einsum('bhlk,bhtk->bhlt', [q, k]) * self.scale attn = F.softmax(attn_score, dim=-1) attn = self.attn_drop(attn) x = torch.einsum('bhlt,bhtv->bhlv', [attn, v]) x = rearrange(x, 'b h t d -> b t (h d)') x = self.proj(x) x = self.proj_drop(x) return x class Block(nn.Module): def __init__(self, dim_in, dim_out, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, **kwargs): super().__init__() self.with_cls_token = kwargs['with_cls_token'] self.norm1 = norm_layer(dim_in) self.attn = Attention( dim_in, dim_out, num_heads, qkv_bias, attn_drop, drop, **kwargs ) self.drop_path = DropPath(drop_path) \ if drop_path > 0. else nn.Identity() self.norm2 = norm_layer(dim_out) dim_mlp_hidden = int(dim_out * mlp_ratio) self.mlp = Mlp( in_features=dim_out, hidden_features=dim_mlp_hidden, act_layer=act_layer, drop=drop ) def forward(self, x, h, w): res = x x = self.norm1(x) attn = self.attn(x, h, w) x = res + self.drop_path(attn) x = x + self.drop_path(self.mlp(self.norm2(x))) return x class ConvEmbed(nn.Module): """ Image to Conv Embedding """ def __init__(self, patch_size=7, in_chans=3, embed_dim=64, stride=4, padding=2, norm_layer=None): super().__init__() patch_size = to_2tuple(patch_size) self.patch_size = patch_size self.proj = nn.Conv2d( in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding ) self.norm = norm_layer(embed_dim) if norm_layer else None def forward(self, x): x = self.proj(x) B, C, H, W = x.shape x = rearrange(x, 'b c h w -> b (h w) c') if self.norm: x = self.norm(x) x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W) return x class VisionTransformer(nn.Module): """ Vision Transformer with support for patch or hybrid CNN input stage """ def __init__(self, patch_size=16, patch_stride=16, patch_padding=0, in_chans=3, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., qkv_bias=False, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, init='trunc_norm', **kwargs): super().__init__() self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models self.rearrage = None self.patch_embed = ConvEmbed( # img_size=img_size, patch_size=patch_size, in_chans=in_chans, stride=patch_stride, padding=patch_padding, embed_dim=embed_dim, norm_layer=norm_layer ) with_cls_token = kwargs['with_cls_token'] if with_cls_token: self.cls_token = nn.Parameter( torch.zeros(1, 1, embed_dim) ) else: self.cls_token = None self.pos_drop = nn.Dropout(p=drop_rate) dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule blocks = [] for j in range(depth): blocks.append( Block( dim_in=embed_dim, dim_out=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j], act_layer=act_layer, norm_layer=norm_layer, **kwargs ) ) self.blocks = nn.ModuleList(blocks) def forward(self, x): x = self.patch_embed(x) B, C, H, W = x.size() x = rearrange(x, 'b c h w -> b (h w) c') cls_tokens = None if self.cls_token is not None: # stole cls_tokens impl from Phil Wang, thanks cls_tokens = self.cls_token.expand(B, -1, -1) x = torch.cat((cls_tokens, x), dim=1) x = self.pos_drop(x) for i, blk in enumerate(self.blocks): x = blk(x, H, W) if self.cls_token is not None: cls_tokens, x = torch.split(x, [1, H*W], 1) x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W) return x, cls_tokens class ConvolutionalVisionTransformer(nn.Module): def __init__(self, in_chans=3, num_classes=1000, act_layer=nn.GELU, norm_layer=nn.LayerNorm, init='trunc_norm', spec=None): super().__init__() self.num_classes = num_classes self.num_stages = spec['NUM_STAGES'] #3 for i in range(self.num_stages): kwargs = { 'patch_size': spec['PATCH_SIZE'][i], 'patch_stride': spec['PATCH_STRIDE'][i], 'patch_padding': spec['PATCH_PADDING'][i], 'embed_dim': spec['DIM_EMBED'][i], 'depth': spec['DEPTH'][i], 'num_heads': spec['NUM_HEADS'][i], 'mlp_ratio': spec['MLP_RATIO'][i], 'qkv_bias': spec['QKV_BIAS'][i], 'drop_rate': spec['DROP_RATE'][i], 'attn_drop_rate': spec['ATTN_DROP_RATE'][i], 'drop_path_rate': spec['DROP_PATH_RATE'][i], 'with_cls_token': spec['CLS_TOKEN'][i], 'method': spec['QKV_PROJ_METHOD'][i], 'kernel_size': spec['KERNEL_QKV'][i], 'padding_q': spec['PADDING_Q'][i], 'padding_kv': spec['PADDING_KV'][i], 'stride_kv': spec['STRIDE_KV'][i], 'stride_q': spec['STRIDE_Q'][i], } stage = VisionTransformer( in_chans=in_chans, init=init, act_layer=act_layer, norm_layer=norm_layer, **kwargs ) setattr(self, f'stage{i}', stage)#用于设置属性值 in_chans = spec['DIM_EMBED'][i] dim_embed = spec['DIM_EMBED'][-1] self.norm = norm_layer(dim_embed) self.cls_token = spec['CLS_TOKEN'][-1] # Classifier head self.head = nn.Linear(dim_embed, num_classes) if num_classes > 0 else nn.Identity() trunc_normal_(self.head.weight, std=0.02) @torch.jit.ignore def no_weight_decay(self): layers = set() for i in range(self.num_stages): layers.add(f'stage{i}.pos_embed') layers.add(f'stage{i}.cls_token') return layers def forward_features(self, x): for i in range(self.num_stages): x, cls_tokens = getattr(self, f'stage{i}')(x) #getattr返回一个对象 属性对应的值 #x,cls_tokens = getattr(self,stage(i))(x) if self.cls_token: x = self.norm(cls_tokens) x = torch.squeeze(x) else: x = rearrange(x, 'b c h w -> b (h w) c') x = self.norm(x) x = torch.mean(x, dim=1) return x def forward(self, x): x = self.forward_features(x) x = self.head(x) return x @register_model def get_cls_model(config, **kwargs): msvit_spec = config.MODEL.SPEC msvit = ConvolutionalVisionTransformer( in_chans=3, num_classes=config.MODEL.NUM_CLASSES, act_layer=QuickGELU, norm_layer=partial(LayerNorm, eps=1e-5), init=getattr(msvit_spec, 'INIT', 'trunc_norm'), spec=msvit_spec ) if config.MODEL.INIT_WEIGHTS: msvit.init_weights( config.MODEL.PRETRAINED, config.MODEL.PRETRAINED_LAYERS, config.VERBOSE ) return msvit- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
模型的细节配置在yaml文件中:
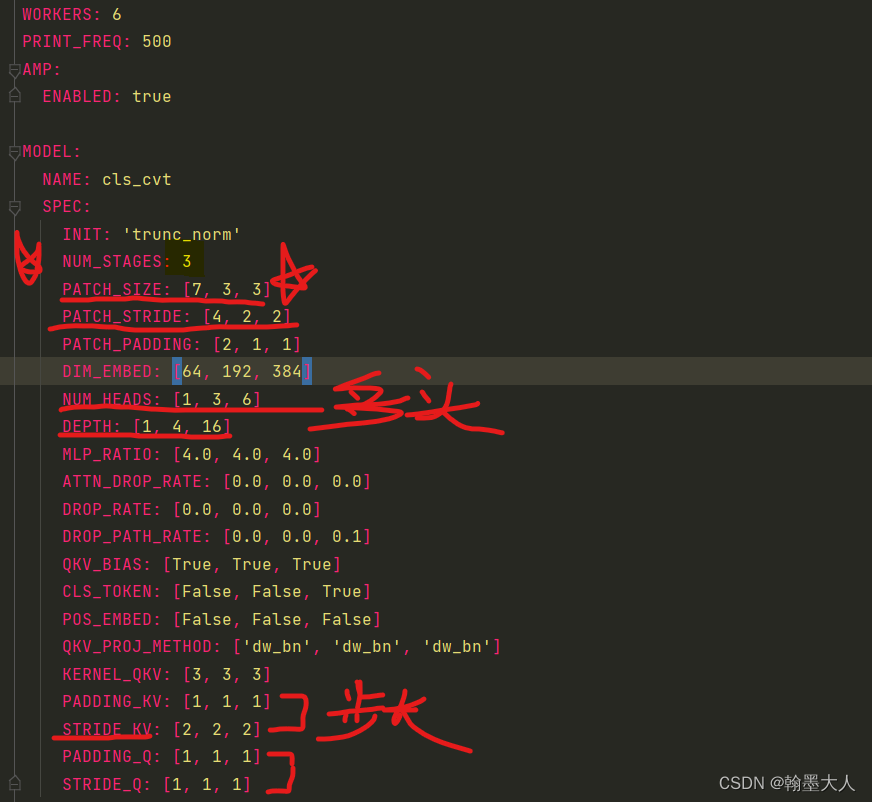
1:我们进入ConvolutionalVisionTransformer类的forward中,numstage=3,这里有个getattr函数。

getattr:返回对象属性值。返回对象a的bar属性对应的值为1。

在代码中:x, cls_tokens = getattr(self, f'stage{i}')(x)返回self对象stage{i}对应的属性值。
其中self即对ConvolutionalVisionTransformer实例化的对象,stage属性对应的为VisionTransformer。即相当于x经过VisionTransformer。

2:在VisionTransformer中。

2.1:首先进行patchembed。我们的参数为yaml中对应的参数而非默认的参数。

class ConvEmbed(nn.Module): """ Image to Conv Embedding """ def __init__(self, patch_size=7, in_chans=3, embed_dim=64, stride=4, padding=2, norm_layer=None): super().__init__() patch_size = to_2tuple(patch_size) self.patch_size = patch_size self.proj = nn.Conv2d( in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding ) self.norm = norm_layer(embed_dim) if norm_layer else None def forward(self, x): x = self.proj(x) B, C, H, W = x.shape x = rearrange(x, 'b c h w -> b (h w) c') if self.norm: x = self.norm(x) x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
我们x的大小为(1,3,224,224),进过一个输出为64,kernel=7,stride=4,padding=2的卷积,大小变为(1,64,56,56)。然后reshape为(1,3136,64)。然后对第三维度进行layernorm。再将序列reshape回原图片(1,64,56,56)。
接着再将图片reshape为(1,3136,64),进行dropout。然后遍历block。for i, blk in enumerate(self.blocks): x = blk(x, H, W)- 1
- 2
- 3
我们跳到block中,首先是depth,在第一个阶段是1,第二个为4,第三个为16。

for j in range(depth): blocks.append( Block( dim_in=embed_dim, #64 dim_out=embed_dim,#64 num_heads=num_heads,#1 mlp_ratio=mlp_ratio,#4 qkv_bias=qkv_bias,#true drop=drop_rate,#0 attn_drop=attn_drop_rate,#0 drop_path=dpr[j],#0 act_layer=act_layer,#gelu norm_layer=norm_layer,#ln **kwargs ) ) self.blocks = nn.ModuleList(blocks)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
我们到block中,H,W为x进过patchemb之后的大小(56,56)。x接着经过attention模块。
class Attention(nn.Module): def __init__(self, dim_in, dim_out, num_heads, qkv_bias=False, attn_drop=0., proj_drop=0., method='dw_bn', kernel_size=3, stride_kv=1, stride_q=1, padding_kv=1, padding_q=1, with_cls_token=True, **kwargs ): super().__init__() self.stride_kv = stride_kv self.stride_q = stride_q self.dim = dim_out self.num_heads = num_heads # head_dim = self.qkv_dim // num_heads self.scale = dim_out ** -0.5 self.with_cls_token = with_cls_token self.conv_proj_q = self._build_projection( dim_in, dim_out, kernel_size, padding_q, stride_q, 'linear' if method == 'avg' else method ) self.conv_proj_k = self._build_projection( dim_in, dim_out, kernel_size, padding_kv, stride_kv, method ) self.conv_proj_v = self._build_projection( dim_in, dim_out, kernel_size, padding_kv, stride_kv, method ) self.proj_q = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.proj_k = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.proj_v = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim_out, dim_out) self.proj_drop = nn.Dropout(proj_drop) def _build_projection(self, dim_in, dim_out, kernel_size, padding, stride, method): if method == 'dw_bn': proj = nn.Sequential(OrderedDict([ ('conv', nn.Conv2d( dim_in, dim_in, kernel_size=kernel_size, padding=padding, stride=stride, bias=False, groups=dim_in )), ('bn', nn.BatchNorm2d(dim_in)), ('rearrage', Rearrange('b c h w -> b (h w) c')), ])) elif method == 'avg': proj = nn.Sequential(OrderedDict([ ('avg', nn.AvgPool2d( kernel_size=kernel_size, padding=padding, stride=stride, ceil_mode=True )), ('rearrage', Rearrange('b c h w -> b (h w) c')), ])) elif method == 'linear': proj = None else: raise ValueError('Unknown method ({})'.format(method)) return proj def forward_conv(self, x, h, w): if self.with_cls_token: cls_token, x = torch.split(x, [1, h*w], 1) x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w) if self.conv_proj_q is not None: q = self.conv_proj_q(x) else: q = rearrange(x, 'b c h w -> b (h w) c') if self.conv_proj_k is not None: k = self.conv_proj_k(x) else: k = rearrange(x, 'b c h w -> b (h w) c') if self.conv_proj_v is not None: v = self.conv_proj_v(x) else: v = rearrange(x, 'b c h w -> b (h w) c') if self.with_cls_token: q = torch.cat((cls_token, q), dim=1) k = torch.cat((cls_token, k), dim=1) v = torch.cat((cls_token, v), dim=1) return q, k, v def forward(self, x, h, w): if ( self.conv_proj_q is not None or self.conv_proj_k is not None or self.conv_proj_v is not None ): q, k, v = self.forward_conv(x, h, w) q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads) k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads) v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads) attn_score = torch.einsum('bhlk,bhtk->bhlt', [q, k]) * self.scale attn = F.softmax(attn_score, dim=-1) attn = self.attn_drop(attn) x = torch.einsum('bhlt,bhtv->bhlv', [attn, v]) x = rearrange(x, 'b h t d -> b t (h d)') x = self.proj(x) x = self.proj_drop(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
首先生成qkv,如果带有classtoken就将其从维度分离出去。再将x reshape为图片大小,接着进行卷积操作来生成qkv。

我们进入到_build_projection函数中:根据yaml文件,method == ‘dw_bn’,所以proj就是一个由有序字典组成的序列。字典包含卷积,bn,和将图片再转换为序列。主要看一下卷积:def _build_projection(self, dim_in, dim_out, kernel_size, padding, stride, method): if method == 'dw_bn': proj = nn.Sequential(OrderedDict([ ('conv', nn.Conv2d( dim_in, dim_in, kernel_size=kernel_size, padding=padding, stride=stride, bias=False, groups=dim_in )), ('bn', nn.BatchNorm2d(dim_in)), ('rearrage', Rearrange('b c h w -> b (h w) c')), ])) elif method == 'avg': proj = nn.Sequential(OrderedDict([ ('avg', nn.AvgPool2d( kernel_size=kernel_size, padding=padding, stride=stride, ceil_mode=True )), ('rearrage', Rearrange('b c h w -> b (h w) c')), ])) elif method == 'linear': proj = None else: raise ValueError('Unknown method ({})'.format(method)) return proj- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
主要看一下卷积:卷积大小为3,步长为1,padding=1,group=dim_in,这个就是逐通道卷积。

对应于原图中的:

同理生成q和v。在将刚才分离的classtoken在维度上拼接起来。return q, k, v。
接着:q, k, v经过proj,对应于:q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads) k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads) v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads)- 1
- 2
- 3
self.proj_q = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.proj_k = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.proj_v = nn.Linear(dim_in, dim_out, bias=qkv_bias)- 1
- 2
- 3
注:在原文中作者使用的深度可分离卷积来代替传统的投射,而这里的线性投射相当于深度可分离卷积中的逐点卷积。
接着:q和k进行矩阵相乘再与v相乘,和普通的transformer一样,在经过一个线性层和dropout得到最终的x。
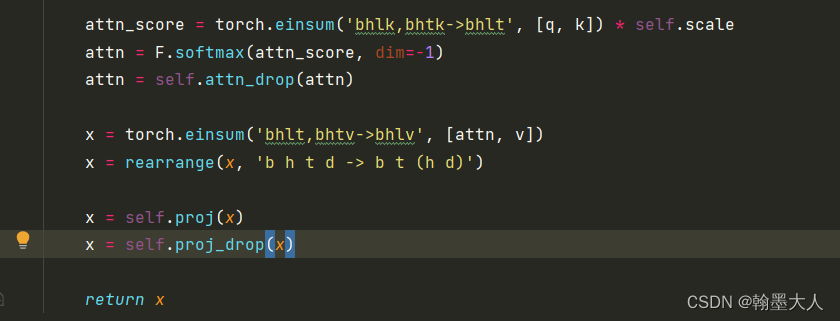
这样attention计算完毕。
与原始的x相加再进过mlp得到最终的输出。

这样block计算完毕。
在第一个stage,深度为1,所以第一个stage计算完毕。生成新的x。
这样VisionTransformer计算完毕
生成的x作为下一个stage的输出。剩下的两个stage和第一个流程一样,就不一一分析了。
参数同样可以通过 i 的索引来获得:for i in range(self.num_stages): kwargs = { 'patch_size': spec['PATCH_SIZE'][i], 'patch_stride': spec['PATCH_STRIDE'][i], 'patch_padding': spec['PATCH_PADDING'][i], 'embed_dim': spec['DIM_EMBED'][i], 'depth': spec['DEPTH'][i], 'num_heads': spec['NUM_HEADS'][i], 'mlp_ratio': spec['MLP_RATIO'][i], 'qkv_bias': spec['QKV_BIAS'][i], 'drop_rate': spec['DROP_RATE'][i], 'attn_drop_rate': spec['ATTN_DROP_RATE'][i], 'drop_path_rate': spec['DROP_PATH_RATE'][i], 'with_cls_token': spec['CLS_TOKEN'][i], 'method': spec['QKV_PROJ_METHOD'][i], 'kernel_size': spec['KERNEL_QKV'][i], 'padding_q': spec['PADDING_Q'][i], 'padding_kv': spec['PADDING_KV'][i], 'stride_kv': spec['STRIDE_KV'][i], 'stride_q': spec['STRIDE_Q'][i], }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
然后输入到VisionTransformer中:
stage = VisionTransformer( in_chans=in_chans, init=init, act_layer=act_layer, norm_layer=norm_layer, ****kwargs** )- 1
- 2
- 3
- 4
- 5
- 6
- 7
经过forward_features后,在经过head。
def forward(self, x): x = self.forward_features(x) x = self.head(x) return x- 1
- 2
- 3
- 4
- 5
- 6
self.head = nn.Linear(dim_embed, num_classes) if num_classes > 0 else nn.Identity() trunc_normal_(self.head.weight, std=0.02)- 1
- 2
即输出最后的1000个类别。这样模型搭建完毕。
总结:
1:模型的创新点为重叠的卷积操作进行token编码,在代码中也就一行实现,另一个创新点就是卷积线性投射,相比于普通的线性投射多了一个逐通道卷积。
2:除此以外在模型结构上,有两个点首先是num_head为[1,3,6],每个stage是变化的,相比于普通的VIT一般都是固定为8。第二个就是每个stage的transformer的个数[1,4,16],而VIT或者SETR都是固定的,且不是分层的,这一点有点向卷积靠拢。
3:SegFormer也用到了重叠的卷积来进行patch merging。为了保留局部的连续性。

与本文不同的是卷积的配置。

4:卷积投射的操作和MPVIT的多尺度patch embedding很像。

MPVIT的多尺度patch embedding核心代码:class DWConv2d_BN(nn.Module): """ Depthwise Separable Conv """ def __init__( self, in_ch, out_ch, kernel_size=1, stride=1, norm_layer=nn.BatchNorm2d, act_layer=nn.Hardswish, bn_weight_init=1, norm_cfg=dict(type="BN"), ): super().__init__() # dw self.dwconv = nn.Conv2d( in_ch, out_ch, kernel_size, stride, (kernel_size - 1) // 2, **groups=out_ch**, bias=False, ) # pw-linear self.pwconv = nn.Conv2d(out_ch, out_ch, 1, 1, 0, bias=False) self.bn = build_norm_layer(norm_cfg, out_ch)[1] self.act = act_layer() if act_layer is not None else nn.Identity() for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2.0 / n)) if m.bias is not None: m.bias.data.zero_() elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(bn_weight_init) m.bias.data.zero_() def forward(self, x): x = self.**dwcon**v(x) x = self.**pwconv**(x) x = self.bn(x) x = self.act(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
先进行逐通道卷积,再进行逐像素卷积。
因为我是语义分割方向,所以对于分类所用到的classtoken,classfier_head都需要删除掉,只显示最后的图片大小即可,同时为了将代码迁移到别的框架中,对他的配置文件读取全部改为直接的读取。代码如下:
from functools import partial from itertools import repeat # from torch._six import container_abcs import logging import os from collections import OrderedDict from torchsummary import summary import numpy as np import scipy import torch import torch.nn as nn import torch.nn.functional as F from einops import rearrange from einops.layers.torch import Rearrange from torch.nn.modules.utils import _pair from timm.models.layers import DropPath, trunc_normal_ class LayerNorm(nn.LayerNorm): def forward(self, x: torch.Tensor): orig_type = x.dtype ret = super().forward(x.type(torch.float32)) return ret.type(orig_type) class QuickGELU(nn.Module): def forward(self, x: torch.Tensor): return x * torch.sigmoid(1.702 * x) class Mlp(nn.Module): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x class Attention(nn.Module): def __init__(self, dim_in, dim_out, num_heads, qkv_bias=False, attn_drop=0., proj_drop=0., method='dw_bn', kernel_size=3, stride_kv=1, stride_q=1, padding_kv=1, padding_q=1, with_cls_token=True, **kwargs ): super().__init__() self.stride_kv = stride_kv self.stride_q = stride_q self.dim = dim_out self.num_heads = num_heads # head_dim = self.qkv_dim // num_heads self.scale = dim_out ** -0.5 self.with_cls_token = with_cls_token self.conv_proj_q = self._build_projection( dim_in, dim_out, kernel_size, padding_q, stride_q, 'linear' if method == 'avg' else method # s=1 ) self.conv_proj_k = self._build_projection( dim_in, dim_out, kernel_size, padding_kv,#s=2 stride_kv, method ) self.conv_proj_v = self._build_projection( dim_in, dim_out, kernel_size, padding_kv,#s=2 stride_kv, method ) self.proj_q = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.proj_k = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.proj_v = nn.Linear(dim_in, dim_out, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim_out, dim_out) self.proj_drop = nn.Dropout(proj_drop) def _build_projection(self, dim_in, dim_out, kernel_size, padding, stride, method): if method == 'dw_bn': proj = nn.Sequential(OrderedDict([ ('conv', nn.Conv2d( dim_in, dim_in, kernel_size=kernel_size, padding=padding, stride=stride, bias=False, groups=dim_in )), ('bn', nn.BatchNorm2d(dim_in)), ('rearrage', Rearrange('b c h w -> b (h w) c')), ])) elif method == 'avg': proj = nn.Sequential(OrderedDict([ ('avg', nn.AvgPool2d( kernel_size=kernel_size, padding=padding, stride=stride, ceil_mode=True )), ('rearrage', Rearrange('b c h w -> b (h w) c')), ])) elif method == 'linear': proj = None else: raise ValueError('Unknown method ({})'.format(method)) return proj def forward_conv(self, x, h, w): if self.with_cls_token: cls_token, x = torch.split(x, [1, h*w], 1) x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w) #(1,64,40,40) if self.conv_proj_q is not None: q = self.conv_proj_q(x)#(1,3600,64) else: q = rearrange(x, 'b c h w -> b (h w) c') if self.conv_proj_k is not None: k = self.conv_proj_k(x)#(1,900,64) else: k = rearrange(x, 'b c h w -> b (h w) c') if self.conv_proj_v is not None: v = self.conv_proj_v(x)#(1,900,64) else: v = rearrange(x, 'b c h w -> b (h w) c') if self.with_cls_token: q = torch.cat((cls_token, q), dim=1) k = torch.cat((cls_token, k), dim=1) v = torch.cat((cls_token, v), dim=1) return q, k, v def forward(self, x, h, w): if ( self.conv_proj_q is not None or self.conv_proj_k is not None or self.conv_proj_v is not None ): q, k, v = self.forward_conv(x, h, w) #(1,3600,64),(1,900,64),(1,900,64) q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads) #(1,1,3600,64) k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads) #(1,1,900,64) v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads) #(1,1,900,64) attn_score = torch.einsum('bhlk,bhtk->bhlt', [q, k]) * self.scale #(1,1,3600,900) attn = F.softmax(attn_score, dim=-1) attn = self.attn_drop(attn) x = torch.einsum('bhlt,bhtv->bhlv', [attn, v])#(1,1,3600,64) x = rearrange(x, 'b h t d -> b t (h d)')#(1,3600,64) x = self.proj(x) x = self.proj_drop(x) return x class Block(nn.Module): def __init__(self, dim_in, dim_out, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, **kwargs): super().__init__() self.with_cls_token = kwargs['with_cls_token'] self.norm1 = norm_layer(dim_in) self.attn = Attention( dim_in, dim_out, num_heads, qkv_bias, attn_drop, drop, **kwargs ) self.drop_path = DropPath(drop_path) \ if drop_path > 0. else nn.Identity() self.norm2 = norm_layer(dim_out) dim_mlp_hidden = int(dim_out * mlp_ratio) self.mlp = Mlp( in_features=dim_out, hidden_features=dim_mlp_hidden, act_layer=act_layer, drop=drop ) def forward(self, x, h, w): res = x #(1,3600,64) x = self.norm1(x) attn = self.attn(x, h, w) #(1,3600,64) x = res + self.drop_path(attn) #(1,3600,64) x = x + self.drop_path(self.mlp(self.norm2(x))) return x class ConvEmbed(nn.Module): """ Image to Conv Embedding """ def __init__(self, patch_size=7, in_chans=3, embed_dim=64, stride=4, padding=2, norm_layer=None): super().__init__() patch_size = _pair(patch_size) self.patch_size = patch_size self.proj = nn.Conv2d( in_chans, embed_dim, #3,64 kernel_size=patch_size, #7 stride=stride, #4 padding=padding #2 ) self.norm = norm_layer(embed_dim) if norm_layer else None def forward(self, x): x = self.proj(x) #(1,64,60,60) B, C, H, W = x.shape x = rearrange(x, 'b c h w -> b (h w) c') #(1,64,3600) if self.norm: x = self.norm(x) x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W) #(1,64,60,60) return x class VisionTransformer(nn.Module): """ Vision Transformer with support for patch or hybrid CNN input stage """ def __init__(self, patch_size=16, patch_stride=16, patch_padding=0, in_chans=3, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., qkv_bias=False, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, init='trunc_norm', **kwargs): super().__init__() self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models self.rearrage = None self.patch_embed = ConvEmbed( # img_size=img_size, patch_size=patch_size, in_chans=in_chans, stride=patch_stride, padding=patch_padding, embed_dim=embed_dim, norm_layer=norm_layer ) with_cls_token = kwargs['with_cls_token'] if with_cls_token: self.cls_token = nn.Parameter( torch.zeros(1, 1, embed_dim) ) else: self.cls_token = None self.pos_drop = nn.Dropout(p=drop_rate) dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule blocks = [] for j in range(depth): blocks.append( Block( dim_in=embed_dim, #64 dim_out=embed_dim,#64 num_heads=num_heads,#1 mlp_ratio=mlp_ratio,# qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[j], act_layer=act_layer, norm_layer=norm_layer, **kwargs ) ) self.blocks = nn.ModuleList(blocks) def forward(self, x): x = self.patch_embed(x) #(1,64,60,60) B, C, H, W = x.size() x = rearrange(x, 'b c h w -> b (h w) c') #(1,3600,64) cls_tokens = None if self.cls_token is not None: # stole cls_tokens impl from Phil Wang, thanks cls_tokens = self.cls_token.expand(B, -1, -1) x = torch.cat((cls_tokens, x), dim=1) x = self.pos_drop(x) for i, blk in enumerate(self.blocks): x = blk(x, H, W) #(1,3600,64) if self.cls_token is not None: cls_tokens, x = torch.split(x, [1, H*W], 1) x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)#(1,64,60,60) return x, cls_tokens class ConvolutionalVisionTransformer(nn.Module): def __init__(self, in_chans=(512,256,128), act_layer=nn.GELU, norm_layer=nn.LayerNorm, init='trunc_norm', patch_size=(7,3,3), patch_stride=(4,2,2), patch_padding=(2,1,1), embed_dim=(64,192,384), depth=(1,4,16), num_heads=(1,3,6), mlp_ratio=(4,4,4), qkv_bias=(True,True,True), drop_rate=(0,0,0), attn_drop_rate=(0,0,0,), drop_path_rate=(0,0,0.1), with_cls_token=(False, False, True), method=('dw_bn', 'dw_bn', 'dw_bn'), kernel_size=(3,3,3), padding_q=(1,1,1), padding_kv=(1,1,1), stride_kv=(2,2,2), stride_q=(1,1,1), spec=None): super().__init__() self.num_stages = 3 for i in range(self.num_stages): kwargs = { 'in_chans' : in_chans[i], 'patch_size': patch_size[i], 'patch_stride': patch_stride[i], 'patch_padding': patch_padding[i], 'embed_dim': embed_dim[i], 'depth': depth[i], 'num_heads': num_heads[i], 'mlp_ratio': mlp_ratio[i], 'qkv_bias': qkv_bias[i], 'drop_rate': drop_rate[i], 'attn_drop_rate': attn_drop_rate[i], 'drop_path_rate': drop_path_rate[i], 'with_cls_token': with_cls_token[i], 'method': method[i], 'kernel_size': kernel_size[i], 'padding_q': padding_q[i], 'padding_kv': padding_kv[i], 'stride_kv': stride_kv[i], 'stride_q': stride_q[i], } stage = VisionTransformer( init=init, act_layer=act_layer, norm_layer=norm_layer, **kwargs ) setattr(self, f'stage{i}', stage)#用于设置属性值 def forward(self, x,i =0): # for i in range(self.num_stages): # i = [0,1,2,3] x_1 = getattr(self, f'stage{i}')(x) #(1,64,60,60) #getattr返回一个对象 属性对应的值 return x_1 def main(): # --------------------------------实例化ConvolutionalVisionTransformer------------------------- model = ConvolutionalVisionTransformer() # (传入参数) model.eval() rgb_image = torch.randn(1, 512, 240, 240) summary(model, input_size=[(512, 240, 240)], device='cpu') with torch.no_grad(): output = model(rgb_image) print(output.shape) if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
其中num_stage控制stage的个数,depth控制每个stage的块数。
这样我们每经过一个stage,我们就去ConvolutionalVisionTransformer对应的参数中取对应的值。这样就形成了新的kwargs,然后在输入到VisionTransformer中,就替换掉原始的默认值。
同时我们可以在forward函数中,指定i的值,这样在实例化的时候,指定i的值,ConvolutionalVisionTransformer就具有很大的灵活性。因为原文是穿行的transformer,这样也可以使用并行的transformer,且可以在任何的位置使用。
因此就可以把代码迁移到其他框架中。 -
相关阅读:
【iMessage软件苹果相册推】对付nvm应当可以使用brew直接安装brew install flow 到这里根本的环境
学习太极创客 — ESP8226 (十三)OTA
贪心算法-会议室问题
Cesium加载3D Tiles模型
Java多线程按顺序输出10以内的奇偶数
如何系统地学习 JavaScript?
线性回归分析----学院综测成绩能显示出什么信息?
在C#中如何自定义配置上周和本周起始日来查询业务数据?
[免费专栏] Android安全之ADB常用命令
一、 android studio安装
- 原文地址:https://blog.csdn.net/qq_43733107/article/details/127769755
