-
Pandas入门
Pandas入门
Pandas简介
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
Pandas安装
安装 pandas 需要基础环境是 Python,开始前我们假定你已经安装了 Python 和 Pip。
使用 pip 安装 pandas:
pip install pandas- 1
安装成功后,我们就可以导入 pandas 包使用:
import pandas- 1
我们在使用pandas时,一般使用它的别名:
import pandas as pd- 1
这是已经约定俗成,建议大家这样使用。
查看 pandas 版本
import pandas as pd # 导入 pandas 一般使用别名 pd 来代替 print(pd.__version__)- 1
- 2
- 3
- 4
- 5
Pandas的数据结构
DataFrame(数据帧)和 Series(序列)是 pandas 的核心数据结构。DataFrame 和二维的 NumPy 数组类似,但是
它的行和列有对应的标签,并且每一列都可以存储不同类型的数据。从 DataFrame 中提取一行或一列时,你会得到一个一维的 Series。类似地,Series 相当于带标签的一维 NumPy 数组。请看下图中的 DataFrame 的结构,你立马就会发现 DataFrame 可以被当作基于Python 的工作表。
Pandas 使用 Series 和 DataFrame 作为数组数据的存储框架,数据进入这两种框架后,我们就可以利用它们提供的强大处理方法经行处理。
Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 是pandas 最基础的数据结构。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)- 1
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
(1)使用列表和元组
创建一个简单的 Series 实例:
import pandas as pd a = [1, 2, 3] #使用列表 myvar = pd.Series(a) print(myvar)- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:

从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
import pandas as pd a = [1, 2, 3] myvar = pd.Series(a) print(myvar) print(myvar[1])- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果如下:

我们可以指定索引值,并根据索引值读取数据,如下实例:
import pandas as pd a = ["Google", "Baidu", "Wiki"] myvar = pd.Series(a, index=["x", "y", "z"]) print(myvar) print(myvar["y"])- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果如下:

通过列表、元组创建Series时,索引大小必须和列表大小一致。
(2)使用字典
我们也可以使用 key/value 对象,类似字典来创建 Series:
import pandas as pd sites = {1: "Google", 2: "Baidu", 3: "Wiki"} myvar = pd.Series(sites) print(myvar)- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:

从上图可知,字典的 key 变成了索引值。
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
import pandas as pd sites = {1: "Google", 2: "Baidu", 3: "Wiki"} myvar = pd.Series(sites, index=[1, 2]) print(myvar)- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:

设置 Series 名称参数:
import pandas as pd sites = {1: "Google", 2: "Baidu", 3: "Wiki"} myvar = pd.Series(sites, index=[1, 2], name="Pandas-Series-Test") print(myvar)- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:

DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。


DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)- 1
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
(1)使用列表
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
#使用列表创建 import pandas as pd data = [['Google', 10], ['Baidu', 12], ['Wiki', 13]] df = pd.DataFrame(data, columns=['Site', 'Age']) print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果为:

(2)使用字典
字典中的键为列名,值一般为一个列表或者元组。
import pandas as pd data = {'Site': ['Google', 'Baidu', 'Wiki'], 'Age': [10, 12, 13]} df = pd.DataFrame(data) print(df)- 1
- 2
- 3
- 4
- 5
- 6
输出结果为:
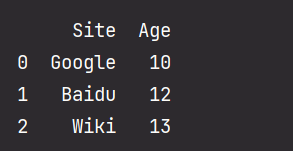
从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):

(3)字典组成的列表
还可以使用字典(key/value),其中字典的 key 为列名:
#使用字典创建 import pandas as pd data = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}] df = pd.DataFrame(data) print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果为:

没有对应的部分数据为 NaN。
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
import pandas as pd data = { "calories": [420, 380, 390], "duration": [50, 40, 45] } # 数据载入到 DataFrame 对象 df = pd.DataFrame(data) # 返回第一行 print(df.loc[0]) # 返回第二行 print(df.loc[1])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出结果为:

**注意:**返回结果其实就是一个 Pandas Series 数据。
也可以返回多行数据,使用 [[ … ]] 格式,… 为各行的索引,以逗号隔开:
import pandas as pd data = { "calories": [420, 380, 390], "duration": [50, 40, 45] } # 数据载入到 DataFrame 对象 df = pd.DataFrame(data) # 返回第一行和第二行 print(df.loc[[0, 1]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出结果为:

**注意:**返回结果其实就是一个 Pandas DataFrame 数据。
我们可以指定索引值,如下实例:
import pandas as pd data = { "calories": [420, 380, 390], "duration": [50, 40, 45] } df = pd.DataFrame(data, index = ["day1", "day2", "day3"]) print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果为:

Pandas 可以使用 loc 属性返回指定索引对应到某一行:
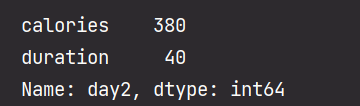
import pandas as pd data = { "calories": [420, 380, 390], "duration": [50, 40, 45] } df = pd.DataFrame(data, index=["day1", "day2", "day3"]) # 指定索引 print(df.loc["day2"])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出结果为:
索引
在后续的内容中,在不同场景下可能会对索引使用以下名称。
- 索引(index):行和列上的标签,标识二维数据坐标的行索引和列索引,默认情况下,指的是每一行的索引。如果是 Series,那只能是它行上的索引。列索引又被称为字段名、表头。
- 自然索引、数字索引:行和列的0~n(n为数据长度-1)形式的索引,数据天然具有的索引形式。虽然可以指定为其他名称,但在有些方法中依然可以使用。
- 标签(label):行索引和列索引,如果是Series,那只能是它行上的索引。
- 轴(axis):仅用在DataFrame结构中,代表数据的方向,如行和列,用0代表列(默认),1代表行。
Pandas的数据类型
数据类型查看
先加载数据:
import pandas as pd df=pd.read_excel('../data/course_participants.xlsx')- 1
- 2
- 3

查看df中各列的数据类型:
df.dtypes # 各字段的数据类型- 1

可以看到,name、country 和 continent 列为object,user_id 和age为 int64,score为float64。
查看具体字段的类型:
df.name.dtype # dtype('O')- 1
- 2
df.name 是一个Series,所以需要使用.dtype而不是.dtypes。
常见数据类型
Pandas 提供了以下常见的数据类型,默认的数据类型是int64和 float64,文字类型是object。
- float
- int
- bool
- datetime64[ns]
- datetime64[ns,tz]
- timedelta64[ns]
- timedelta[ns]
- category
- object
- string
这些数据类型大多继承自 NumPy的相应数据类型,Pandas 提供了可以进行有限的数据类型转换的方法,如将数字型转为字符型。
d 和age为 int64,score为float64。查看具体字段的类型:
df.name.dtype # dtype('O')- 1
- 2
df.name 是一个Series,所以需要使用.dtype而不是.dtypes。
常见数据类型
Pandas 提供了以下常见的数据类型,默认的数据类型是int64和 float64,文字类型是object。
- float
- int
- bool
- datetime64[ns]
- datetime64[ns,tz]
- timedelta64[ns]
- timedelta[ns]
- category
- object
- string
这些数据类型大多继承自 NumPy的相应数据类型,Pandas 提供了可以进行有限的数据类型转换的方法,如将数字型转为字符型。
-
相关阅读:
【无标题】
【Python笔记-设计模式】适配器模式
Python实现mysql基于配置文件的全自动增量数据备份
Mysql关闭严格模式
支持向量机核技巧:10个常用的核函数总结
企业微信hook接口协议,ipad协议http,发送大视频文件
测试岗面试,一份好的简历总可以让人眼前一亮
PAT 甲级 A1087 All Roads Lead to Rome
【5G NAS】5G SUPI 和 SUCI 标识符详解
1.12.C++项目:仿muduo库实现并发服务器之LoopThreadPool模块的设计
- 原文地址:https://blog.csdn.net/W_chuanqi/article/details/127652830