-
【网络篇】第四篇——网络字节序
网络字节序和本机转换
计算机在存储数据时是有大小端的概念的:
- 大端模式: 数据的高字节内容保存在内存的低地址处,数据的低字节内容保存在内存的高地址处。
- 小端模式: 数据的高字节内容保存在内存的高地址处,数据的低字节内容保存在内存的低地址处。
如果编写的程序只在本地机器上运行,那么是不需要考虑大小端问题的,因为同一台机器上的数据采用的存储方式都是一样的,要么采用的都是大端存储模式,要么采用的都是小端存储模式。但如果涉及网络通信,那就必须考虑大小端的问题,否则对端主机识别出来的数据可能与发送端想要发送的数据是不一致的。
例如,现在两台主机之间在进行网络通信,其中发送端是小端机,而接收端是大端机。发送端将发送缓冲区中的数据按内存地址从低到高的顺序发出后,接收端从网络中获取数据依次保存在接收缓冲区时,也是按内存地址从低到高的顺序保存的。
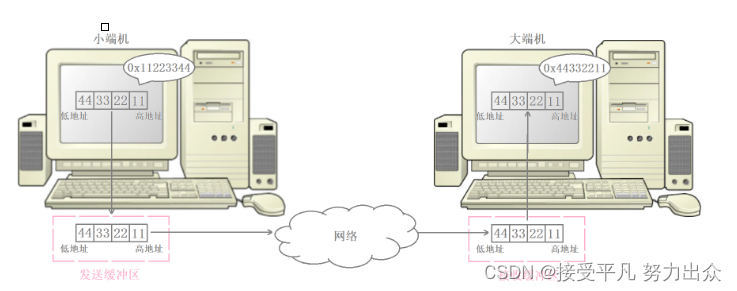
但由于发送端和接收端采用的分别是小端存储和大端存储,此时对于内存地址从低到高为44332211的序列,发送端按小端的方式识别出来是0x11223344,而接收端按大端的方式识别出来是0x44332211,此时接收端识别到的数据与发送端原本想要发送的数据就不一样了,这就是由于大小端的偏差导致数据识别出现了错误。
由于我们不能保证通信双方存储数据的方式是一样的,因此网络当中传输的数据必须考虑大小端问题。因此TCP/IP协议规定,网络数据流采用大端字节序,即低地址高字节。无论是大端机还是小端机,都必须按照TCP/IP协议规定的网络字节序来发送和接收数据。
- 如果发送端是小端,需要先将数据转成大端,然后再发送到网络当中。
- 如果发送端是大端,则可以直接进行发送。
- 如果接收端是小端,需要先将接收到数据转成大端后再进行数据识别。
- 如果接收端是大端,则可以直接进行数据识别。
在这个例子中,由于发送端是小端机,因此在发送数据前需要先将数据转成大端,然后再发送到网络当中,而由于接收端是大端机,因此接收端接收到数据后可以直接进行数据识别,此时接收端识别出来的数据就与发送端原本想要发送的数据相同了。

需要注意的是,所有的大小端的转化工作是由操作系统来完成的,因为该操作属于通信细节,不过也有部分的信息需要我们自行进行处理,比如端口号和IP地址。
如何证明自己的机器采用了哪种字节顺序:
- /* 确定你的电脑是大端字节序还是小端字节序 */
- #include
- int check1()
- {
- int i = 1; //1在内存中的表示: 0x00000001
- char *pi = (char *)&i; //将int型的地址强制转换为char型
- return *pi == 0; //如果读取到的第一个字节为1,则为小端法,为0,则为大端法
- }
- int main()
- {
- if (check1() == 1)
- printf("big\n");
- else
- printf("little\n");
- return 0;
- }
- 第二种方法,我们用联合结构解决,其本质差异不大
- /* 确定你的电脑是大端字节序还是小端字节序 */
- #include
- int check2()
- {
- union test {
- char ch;
- int i;
- }test0;
- test0.i = 1;
- return test0.ch == 0;
- }
- int main()
- {
- if (check1() == 1)
- printf("big\n");
- else
- printf("little\n");
- return 0;
- }
为什么网络字节序采用的是大端?而不是小端?
网络字节序采用的是大端,而主机字节序一般采用的是小端,那为什么网络字节序不采用小端呢?如果网络字节序采用小端的话,发送端和接收端在发生和接收数据时就不用进行大小端的转换了。
该问题有很多不同说法,下面列举了两种说法:
- 说法一: TCP在Unix时代就有了,以前Unix机器都是大端机,因此网络字节序也就采用的是大端,但之后人们发现用小端能简化硬件设计,所以现在主流的都是小端机,但协议已经不好改了。
- 说法二: 大端序更符合现代人的读写习惯。
字节序转换函数
为使网络程序具有可移植性,使同样的C代码在大端和小端计算机上编译后都能正常运行,系统提供了四个函数,可以通过调用以下库函数实现网络字节序和主机字节序之间的转换。
- #include
- //将主机字节序转换为网络字节序
- unit32_t htonl (unit32_t hostlong);
- unit16_t htons (unit16_t hostshort);
- //将网络字节序转换为主机字节序
- unit32_t ntohl (unit32_t netlong);
- unit16_t ntohs (unit16_t netshort);
- 说明:h -----host;n----network ;s------short;l----long。
- htons()--"Host to Network Short"
- htonl()--"Host to Network Long"
- ntohs()--"Network to Host Short"
- ntohl()--"Network to Host Long"
- 函数名当中的h表示host,n表示network,l表示32位长整数,s表示16位短整数。
- 例如htonl表示将32位长整数从主机字节序转换为网络字节序。
- 如果主机是小端字节序,则这些函数将参数做相应的大小端转换然后返回。
- 如果主机是大端字节序,则这些函数不做任何转换,将参数原封不动地返回。
-
相关阅读:
從turtle海龜動畫 學習 Python - 高中彈性課程系列 10.2 藝術畫 Python 製作生成式藝術略覽
阿里一面 | 说说你对 MySQL 死锁的理解
FlinkSql之TableAPI详解
如何用比例-积分(PI)控制器给(399.94 s)/(0.0000000007 s^2 + 0.000014*s + 1)传递函数设计闭环传递函数
数组的基本知识
spring之AOP(面向切面编程)之详结
基于.net的应用开发技术-作业一
day26-xpath数据解析
StrPool.C_COLON 和 StringPool.COLON 的拼接问题,踩坑了
长短期记忆神经网络(LSTM)的回归预测(免费完整源代码)【MATLAB】
- 原文地址:https://blog.csdn.net/m0_58367586/article/details/127559496
