-
Java高级——解释执行
概述
不同虚拟机执行引擎在执行字节码时,可分为解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)
下图中间分支为解析执行的过程,底部分支为程序代码到目标机器代码的生成过程
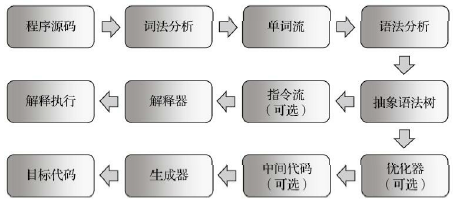
Javac编译器完成了程序源码、词法分析、语法分析、抽象语法树、字节码指令流过程,独立于JVM,而解释器则在JVM内部
基于栈的指令集与基于寄存器的指令集
基于栈的指令集架构,大部分为零地址指令,依赖操作数栈访问和存储数据,如进行1+1
iconst_1 iconst_1 iadd istore_0- 1
- 2
- 3
- 4
- iconst_1把常量1压入栈
- iadd把栈顶两个值出栈相加再放回栈顶
- istore_0把栈顶值放到局部变量表Slot 0中
基于寄存器的指令集架构,指令包含2个参数,依赖寄存器访问和存储数据,同样进行1+1
mov eax, 1 add eax, 1- 1
- 2
- mov把eax寄存器值置为1
- add把值加1,仍保持在eax
基于栈的指令集 基于寄存器的指令集 执行速度慢,但可把频繁访问的数据(如程序计数器)放到寄存器中以提升性能 执行速度快 可移植 不可移植,寄存器与硬件相关 指令短(一个字节对应一条指令),但完成相同功能的指令数量更多 指令长(携带参数),但指令数量少 无需考虑空间分配问题,所需空间都在栈上操作 直接使用物理内存,需考虑空间规划 解释执行
JVM所使用的是基于栈的字节码解释执行引擎,以下面程序为例
public int calc() { int a = 100; int b = 200; int c = 300; return (a + b) * c; }- 1
- 2
- 3
- 4
- 5
- 6
翻译成字节码如下,操作数栈深度为2,局部变量表槽为4
public int calc(); Code: stack=2, locals=4, args_size=1 0: bipush 100 2: istore_1 3: sipush 200 6: istore_2 7: sipush 300 10: istore_3 11: iload_1 12: iload_2 13: iadd 14: iload_3 15: imul 16: ireturn }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
首先执行偏移地址为0的指令,Bipush将单字节的整型值100推入操作数栈顶

执行偏移地址为2的指令,istore_1将操作数栈顶的整型值100出栈并存放到Slot 1,后续4条指令类似,省略图示

执行偏移地址为11的指令,iload_1将局部变量表Slot 1中的整型值100复制到操作数栈顶

执行偏移地址为12的指令,iload_2将局部变量表Slot 2中的整型值200复制到操作数栈顶

执行偏移地址为13的指令,iadd将操作数栈中头两个栈顶元素(100和200)出栈,做整型加法,然后把结果(300)重新入栈

执行偏移地址为14的指令,iload_3将局部变量槽Slot 3中的300入栈。下一条imul与iadd类似,出栈做除法再入栈,省略图示

执行偏移地址为16的指令,ireturn将结束方法执行并将操作数栈顶的整型值(90000)返回给该方法的调用者

上面演示只是概念模型,实际执行时会做出一系列优化来提高性能
-
相关阅读:
【FPGA】IP核
linux环境下tomcat中catalina.out文件过大问题
Speedoffice有几种版本?适合什么系统使用呢?
如何做到一套FPGA工程无缝兼容两款不同的板卡?
基于改进二进制粒子群算法的电力系统机组组合——复现
【领域驱动设计】架构和 DDD Kata:在线汽车经销商
synchronized和lock的区别
C++ 表驱动方法代替if-else
Centos8安装docker并配置Kali Linux图形化界面
Node开发后台API接口项目
- 原文地址:https://blog.csdn.net/qq_35258036/article/details/127770685
