-
Python文件操作篇
目录
一、内置函数open()
1、概念
使用指定模式打开指定文件并创建文件对象
2、格式、模式
(1)open(file, mode = 'r' , buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
(2)file参数:要操作的文件名称,当文件不在当前文件夹或子文件夹中,建议用绝对路径
(3)mode参数:打开文件后的处理方式
文件打开模式 模式 说明 r 读模式(默认模式,可省略),如果文件不存在,抛出异常 w 写模式,如果文件已存在,先清空原有内容,如果不存在,创建新文件 x 写模式,创建新文件,如果文件已存在,则抛出异常 a 追加模式,不覆盖文件中原有内容 b 二进制模式(可与r、w、x或a模式组合使用,如:对图片的读写),打开文件时不允许指定参数encoding t 文本模式(默认模式,可省略) + 读、写模式(可与其他模式组合使用) ①衍生模式:'rb'是二进制文件只读模式、'wb'是二进制只写模式
②'r'、'w'、'x'以及衍生模式打开文件时文件指针位于文件头,而'a'、'ab'、‘a+’模式打开文件时文件指针位于文件尾
③注意:'w'和'x'都是写模式,在目标文件不存在时处理结果是一样的,但是通过目标函数已存在,'w'模式会清空原有的内容,而'x'模式会抛出异常
④注意:同时读写,不是用'rw'模式,而是用'r+'、'w+'或'a+'的组合方式('r+'模式要求文件已存在)
(4)encoding参数:指定对文本进行编码和解码的方式,只适用于文本模式,如:GBK、UTF8、CP936
3、执行
(1)执行正常后,open()函数返回1个文件对象
(2)如果指定文件不存在,访问权限不够,磁盘空间不够或其他原因导致创建文件对象失败,则抛出IOError异常
二、文件对象常用方法
文件对象的常用方法 方法 功能 close() 把缓冲区的内容写入文件,同时关闭文件,释放文件对象 read([size]) 从文本文件中 / 二讲制文件中读取并返回size个字符 / 字节,省略size参数表示读取文件中全部内容 readline() 从文本文件中读取并返回一行内容 readlines() 返回包含文本文件中每行内容的列表 seek(cookie,whence=0,/) 定位文件指针,把文件指针移动到相对于 whence的偏移量为cookie的位置。其中 whence为0表示文件头,1表示当前位置,2表示文件尾。对于文本文件,whence=2 时cookie必须为0;对于二进制文件,whence=2时 cookie可以为负数;不指定时,默认为0 write(s) 把s的内容写入文件,如果写入文本文件则s应为字符串;如果写入二进制文件则s应为字节串 writelines(s) 把列表s中的所有字符串写入文本文件,但并不在s中每个字符串后面自动增加换行符。也就是说,如果想让s中的每个字符串写入文本文件时各占一行,应自己编写每个字符串以换行符结束 注意:read()、readline()、write()方法读写文件时,表示当前位置的文件指针会自动向后移动,并且每次都是从前开始读写
1、read()方法
- f = open('itheima.txt', 'r')
- content = f.read(12)
- print(content)
- print("-"*30)
- content = f.read()
- print(content)
- f.close()
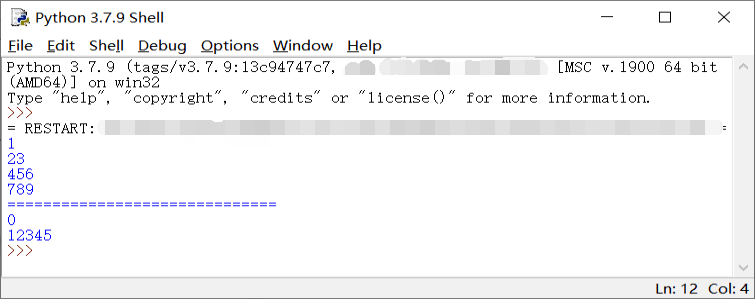
2、readline()方法
- f = open('itheima.txt', 'r')
- content = f.readline()
- print("1:%s"%content)
- content = f.readline()
- print("2:%s"%content)
- f.close()

3、readlines()方法
- f = open('itheima.txt', 'r')
- content = f.readlines()
- i = 1
- for temp in content:
- print("%d:%s" % (i, temp))
- i += 1
- f.close()

4、tell()方法
- # 打开一个已经存在的文件
- f = open("itheima.txt", "r")
- str = f.read(4)
- print("读取的数据是 : ", str)
- # 查找当前位置
- position = f.tell()
- print("当前文件位置 : ", position)
- str = f.read(8)
- print("读取的数据是 : ", str)
- # 查找当前位置
- position = f.tell()
- print("当前文件位置 : ", position)
- str = f.read(3)
- print("读取的数据是 : ", str)
- # 查找当前位置
- position = f.tell()
- print("当前文件位置 : ", position)
- f.close()

5、seek()方法
- f=open("itheima.txt","r")
- str=f.read(15)
- print("读取的数据是:",str)
- #查找当前位置
- position=f.tell()
- print("当前文件的位置是:",position)
- #重新设置位置
- f.seek(4)
- #查找当前位置
- position=f.tell()
- print("当前文件的位置是:",position)
- f.close()

三、上下文管理语句with
1、with功能
(1)文件打开失败时,会自动关闭资源
(2)可以自动管理资源,无论什么原因跳出with块,总能保证文件被正确关闭
(3)还可以用于数据库连接、网络连接或类似场合
2、格式
- with open(filename, mode ,encoding) as fp:
- #写通过文件对象fp读写文件内容的语句块
3、代码例子
合并两个.txt文件的内容,两个文件的多行内容交替写入结果文件,如果一个文件内容较少,则把另一个文件的剩余内容写入结果文件尾部
- def mergeTxt(txtFiles):
- with open('result.txt','w',encoding='utf-8') as fp:
- with open(txtFiles[0]) as fp1,open(txtFiles[1]) as fp2:
- while True:
- #交替读取文件1和文件2中的行,写入结果文件
- line1 = fp1.readline()
- if line1:
- fp.write(line1)
- else:
- #如果文件1结束,结束循环
- flag = False
- break
- line2 = fp2.readline()
- if line2:
- fp.write(line2)
- else:
- #如果文件2结束,结束循环
- flag = True
- break
- #获取尚未结束的文件对象
- fp3 = fp1 if flag else fp2
- #把剩余内容写入结果文件
- for line in fp3:
- fp.write(line)
- txtFiles = ['1.txt','2.txt']
- mergeTxt(txtFiles)

四、JSON文件操作
1、概念:JSON是一种轻量级的数据交换格式
2、使用
(1)dump()函数:把对象序列化为字符串,并直接写入文件
(2)loads()函数:把JSON格式字符串/文件还原为Python对象
3、代码例子
把包含若干房屋信息的列表写入JSON文件,然后再读取并输出这些信息
- import json
- information = [
- {'小区名称':'小区A','均价':8000,'月交易量':20},
- {'小区名称':'小区B','均价':8500,'月交易量':35},
- {'小区名称':'小区C','均价':7800,'月交易量':50},
- {'小区名称':'小区D','均价':12000,'月交易量':18}
- ]
- with open('房屋信息.json','w') as fp:
- json.dump(information, fp, indent=4, ensure_ascii=False, separators=[',',':'])
- with open('房屋信息.json') as fp:
- information = json.load(fp)
- for info in information:
- print(info)

-
相关阅读:
16.偏差、方差、正则化、学习曲线对模型的影响
协作乐高 All In One:DAO工具大全
Kotlin:崛起中的下一代编程语言
Vue+elementUI 导出word打印
OA系统、ERP系统、MIS系统的区别
Android 11 热点(softap)流程分析(二) WifiManager--AIDL
魔众智能AI系统v2.1.0版本支持主流大模型(讯飞星火、文心一言、通义千问、腾讯混元、Azure、MiniMax、Gemini)
无法远程连接到kafka
R语言ggplot2可视化:使用ggpubr包的ggboxplot函数可视化箱图、width参数自定义箱图中箱体的宽度
ai_drive42_如何兼容一致性和互补性?多模态融合基础问题及算法解析
- 原文地址:https://blog.csdn.net/qq_51478745/article/details/127310939
