-
【Hadoop---14】MapReduce:OutputFormat『 TextOutputFormat | 自定义OutputFormat』
1. OutputFormat阶段流程
OutputFormat阶段是MapReduce的一个阶段。
其详细流程见:MapReduce详细流程
2. OutputFormat与其子类关系图
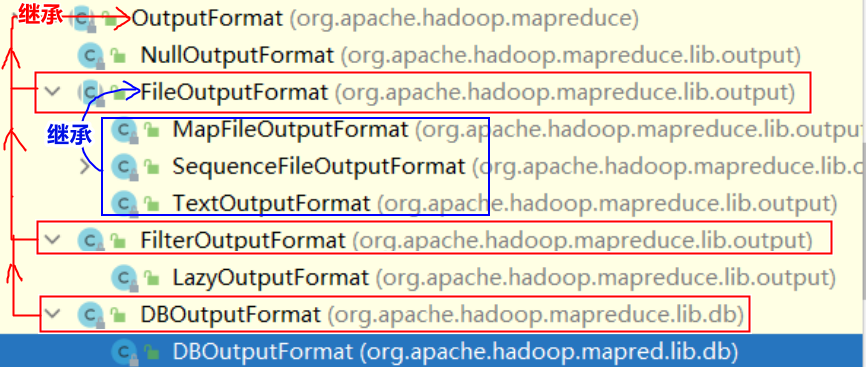
接下来主要介绍TextOutputFormat类的读取机制 和 如何自定义类去自定义读取机制。3. TextOutputFormat(默认)
一个ReduceTask配置一个OutputFormat。而默认OutputFormat使用TextOutputFormat的写入机制。
TextOutputFormat的写入机制:将从ReduceTask收到的所有键值对追加的写入到一个文件中。
故使用TextOutputFormat,一个ReduceTask最终只会产生一个文件。
4. 自定义OutputFormat类
4.1 什么时候需要自定义OutputFormat类
如果需要自定义写入机制,就必须自定义类去继承OutputFormat / FileOutputFormat。例如:
- 输出数据到Mysql、HBase、Elasticsearch等存储框架中。
- 将一个ReduceTask的输出数据分成多个文件存储
等等
4.2 自定义OutputFormat步骤
- 自定义OutputFormat 类,该类需要继承 OutputFormat / FileOutputFormat 抽象类,并重写
getRecordWriter方法 - 自定义RecordWriter类,需要继承RecordWriter抽象类,并重写
write()方法和close()方法。 - 在Driver类中将自定义OutputFormat类与job绑定起来。
4.3 自定义OutputFormat示例
package com.study.mapreduce.output; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.UUID; /** * 自定义输出: * 在job中设置输出文件夹路径,如果结果的key带有spring就输出到指定文件夹下的test01.txt,否则输出到指定文件夹下的test02.txt */ public class MyOutputFormat extends FileOutputFormat<Text, IntWritable> { @Override public RecordWriter<Text, IntWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { // 返回一个我们自定义的输出Writer MyRecordWriter writer = new MyRecordWriter(job); return writer; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.4 自定义RecordWriter示例
/** * 自定义RecordWriter类,需要继承RecordWriter */ class MyRecordWriter extends RecordWriter<Text, IntWritable> { private FSDataOutputStream fsOut1; private FSDataOutputStream fsOut2; public MyRecordWriter(TaskAttemptContext job) { try { // 创建输出流 FileSystem fileSystem = FileSystem.get(job.getConfiguration()); String defaultPath = "/app/WordCount/myoutput/" + UUID.randomUUID().toString(); String pathParent = job.getConfiguration().get(FileOutputFormat.OUTDIR, defaultPath); // 读取job设置的输出路径 // 创建两个输出的文件 // 获取job中配置的SpringFileName、OtherFileName String subPath1 = pathParent + "/" + job.getConfiguration().get("SpringFileName"); String subPath2 = pathParent + "/" + job.getConfiguration().get("OtherFileName"); fsOut1 = fileSystem.create(new Path(subPath1)); fsOut2 = fileSystem.create(new Path(subPath2)); } catch (IOException e) { e.printStackTrace(); } } /** * 写操作 */ @Override public void write(Text key, IntWritable value) throws IOException, InterruptedException { // 根据key是否为spring,输出到指定文件 if("spring".equalsIgnoreCase(key.toString())) { fsOut1.writeBytes(key + "@" + value + "\n"); } else { fsOut2.writeBytes(key + "@" + value + "\n"); } } /** * 关闭IO流 */ @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { IOUtils.closeStream(fsOut1); IOUtils.closeStream(fsOut2); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
4.5 自定义OutputFormat类与job绑定示例
// 设置自定义OutputFormat job.setOutputFormatClass(MyOutputFormat.class); // 给job添加一个属性,用作配置输出文件路径。属性名为FileOutputFormat.OUTDIR常量 // 程序中可以通过 job.getConfiguration().get(FileOutputFormat.OUTDIR) 获取 // FileOutputFormat的 _SUCCESS 文件默认也会生成到该路径下 FileOutputFormat.setOutputPath(job, new Path("/app/WordCount/myoutput/output1")); // 给job再添加两个属性SpringFileName、OtherFileName job.getConfiguration().set("SpringFileName", "test01.txt"); job.getConfiguration().set("OtherFileName", "test02.txt");- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
相关阅读:
备战数学建模30-回归分析2
基于PaddleOCR开发easy click文字识别插件
C++lambda表达式
新增用户登录和资产登录通知功能,支持指定目录运行作业中心命令,JumpServer堡垒机v3.8.0发布
Java私活500元,做个JavaWeb仓储管理网站(二)
设计模式-策略设计模式(一般通过工厂方法模式来实现策略类的声明)
数码3C零售门店运营,智慧显示有何优势?以清远电信为例。
成功案例(IF=12.2)| 肠道代谢组、微生物组和脑功能的综合分析揭示了肠-脑轴在长寿中的作用
Select、Poll、Epoll的优缺点
Docker学习笔记(一)安装Docker、镜像操作、容器操作、数据卷操作
- 原文地址:https://blog.csdn.net/qq_43546676/article/details/127412647