-
Linux Shell脚本一文读懂
目录
1、什么是shell
shell脚本是一个文件,里面存放的是特定格式的指令,系统可以使用脚本解析器翻译或解析指令并执行(无需编译)。shell脚本的本质是 shell命令的有序集合
1.1 第一个shell脚本
Shell 脚本创建总共分为三步:
- 创建shell脚本

编辑Shell脚本内容如下hello_shell.sh:
- #! /bin/bash
- echo "Hello World, Shell"
- shell脚本权限赋值

- 执行shell脚本

2、Shell 变量
shell允许用户建立变量存储数据,但不支持数据类型(整型、字符、浮点型), 任何赋给变量的值都被解释为一串字符。
2.1 Shell 变量命名规则
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线 _。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
2.2 Shell 变量类型
Shell变量类型主要分为三大类:1、用户变量、2、系统变量、3、环境变量
2.2.1 用户变量
用户自定义变量,通常使用全大写定义变量名,方便识别;
实例:定义用户自定义变量MSG,并输出。
- #! /bin/bash
- MSG="用户自定义变量"
- echo "$MSG"
实例效果截图:

2.2.2 系统变量
用于对参数判断和命令返回值判断时使用
实例:输出系统变量:$0
- #!/bin/bash
- echo "脚本名称为: $0"
实例效果截图:

系统变量总结
$0 #当前脚本的名称
$n #传递给脚本或函数的第n个参数,n=1,2,…9
$# #传递给脚本或函数的参数个数
$* #传递给脚本或函数的所有参数:“$1,$2,……$9” 整体传递
$@ #传递给脚本或函数的所有参数:“$1”,“$2”,……“$9” 分开传递
$? #命令或程序执行完后的状态,返回0表示执行成功
$$ #当前脚本程序的PID号2.2.3 环境变量
在程序运行时需要设置。
实例:输出脚本当前执行位置
- #! /bin/bash
- path= `pwd`
- echo $path
实例效果截图:

环境变量总结
PATH #shell搜索路径,以冒号为分割
HOME #/etc/passwd文件中列出的用户主目录
SHELL #当前Shell类型
USER #当前用户名
ID #当前用户id信息
PWD #当前所在路径
TERM #当前终端类型
HOSTNAME #当前主机名;
PS1 #定义主机命令提示符
HISTSIZE #历史命令大小,可通过HISTTIMEFORMAT变量设置命令执行时间
RANDOM #随机生成一个0至32767的整数
HOSTNAME #主机名
温馨提示:变量名与等号之间是不允许存在空格,否则提示'Common not found 指定未找到错误'。
错误展示例:
- # 错误变量定义,变量与等号之间存在空格,弹出错误信息:为找到pwd 指令
- path = `pwd`
- echo "$path"
- # 正确变量定义, 变量与等号之间不存在空格。
- path=`pwd`
- echo "$path"
3、Shell 参数传递
Shell 参数传递主要分为两种:1、命令行式参数传递,2、getopts参数传递
3.1 命令行式参数传递
温馨提示:采用命令行式参数传递值得注意的是,$0获取到的是脚本路径以及脚本名,后面按顺序获取参数,当参数超过10个时(包括10个),需要使用${10},${11}....才能获取到参数,但是一般很少会超过10个参数的情况。
示例:创建命令行式参数传递Shell脚本,commond_param.sh
- #! /bin/bash
- echo "脚本$0"
- echo "第一个参数$1"
- echo "第二个参数$2"
未传参效果截图:

传参效果截图:传递两个参数,分别为110 和119

特殊字符参数整理
参数处理 说明 $# 传递到脚本的参数个数 $* 以一个单字符串显示所有向脚本传递的参数。
如"$*"用「"」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。$$ 脚本运行的当前进程ID号 $! 后台运行的最后一个进程的ID号 $@ 与$*相同,但是使用时加引号,并在引号中返回每个参数。
如"$@"用「"」括起来的情况、以"$1" "$2" … "$n" 的形式输出所有参数。$- 显示Shell使用的当前选项,与set命令功能相同。 $? 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 示例:创建特殊字符串Shell脚本,special_str.sh
- #! /bin/bash
- echo "Shell 传递参数实例!";
- echo "第一个参数为:$1";
- echo "参数个数为:$#";
- echo "传递的参数作为一个字符串显示:$*";
调用special_str脚本,并传递参数:110 119 120

知识点拓展: $* 与 $@ 区别
- 相同点:都是引用所有参数。
- 不同点:$* 接受多个参数使用空格进行连接,显示一个参数,$@接受多个参数转化为数组接受,$*和$@只有在双引号中体现出来。
示例:
- #! /bin/bash
- echo "-- \$* 演示 ---"
- for i in "$*"; do
- echo $i
- done
- echo "-- \$@ 演示 ---"
- for i in "$@"; do
- echo $i
- done
3.2 getopts参数传递
getopts 可以获取用户在命令下的参数,然后根据参数进行不同的提示或者不同的执行。
语法格式:getopts option_string variable
option_string 形式参数名称 variable 遍历形式参数变量名称
各个形式参数之间可以通过冒号 : 进行分隔,也可以直接相连接, : 表示选项后面必须带有形式参数的实际值,如果没有可以不加实际值进行传递。
示例:创建getopts 参数传递Shell脚本,getopts_sh.sh
- #! /bin/bash
- while getopts ":a:b:c:" opt
- do
- case $opt in
- a)
- echo "参数a的值$OPTARG"
- ;;
- b)
- echo "参数b的值$OPTARG"
- ;;
- c)
- echo "参数c的值$OPTARG"
- ;;
- ?)
- echo "未知参数"
- exit 1;;
- esac
- done
调用getopts_sh.sh 脚本,并传递参数

4、Shell 数组
Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小。
Bash Shell 数组用括号来表示,元素用"空格"符号分割开,语法格式如下:
array_name=(value1 value2 ... valuen)示例:创建数组实例化并遍历数组对象,array_sh.sh脚本
- #! /bin/bash
- # 数组实例化一
- one_array=(A B C D E)
- # 数组实例化二
- two_array[0]=1
- two_array[1]=2
- two_array[2]=3
- two_array[3]=4
- # 数组遍历
- echo "第一个元素为: ${one_array[0]}"
- echo "第二个元素为: ${one_array[1]}"
- echo "第三个元素为: ${one_array[2]}"
- echo "第四个元素为: ${one_array[3]}"
调用array_sh.sh 脚本

4.1 关联数组(等同于键值对Map)
Bash Shell支持关联数组,可以使用任意的字符串、或者整数作为下标来访问数组元素。
关联数组使用 declare 命令来声明,语法格式如下:
declare -A array_name温馨提示:
- -A 选项就是用于声明一个关联数组。
- 关联数组的键是唯一的。
示例:创建关联数组实例化并遍历关联数组对象,real_array_sh.sh脚本
- #! /bin/bash
- # 关联数组实例化方式一
- declare -A site=(["google"]="www.google.com" ["baidu"]="www.baidu.com" ["taobao"]="www.taobao.com")
- # 关联数组实例化方式二
- declare -A siteCopy
- siteCopy["google"]="www.google.com"
- siteCopy["baidu"]="www.baidu.com"
- siteCopy["taobao"]="www.taobao.com"
- # 通过关联数组键访问指定元素
- echo ${site["baidu"]}
- # 输出关联数组元素
- echo "关联数组元素: ${site[*]}"
- echo "Copy关联数组元素: ${site[@]}"
- # 输出关联数组元素的键值
- echo "关联数组键值: ${!site[*]}"
- echo "Copy 关联数组键值: ${!site[@]}"
- # 输出关联数组元素的大小
- echo "关联数组大小: ${#site[*]}"
- echo "关联数组大小: ${#site[@]}"
调用real_array_sh.sh 脚本

5、Shell 运算符
Bash Shell 支持的运算符如下:
- 算数运算符
- 关系运算符
- 布尔运算符
- 字符串运算符
- 文件测试运算符
5.1 算数运算符
Bash Shell 不支持数学运算【加、减、乘、除】,但是可以通过Bash Shell 命令实现,例如 awk 和 expr,expr 最常用。
示例:创建算术运算符脚本,arith_test.sh
- #! /bin/bash
- a=10
- b=20
- # 注意使用的是反引号 ` 而不是单引号 '
- # 表达式和运算符之间要有空格
- val=`expr $a + $b`
- echo "a + b : $val"
- val=`expr $a - $b`
- echo "a - b : $val"
- val=`expr $a \* $b`
- echo "a * b : $val"
- val=`expr $b / $a`
- echo "b / a : $val"
- val=`expr $b % $a`
- echo "b % a : $val"
- # 条件表达式要放在方括号之间,并且要有空格,例如: [$a==$b] 是错误的,必须写成 [ $a == $b ]
- if [ $a == $b ]
- then
- echo "a 等于 b"
- fi
- if [ $a != $b ]
- then
- echo "a 不等于 b"
- fi
调用arith_test.sh脚本

5.1.1 算术运算符总结
算符 说明 举例 + 加法 `expr $a + $b` 结果为 30。 - 减法 `expr $a - $b` 结果为 -10。 * 乘法 `expr $a \* $b` 结果为 200。 / 除法 `expr $b / $a` 结果为 2。 % 取余 `expr $b % $a` 结果为 0。 = 赋值 a=$b 把变量 b 的值赋给 a。 == 相等。用于比较两个数字,相同则返回 true。 [ $a == $b ] 返回 false。 != 不相等。用于比较两个数字,不相同则返回 true。 [ $a != $b ] 返回 true。 5.2 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
示例:创建关系运算符脚本,real_test.sh
- #!/bin/bash
- a=10
- b=20
- if [ $a -eq $b ]
- then
- echo "$a -eq $b : a 等于 b"
- else
- echo "$a -eq $b: a 不等于 b"
- fi
- if [ $a -ne $b ]
- then
- echo "$a -ne $b: a 不等于 b"
- else
- echo "$a -ne $b : a 等于 b"
- fi
- if [ $a -gt $b ]
- then
- echo "$a -gt $b: a 大于 b"
- else
- echo "$a -gt $b: a 不大于 b"
- fi
- if [ $a -lt $b ]
- then
- echo "$a -lt $b: a 小于 b"
- else
- echo "$a -lt $b: a 不小于 b"
- fi
- if [ $a -ge $b ]
- then
- echo "$a -ge $b: a 大于或等于 b"
- else
- echo "$a -ge $b: a 小于 b"
- fi
- if [ $a -le $b ]
- then
- echo "$a -le $b: a 小于或等于 b"
- else
- echo "$a -le $b: a 大于 b"
- fi
调用real_test.sh 脚本
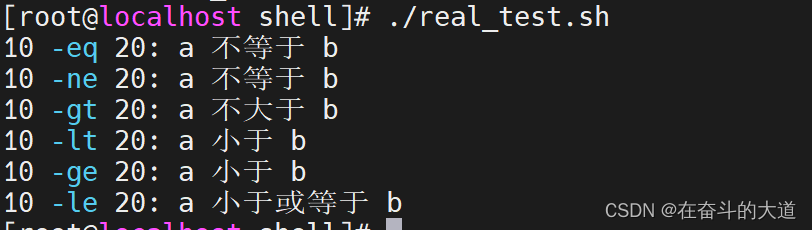
5.2.1 关系运算符总结
运算符 说明 举例 -eq 检测两个数是否相等,相等返回 true。 [ $a -eq $b ] 返回 false。 -ne 检测两个数是否不相等,不相等返回 true。 [ $a -ne $b ] 返回 true。 -gt 检测左边的数是否大于右边的,如果是,则返回 true。 [ $a -gt $b ] 返回 false。 -lt 检测左边的数是否小于右边的,如果是,则返回 true。 [ $a -lt $b ] 返回 true。 -ge 检测左边的数是否大于等于右边的,如果是,则返回 true。 [ $a -ge $b ] 返回 false。 -le 检测左边的数是否小于等于右边的,如果是,则返回 true。 [ $a -le $b ] 返回 true。 5.3 布尔运算符
布尔运算符总结
运算符 说明 举例 ! 非运算,表达式为 true 则返回 false,否则返回 true。 [ ! false ] 返回 true。 -o 或运算,有一个表达式为 true 则返回 true。 [ $a -lt 20 -o $b -gt 100 ] 返回 true。 -a 与运算,两个表达式都为 true 才返回 true。 [ $a -lt 20 -a $b -gt 100 ] 返回 false。 示例:创建布尔运算符脚本
- #!/bin/bash
- a=10
- b=20
- if [ $a != $b ]
- then
- echo "$a != $b : a 不等于 b"
- else
- echo "$a == $b: a 等于 b"
- fi
- if [ $a -lt 100 -a $b -gt 15 ]
- then
- echo "$a 小于 100 且 $b 大于 15 : 返回 true"
- else
- echo "$a 小于 100 且 $b 大于 15 : 返回 false"
- fi
- if [ $a -lt 100 -o $b -gt 100 ]
- then
- echo "$a 小于 100 或 $b 大于 100 : 返回 true"
- else
- echo "$a 小于 100 或 $b 大于 100 : 返回 false"
- fi
- if [ $a -lt 5 -o $b -gt 100 ]
- then
- echo "$a 小于 5 或 $b 大于 100 : 返回 true"
- else
- echo "$a 小于 5 或 $b 大于 100 : 返回 false"
- fi
调用上传脚本,结果输出
- 10 != 20 : a 不等于 b
- 10 小于 100 且 20 大于 15 : 返回 true
- 10 小于 100 或 20 大于 100 : 返回 true
- 10 小于 5 或 20 大于 100 : 返回 false
5.4 逻辑运算符
运算符 说明 举例 && 逻辑的 AND [[ $a -lt 100 && $b -gt 100 ]] 返回 false || 逻辑的 OR [[ $a -lt 100 || $b -gt 100 ]] 返回 true 示例:创建逻辑运算符脚本
- #!/bin/bash
- a=10
- b=20
- if [[ $a -lt 100 && $b -gt 100 ]]
- then
- echo "返回 true"
- else
- echo "返回 false"
- fi
- if [[ $a -lt 100 || $b -gt 100 ]]
- then
- echo "返回 true"
- else
- echo "返回 false"
- fi
调用上传脚本,结果输出
- 返回 false
- 返回 true
5.5 字符串运算符
运算符 说明 举例 = 检测两个字符串是否相等,相等返回 true。 [ $a = $b ] 返回 false。 != 检测两个字符串是否不相等,不相等返回 true。 [ $a != $b ] 返回 true。 -z 检测字符串长度是否为0,为0返回 true。 [ -z $a ] 返回 false。 -n 检测字符串长度是否不为 0,不为 0 返回 true。 [ -n "$a" ] 返回 true。 $ 检测字符串是否不为空,不为空返回 true。 [ $a ] 返回 true。 示例:创建字符串运算符脚本
- #!/bin/bash
- a="abc"
- b="efg"
- if [ $a = $b ]
- then
- echo "$a = $b : a 等于 b"
- else
- echo "$a = $b: a 不等于 b"
- fi
- if [ $a != $b ]
- then
- echo "$a != $b : a 不等于 b"
- else
- echo "$a != $b: a 等于 b"
- fi
- if [ -z $a ]
- then
- echo "-z $a : 字符串长度为 0"
- else
- echo "-z $a : 字符串长度不为 0"
- fi
- if [ -n "$a" ]
- then
- echo "-n $a : 字符串长度不为 0"
- else
- echo "-n $a : 字符串长度为 0"
- fi
- if [ $a ]
- then
- echo "$a : 字符串不为空"
- else
- echo "$a : 字符串为空"
- fi
调用上传脚本,结果输出
- abc = efg: a 不等于 b
- abc != efg : a 不等于 b
- -z abc : 字符串长度不为 0
- -n abc : 字符串长度不为 0
- abc : 字符串不为空
5.6 文件测试运算符
文件测试运算符用于检测 Unix 文件的各种属性。
操作符 说明 举例 -b file 检测文件是否是块设备文件,如果是,则返回 true。 [ -b $file ] 返回 false。 -c file 检测文件是否是字符设备文件,如果是,则返回 true。 [ -c $file ] 返回 false。 -d file 检测文件是否是目录,如果是,则返回 true。 [ -d $file ] 返回 false。 -f file 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 [ -f $file ] 返回 true。 -g file 检测文件是否设置了 SGID 位,如果是,则返回 true。 [ -g $file ] 返回 false。 -k file 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 [ -k $file ] 返回 false。 -p file 检测文件是否是有名管道,如果是,则返回 true。 [ -p $file ] 返回 false。 -u file 检测文件是否设置了 SUID 位,如果是,则返回 true。 [ -u $file ] 返回 false。 -r file 检测文件是否可读,如果是,则返回 true。 [ -r $file ] 返回 true。 -w file 检测文件是否可写,如果是,则返回 true。 [ -w $file ] 返回 true。 -x file 检测文件是否可执行,如果是,则返回 true。 [ -x $file ] 返回 true。 -s file 检测文件是否为空(文件大小是否大于0),不为空返回 true。 [ -s $file ] 返回 true。 -e file 检测文件(包括目录)是否存在,如果是,则返回 true。 [ -e $file ] 返回 true。 其他检查符:
- -S: 判断某文件是否 socket。
- -L: 检测文件是否存在并且是一个符号链接。
示例:创建文件测试运算符脚本
- #!/bin/bash
- file="/home/shell/test.sh"
- if [ -r $file ]
- then
- echo "文件可读"
- else
- echo "文件不可读"
- fi
- if [ -w $file ]
- then
- echo "文件可写"
- else
- echo "文件不可写"
- fi
- if [ -x $file ]
- then
- echo "文件可执行"
- else
- echo "文件不可执行"
- fi
- if [ -f $file ]
- then
- echo "文件为普通文件"
- else
- echo "文件为特殊文件"
- fi
- if [ -d $file ]
- then
- echo "文件是个目录"
- else
- echo "文件不是个目录"
- fi
- if [ -s $file ]
- then
- echo "文件不为空"
- else
- echo "文件为空"
- fi
- if [ -e $file ]
- then
- echo "文件存在"
- else
- echo "文件不存在"
- fi
调用上传脚本,结果输出
- 文件可读
- 文件可写
- 文件可执行
- 文件为普通文件
- 文件不是个目录
- 文件不为空
- 文件存在
6、Shell 流程控制
6.1 条件语句
语法格式:
- if [condition1]; then
- ...
- elif [condition2]; then
- ...
- else
- ...
- fi
示例: 查询当前docker 实例数,如果大于0,返回docker 实例数数量,否则什么也不返回。
- #! /bin/bash
- if [ $(ps -ef | grep -c "ssh") -gt 1 ]
- then
- echo "docker 当前实例化数量:$(ps -ef | grep -c 'ssh')"
- else
- echo "docker 当前实例化数量为0"
- fi
调用docker_if.sh 脚本

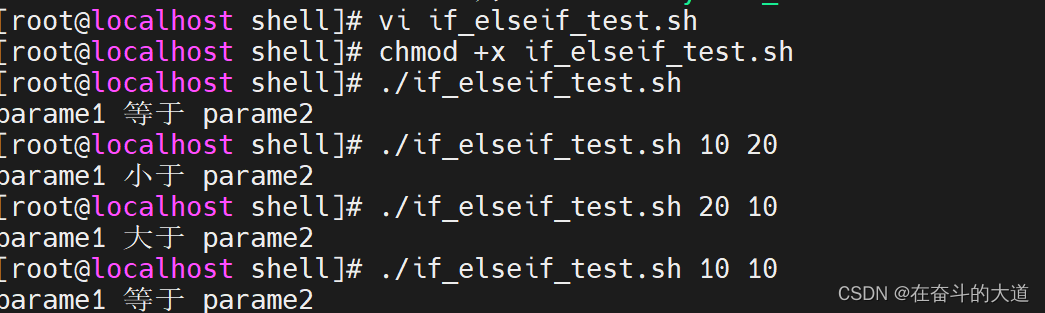
示例: 传入两个整数类型变量,比较两个变量的大小
- #! /bin/bash
- parame1=$1
- parame2=$2
- if [ $parame1 == $parame2 ]
- then
- echo "parame1 等于 parame2"
- elif [ $parame1 -gt $parame2 ]
- then
- echo "parame1 大于 parame2"
- elif [ $parame1 -lt $parame2 ]
- then
- echo "parame1 小于 parame2"
- else
- echo "没有符合的条件"
- fi
调用if_elseif_test.sh脚本
温馨提示:
- 大于小于判断可以使用 -gt\-lt,也可以使用 >\<
- 语句条件可以使用[...],也可以使用((...))
6.2 多路分支语句
语法格式:
- case $variable in
- "case1")
- .......
- ;;
- "case2")
- .......
- ;;
- "case3")
- ......
- ;;
- *)
- ......
- ;;
- esac
示例: 输入1-5任意数字,Base Shell 输出相关数字
- #! /bin/bash
- echo '输入 1 到 4 之间的数字:'
- echo '你输入的数字为:'
- read aNum
- case $aNum in
- 1) echo '你选择了 1'
- ;;
- 2) echo '你选择了 2'
- ;;
- 3) echo '你选择了 3'
- ;;
- 4) echo '你选择了 4'
- ;;
- *) echo '你没有输入 1 到 4 之间的数字'
- ;;
- esac
执行input_num.sh 脚本

6.3 循环语句
语法格式一:
- for var in con1 con2 con3 ...
- do
- ......
- done
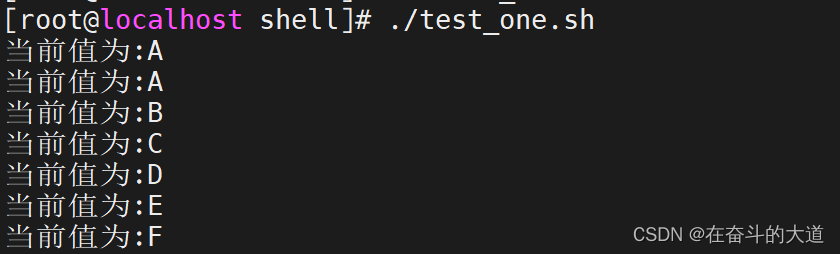
示例: 遍历数组对象
- #! /bin/bash
- one_array=(A B C D E F)
- for loop in $one_array
- do
- echo "当前值为:$loop"
- done
- for var in A B C D E F
- do
- echo "当前值为:$var"
- done
调用test_one.sh 脚本
语法格式二:
- while [condition]
- do
- ......
- done
示例:如果 int 小于等于 5,那么条件返回真。int 从 1 开始,每次循环处理时,int 加 1。
- #! /bin/bash
- int=1
- while(( $int<=5 ))
- do
- echo $int
- let "int++"
- done
调用test_two.sh 脚本

6.4 循环控制语句
- break #终止执行所有循环
- continue #终止该次循环,进行下次循环
示例:break 使用
- #!/bin/bash
- while :
- do
- echo -n "输入 1 到 5 之间的数字:"
- read aNum
- case $aNum in
- 1|2|3|4|5) echo "你输入的数字为 $aNum!"
- ;;
- *) echo "你输入的数字不是 1 到 5 之间的! 游戏结束"
- break
- ;;
- esac
- done
示例:continue 使用
- #!/bin/bash
- while :
- do
- echo -n "输入 1 到 5 之间的数字: "
- read aNum
- case $aNum in
- 1|2|3|4|5) echo "你输入的数字为 $aNum!"
- ;;
- *) echo "你输入的数字不是 1 到 5 之间的!"
- continue
- echo "游戏结束"
- ;;
- esac
- done
7、Shell 函数
Base Shell可以用户定义函数,然后在shell脚本中可以随便调用。
语法格式:
- [ function ] funname [()]
- {
- action;
- [return int;]
- }
温馨提示:
- 可以带function fun() 定义,也可以直接fun() 定义,不带任何参数。
- 参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。
示例:调用Shell脚本,输出www.baidu.com
- #! /bin/bash
- #定义函数
- function url {
- echo "www.baidu.com"
- }
- #调用函数
- url
效果截图:

示例:调用Shell脚本,输出参数值之和
- #! /bin/bash
- #定义函数:获取参数的和
- function get_sum() {
- # 变量只在函数内生效。属于局部变量
- local sum=0
- for n in $@
- do
- ((sum+=n))
- done
- return $sum
- }
- #调用函数并传递参数
- get_sum 10 2 5 7 9 12 50
- echo $?
效果截图:
 特殊字符参数处理:
特殊字符参数处理:参数处理 说明 $# 传递到脚本或函数的参数个数 $* 以一个单字符串显示所有向脚本传递的参数 $$ 脚本运行的当前进程ID号 $! 后台运行的最后一个进程的ID号 $@ 与$*相同,但是使用时加引号,并在引号中返回每个参数。 $- 显示Shell使用的当前选项,与set命令功能相同。 $? 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 取消函数 :unset 自定义函数名称 #取消函数
8、Shell test
test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
数值测试
参数 说明 -eq 等于则为真 -ne 不等于则为真 -gt 大于则为真 -ge 大于等于则为真 -lt 小于则为真 -le 小于等于则为真 示例:比较两个参数大小
- #! /bin/bash
- num1=$1
- num2=$2
- if test $[num1] -eq $[num2]
- then
- echo '两个数相等!'
- else
- echo '两个数不相等!'
- fi
- [ro
效果截图:

字符串测试
参数 说明 = 等于则为真 != 不相等则为真 -z 字符串 字符串的长度为零则为真 -n 字符串 字符串的长度不为零则为真 示例:比较两个字符串是否相等
- #! /bin/bash
- num1=$1
- num2=$2
- if test $num1 = $num2
- then
- echo '两个字符串相等!'
- else
- echo '两个字符串不相等!'
- fi
效果截图:

文件测试
参数 说明 -e 文件名 如果文件存在则为真 -r 文件名 如果文件存在且可读则为真 -w 文件名 如果文件存在且可写则为真 -x 文件名 如果文件存在且可执行则为真 -s 文件名 如果文件存在且至少有一个字符则为真 -d 文件名 如果文件存在且为目录则为真 -f 文件名 如果文件存在且为普通文件则为真 -c 文件名 如果文件存在且为字符型特殊文件则为真 -b 文件名 如果文件存在且为块特殊文件则为真 示例:判断指定文件夹是否存在
- #! /bin/bash
- cd /home
- if test -e ./shell
- then
- echo '文件已存在!'
- else
- echo '文件不存在!'
- fi
效果截图:

9、Shell 正则表达式
正则表达式(regular expression, RE)是一种字符模式,用于在查找过程中匹配指定的字符。
正则表达式分为:
- 正则表达式基本元字符
- 正则表达式拓展元字符
正则表达式基本元字符
- 基本正则表达式元字符
- 元字符
- 示例 功能 示例
- ^ 行首定位符 ^love
- $ 行尾定位符 love$
- . 匹配单个字符 l..e
- * 匹配前导符0到多次 ab*love
- .* 匹配任意多个字符(贪婪匹配)
- [] 匹配方括号中任意一个字符 [lL]ove
- [ - ] 匹配指定范围内的一个字符 [a-z0-9]ove
- [^] 匹配不在指定组里的字符 [^a-z0-9]ove
- \ 用来转义元字符 love\.
- \< 词首定位符 \<love
- \> 词尾定位符 love\>
- \(\) 匹配后的标签
正则表达式拓展元字符
- 扩展正则表达式元字符 功能 示例
- + 匹配一次或多次前导字符 [a-z]+ove
- ? 匹配零次或一次前导字符 lo?ve
- a|b 匹配a或b love|hate
- x{m} 字符x重复m次 o{5}
- x{m,} 字符x重复至少m次 o{5,}
- x{m,n} 字符x重复m到n次 o{5,10}
- () 字符组 ov+ (ov)+
示例:数字正则表达式判断
- #! /bin/bash
- num1=123
- # 正则判断, 需要使用[[]]
- [[ $num1 =~ ^[0-9]+$ ]] && echo "yes" || echo "no"
- num2=1L1
- [[ $num2 =~ ^[0-9]+$ ]] && echo "yes" || echo "no"
- num3=191
- [[ $num3 =~ ^[0-9]\.[0-9]+$ || $num3 =~ ^[0-9]+$ ]] && echo "yes" || echo "no"
效果截图:

10、Shell grep
grep命令是Globally search a Regular Expression and Print的缩写,表示进行全局的正则匹配并进行打印。
grep使用
- [root@localhost ~]# grep '^#' /etc/ssh/ssh_config #过滤以#号开头的行
- [root@localhost ~]# grep -v '^#' /etc/ssh/ssh_config #-v:取反,表示反向查找
- [root@localhost ~]# grep 'sendenv' /etc/ssh/ssh_config
- [root@localhost ~]# grep -i 'sendenv' /etc/ssh/ssh_config #-i忽略大小写
- [root@localhost ~]# grep 'bash' /opt/test/ #过滤某个目录下面带有bash的行
- [root@localhost ~]# grep -r 'bash' /opt/test/ #-[r|R]表示递归查询
grep正则过滤
- #grep基本正则匹配
- ^以什么开头
- [root@linux-server ~]# grep '^root' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- $以什么结尾
- [root@linux-server ~]# grep 'bash$' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- confluence:x:1000:1000:Atlassian Confluence:/home/confluence:/bin/bash
- to:x:1003:1003::/home/to:/bin/bash
- . 匹配单个字符
- [root@linux-server ~]# grep 'r..t' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- operator:x:11:0:operator:/root:/sbin/nologin
- ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
- dockerroot:x:998:995:Docker User:/var/lib/docker:/sbin/nologin
- [root@linux-server ~]# grep 'r.t' /etc/passwd
- operator:x:11:0:operator:/root:/sbin/nologin
- sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
- .* 任意多个字符(可以为0个字符)
- [root@linux-server ~]# grep 'r.*t' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- operator:x:11:0:operator:/root:/sbin/nologin
- ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
- systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin polkitd:x:999:997:User for polkitd:/:/sbin/nologin postfix:x:89:89::/var/spool/postfix:/sbin/nologin
- sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin dockerroot:x:998:995:Docker User:/var/lib/docker:/sbin/nologin
- tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
- apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
- abrt:x:1041:1041::/home/abrt:/bin/bash
- [] 匹配方括号中的任意一个字符
- [root@linux-server ~]# useradd Root
- [root@linux-server ~]# grep 'Root' /etc/passwd
- [root@linux-server ~]# grep '[Rr]oot' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- operator:x:11:0:operator:/root:/sbin/nologin
- Root:x:1000:1000::/home/Root:/bin/bash
- [ - ] 匹配指定范围内的一个字符
- [root@linux-server ~]# grep [a-z]oot /etc/passwd #a-z
- root:x:0:0:root:/root:/bin/bash
- operator:x:11:0:operator:/root:/sbin/nologin
- dockerroot:x:998:995:Docker User:/var/lib/docker:/sbin/nologin
- [^] 匹配不在指定组内的字符,非得意思
- [root@linux-server ~]# grep '[^0-9]' /etc/passwd
- [root@linux-server ~]# grep '[^0-9A-Z]oot' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- operator:x:11:0:operator:/root:/sbin/nologin
- dockerroot:x:998:995:Docker User:/var/lib/docker:/sbin/nologin
- #注意:^在[]内表示取反,^在[]外表示以什么开头
grep正则升级版本egrep
- #扩展正则匹配---egrep
- 扩展正则表达式元字符 功能 示例
- + 匹配一次或多次前导字符 [a-z]+ove
- ? 匹配零次或一次前导字符 lo?ve
- a|b 匹配a或b love|hate
- x{m} 字符x重复m次 o{5}
- x{m,} 字符x重复至少m次 o{5,}
- x{m,n} 字符x重复m到n次 o{5,10}
- () 字符组 ov+ (ov)+
- egrep 支持正则表达式的拓展元字符
- [root@linux-server ~]# egrep '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' /etc/resolv.conf
- nameserver 192.168.246.2
- + 匹配一个或多个前导字符
- [root@linux-server ~]# egrep 'ro+t' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- operator:x:11:0:operator:/root:/sbin/nologin
- dockerroot:x:998:995:Docker User:/var/lib/docker:/sbin/nologin
- a|b 匹配a或b
- [root@linux-server ~]# netstat -anlp|egrep ':80|:22'
- [root@linux-server ~]# egrep 'root|jack' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- operator:x:11:0:operator:/root:/sbin/nologin
- jack1:x:1001:1001::/home/jack1:/bin/bash
- jack2:x:1002:1002::/home/jack2:/bin/bash
- x{m} 字符x重复m次
- [root@linux-server ~]# cat a.txt
- love
- love.
- loove
- looooove
- [root@linux-server ~]# egrep 'o{2}' a.txt
- loove
- looooove
- [root@linux-server ~]# egrep 'o{2,}' a.txt
- loove
- looooove
- [root@linux-server ~]# egrep 'o{6,7}' a.txt
11、Shell sed
sed:stream editor(流编辑器)的缩写是一种在线非交互式编辑器,它一次处理一行内容。这样不断重复,直到文件末尾。
sed用途:自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
sed 支持的正则表达式:
- 使用基本元字符集 ^, $, ., *, [], [^], \< \>,
- 使用扩展元字符集 ?, +, { }, |, ( )
11.1 Sed 用法之打印
sed 默认会输出文件的每一行,无论这行内容是否能匹配上匹配内容。
语法格式:sed -r '匹配内容' 目标文件地址
11.2 Sed 用法之搜索替换
sed 默认打印目标文件每一行内容,并同时查找匹配内容的行记录,执行后续指令。默认是
p打印(-n不打印)示例:
- 示例文件
- [root@localhost ~]# vim test.txt
- MA Daggett, 341 King Road, Plymouth MA
- Alice Ford, 22 East Broadway, Richmond VA
- MA Thomas, 11345 Oak Bridge Road, Tulsa OK
- Terry Kalkas, 402 Ma Road, mA Falls PA
- Eric Adams, 20 Post Road, Sudbury mA
- Hubert Sims, 328A Brook Road, Roanoke VA
- Amy Wilde, 334 Ma Pkwy, Mountain View CA
- Sal Carpenter, 73 MA Street, Boston MA
- 1.搜索每一行匹配到MA的将第一个替换为Massachusetts:
- [root@localhost ~]# sed -r 's/MA/Massachusetts/' test.txt
- s:----查找
- 2.搜索每一行,找到所有的MA字符,进行全局替换为Massachusetts
- [root@localhost ~]# sed -r 's/MA/Massachusetts/g' test.txt
- 3.搜索每一行,找到所有的MA字符,进行全局替换为Massachusetts同时忽略大小写
- [root@localhost ~]# sed -r 's/MA/Massachusetts/gi' test.txt
- -i:忽略大小写
- 4.-n #静默输出(不打印默认输出)
- [root@localhost ~]# sed -r -n 's/MA/Massachusetts/' test.txt
- 案例:
- [root@localhost ~]# sed -r 's/SELINUX=disabled/SELINUX=enabled/' /etc/sysconfig/selinux
- (尽量用/etc/selinux/config中修改)
11.3 Sed 用法之多重编辑选型
示例:
- 1.使用多重指令:-e 给予sed多个命令的时候需要-e选项
- [root@localhost ~]# sed -r -e 's/MA/Massachusetts/' -e 's/PA/Pennsylvania/' test.txt
- 2.使用脚本文件:当有多个要编辑的项目时,可以将编辑命令放进一个脚本里,再使用sed搭配-f选项
- -f <script文件> 以选项中指定的script文件来处理输入的文本文件。
- [root@localhost ~]# vim s.sed
- s/MA/Massachusetts/
- s/PA/Pennsylvania/
- s/CA/California/
- s/VA/Virginia/
- s/OK/Oklahoma/
- [root@localhost ~]# sed -f s.sed test.txt
- 保存输出:
- [root@localhost ~]# sed -f s.sed test.txt > newfile.txt
11.4 Sed 用法之地址
地址用于决定对哪些
行进行编辑。地址形式可以是数字、正则表达式或二者的结合。如果没有指定地址,sed将处理输入文件中的所有行。- [root@localhost ~]# head /etc/passwd > passwd #生成测试文件
- [root@localhost ~]# sed -r '1d' passwd #d:表示删除-- 删除文件的第1行
- bin:x:1:1:bin:/bin:/sbin/nologin
- daemon:x:2:2:daemon:/sbin:/sbin/nologin
- [root@localhost ~]# sed -r '1,2d' passwd #删除文件的第1-2行 daemon:x:2:2:daemon:/sbin:/sbin/nologin
- [root@localhost ~]# cat passwd
- root:x:0:0:root:/root:/bin/bash
- bin:x:1:1:bin:/bin:/sbin/nologin
- daemon:x:2:2:daemon:/sbin:/sbin/nologin
- ...
- [root@localhost ~]# sed -r '2,$d' passwd #删除第2行到最后一行
- root:x:0:0:root:/root:/bin/bash
- [root@localhost ~]# sed -r '/^root/d' passwd #匹配到root开头的行,删除此行
- bin:x:1:1:bin:/bin:/sbin/nologin
- daemon:x:2:2:daemon:/sbin:/sbin/nologin
- [root@localhost ~]# sed -r '/root/d' passwd #含有root的行都删除
- bin:x:1:1:bin:/bin:/sbin/nologin
- daemon:x:2:2:daemon:/sbin:/sbin/nologin
- [root@localhost ~]# sed -r '/bash/,3d' passwd #匹配到bash行,从此行到第3行删除
- adm:x:3:4:adm:/var/adm:/sbin/nologin
- [root@localhost ~]# cat -n passwd
- 1 root:x:0:0:root:/root:/bin/bash
- 2 bin:x:1:1:bin:/bin:/sbin/nologin
- 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
- 4 adm:x:3:4:adm:/var/adm:/sbin/nologin
- 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
- 6 sync:x:5:0:sync:/sbin:/bin/sync
- 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
- 8 halt:x:7:0:halt:/sbin:/sbin/halt
- 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
- 10 operator:x:11:0:operator:/root:/sbin/nologin
- [root@localhost ~]# sed -r '1~2d' passwd #删除奇数行,间隔两行删除
- bin:x:1:1:bin:/bin:/sbin/nologin
- adm:x:3:4:adm:/var/adm:/sbin/nologin
- sync:x:5:0:sync:/sbin:/bin/sync
- halt:x:7:0:halt:/sbin:/sbin/halt
- operator:x:11:0:operator:/root:/sbin/nologin
- [root@localhost ~]# sed '0~2d' passwd #删除偶数行,从0开始间隔2行删除
- passwd root:x:0:0:root:/root:/bin/bash
- daemon:x:2:2:daemon:/sbin:/sbin/nologin
- lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
11.5、sed命令用法及解析
- 1.插入命令--i
- [root@localhost ~]# sed -r '2i\222222' passwd #在第2行插入
- 2.修改命令---c
- [root@localhost ~]# sed -r '4c\asfasdf' passwd
- 案例:
- [root@localhost ~]# sed -r '7c\SELINUX=enabled' /etc/sysconfig/selinux
- 3.选项 -i 会使得sed用修改后的数据替换原文件
- [root@localhost ~]# sed -r -i '7c\SELINUX=enabled' /etc/sysconfig/selinux #修改
- [root@localhost ~]# sed -r -i 's/SELINUX=enabled/SELINUX=disabled/' /etc/sysconfig/selinux #替换
- 4.由于在使用 -i 参数时比较危险, 所以我们在使用i参数时在后面加上.bak就会产生一个备份的文件,以防后悔
- [root@localhost ~]# sed -r -i.bak 's/root/ROOT/' passwd
sed常见操作
- [root@localhost ~]# cp /etc/ssh/ssh_config .
- 1.删除配置文件中 # 号注释的行
- [root@localhost ~]# sed -ri '/^#/d' ssh_config
- 2.给文件行添加注释:
- [root@localhost ~]# sed -r '2,5s/^/#/' passwd
- 给所有行添加注释:
- [root@localhost ~]# sed -r 's/^/#/' passwd
- 3.给文件行添加和取消注释
- [root@localhost ~]# sed -ri s/^#baseurl/baseurl/g /etc/yum.repos.d/CentOS-Base.repo
- [root@localhost ~]# sed -r s/^mirrorlist/#mirrorlist/g /etc/yum.repos.d/CentOS-Base.repo
12、Shell awk
awk 简介
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自一个或多个文件,或其它命令的输出。可以在命令行中使用,但更多是作为脚本来使用。
awk的处理文本和数据的方式是这样的,它逐行扫描文件,从第一行到最后一行,寻找匹配的特定模式的行,并在这些行上进行操作。如果没有指定模式,则所有被操作所指定的行都被处理。
awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是Alfred Aho、Brian Kernighan、Peter Weinberger。
awk处理过程: 依次对每一行进行处理,然后输出,默认分隔符是空格或者tab键awk 语法格式
- awk [options] 'commands' filenames
- options:
- -F 对于每次处理的内容,可以指定一个自定义的输入字段分隔符,默认的分隔符是空白字符(空格或 tab 键 )
- commands:
- BEGIN{} {} END{} filename
- 行处理前的动作 行内容处理的动作 行处理之后的动作 文件名
- BEGIN{}和END{} 是可选项。
- 函数-BEGIN{}:读入文本之前要操作的命令。
- {}:主输入循环:用的最多。读入文件之后擦操作的命令。如果不读入文件都可以不用写。
- END{}:文本全部读入完成之后执行的命令。
示例:
awk -F":" '{print $1,$3}' /etc/passwd功能含义:读取/etc/passwd 文本内容,使用':'分号实现对/etc/passwd 文本内容的分隔,分隔的文本内容输出第一个和第三个字符。
示例:
- [root@localhost ~]# awk 'BEGIN{ print 1/2} {print "ok"} END{print "----"}' /etc/hosts
- 0.5
- ok
- ok
- ----
awk 记录与字段相关内部变量:
- 1.记录和字段
- awk 按记录处理:一行是一条记录,因为awk默认以换行符分开的字符串是一条记录。(默认\n换行符:记录分隔符)
- 字段:以字段分割符分割的字符串 默认是单个或多个“ ” tab键。
- 2.awk中的变量
- $0:表示整行;
- NF : 统计字段的个数
- $NF:是number finally,表示最后一列的信息
- RS:输入记录分隔符;
- ORS:输出记录分隔符。
- NR:打印记录号,(行号)
- FNR:可以分开,按不同的文件打印行号。
- FS : 输入字段分隔符,默认为一个空格。
- OFS 输出的字段分隔符,默认为一个空格。
- FILENAME 文件名 被处理的文件名称
- $1 第一个字段,$2第二个字段,依次类推...
示例:
- FS(输入字段分隔符)---一般简写为-F(属于行处理前)
- [root@awk ~]# cat /etc/passwd | awk 'BEGIN{FS=":"} {print $1,$2}'
- root x
- bin x
- daemon x
- adm x
- lp x
- sync x
- shutdown x
- halt x
- mail x
- [root@awk ~]# cat /etc/passwd | awk -F":" '{print $1,$2}'
- root x
- bin x
- daemon x
- adm x
- lp x
- sync x
- shutdown x
- halt x
- mail x
- #注:如果-F不加默认为空格区分!
- ===============================================================
- OFS(输出字段分隔符)
- [root@awk ~]# cat /etc/passwd | awk 'BEGIN{FS=":";OFS=".."} {print $1,$2}'
- root..x
- bin..x
- daemon..x
- adm..x
- lp..x
- sync..x
- shutdown..x
- halt..x
- mail..x
- ======================================================================
- 1.创建两个文件
- [root@awk ~]# vim a.txt
- love
- love.
- loove
- looooove
- [root@awk ~]# vim file1.txt
- isuo
- IPADDR=192.168.246.211
- hjahj123
- GATEWAY=192.168.246.1
- NETMASK=255.255.255.0
- DNS=114.114.114.114
- NR 表示记录编号, 在awk将行做为记录, 该变量相当于当前行号,也就是记录号
- [root@awk ~]# awk '{print NR,$0}' a.txt file1.txt
- 1 love
- 2 love.
- 3 loove
- 4 looooove
- 5
- 6 isuo
- 7 IPADDR=192.168.246.211
- 8 hjahj123
- 9 GATEWAY=192.168.246.1
- 10 NETMASK=255.255.255.0
- 11 DNS=114.114.114.114
- FNR:表示记录编号, 在awk将行做为记录, 该变量相当于当前行号,也就是记录号(#会将不同文件分开)
- [root@awk ~]# awk '{print FNR,$0}' a.txt file1.txt
- 1 love
- 2 love.
- 3 loove
- 4 looooove
- 5
- 1 isuo
- 2 IPADDR=192.168.246.211
- 3 hjahj123
- 4 GATEWAY=192.168.246.1
- 5 NETMASK=255.255.255.0
- 6 DNS=114.114.114.114
- ===========================================================
- RS(输入记录分隔符)
- 1.创建一个文件
- [root@awk ~]# vim passwd
- root:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologin
- [root@awk ~]# cat passwd | awk 'BEGIN{RS="bash"} {print $0}'
- root:x:0:0:root:/root:/bin/
- bin:x:1:1:bin:/bin:/sbin/nologin
- ORS(输出记录分隔符)
- 2.对刚才的文件进行修改
- [root@awk ~]# vim passwd
- root:x:0:0:root:/root:/bin/bash
- bin:x:1:1:bin:/bin:/sbin/nologin
- [root@awk ~]# cat passwd | awk 'BEGIN{ORS=" "} {print $0}'
- root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin
- ===========================================================
- NF:统计字段的个数
- [root@awk ~]# cat /etc/passwd | awk -F":" '{print NF}'
- 7
- 7
- 7
- 7
- $NF:打印最后一列
- [root@awk ~]# cat /etc/passwd | awk -F":" '{print $NF}'
- /bin/bash
- /sbin/nologin
- /sbin/nologin
- /sbin/nologin
- /sbin/nologin
awk 关系运算符
字符串的完全相等需要使用
==。字符串需要使用双引号
!=表示不等于示例:
- [root@awk ~]# awk -F":" '$NF == "/bin/bash"' /etc/passwd
- [root@awk ~]# awk -F":" '$1 != "root"' /etc/passwd
awk 比较表达式
- 比较表达式采用对文本进行比较,只有当条件为真,才执行指定的动作。
- 比较表达式使用关系运算符,用于比较数字与字符串。
- 关系运算符有
- < 小于 例如 x<y
- > 大于 x>y
- <= 小于或等于 x<=y
- == 等于 x==y
- != 不等于 x!=y
- >= 大于等于 x>=y
示例:
- [root@awk ~]# awk -F":" '$3 == 0' /etc/passwd
- [root@awk ~]# awk -F":" '$3 < 10' /etc/passwd
awk 算术运算
支持表达式:
+,-,*,/,%(模: 取余),^(幂:2^3)示例:awk -F: '$3 * 10 > 500' /etc/passwdawk 常见使用总结
1.打印一个文件中的第2列和第5列
# cat /etc/passwd | awk -F : '{print $2,$5}'2.打印指定行指定列的某个字符
# free -m | awk 'NR==2 {print $2}'3.统计一个文件的行数
# cat /etc/passwd | awk '{print NR}'获取根分区的使用量
4.在awk中使用if条件判断
- i++===先赋值在运算
- ++i===先运算在赋值
- if语句:
- {if(表达式){语句;语句;...}}
- 实战案例:
- 显示管理员用户姓名
- [root@qfedu ~]# cat /etc/passwd | awk -F":" '{if($3==0) {print $1 " is administrator"}}'
- 统计系统用户数量
- [root@qfedu ~]# cat /etc/passwd | awk -F":" '{if($3>=0 && $3<=1000){i++}} END{print i}'
5.在awk中使用for循环
- 每行打印两遍
- [root@qfedu ~]# awk '{for(i=1;i<=2;i++) {print $0}}' /etc/passwd
- root:x:0:0:root:/root:/bin/bash
- root:x:0:0:root:/root:/bin/bash
- bin:x:1:1:bin:/bin:/sbin/nologin
- bin:x:1:1:bin:/bin:/sbin/nologin
- daemon:x:2:2:daemon:/sbin:/sbin/nologin
- daemon:x:2:2:daemon:/sbin:/sbin/nologin
6、数组遍历–用来统计网站日志的访问量。
- ++i:从1开始加,运算在赋值
- i++: 从0开始加,赋值在运算
- #按索引遍历:
- 1.先创建一个test文件,统计用户的数量
- # vim test.txt #将文件内容的第一个字段作为数组的值,通过索引获取到值
- root:x:0:0:root:/root:/bin/bash
- bin:x:1:1:bin:/bin:/sbin/nologin
- # cat test.txt | awk -F":" '{username[x++]=$1} END{for(i in username) {print i,username[i]}}'
- 0 root
- 1 bin
- #注意:变量i是索引
7、真实案例
- #把要统计的对象作为索引,最后对他们的值进行累加,累加出来的这个值就是你的统计数量
- 1. 统计/etc/passwd中各种类型shell的数量
- # cat /etc/passwd | awk -F: '{shells[$NF]++} END{ for(i in shells){print i,shells[i]} }'
- 2.统计nginx日志出现的状态码
- # cat access.log | awk '{stat[$9]++} END{for(i in stat){print i,stat[i]}}'
- 3.统计当前nginx日志中每个ip访问的数量
- # cat access.log | awk '{ips[$1]++} END{for(i in ips){print i,ips[i]}}'
- 4.统计某一天的nginx日志中的不同ip的访问量
- # cat access.log |grep '28/Sep/2019' | awk '{ips[$1]++} END{for(i in ips){print i,ips[i]}}'
- 5.统计nginx日志中某一天访问最多的前10个ip
- # cat access.log |grep '28/Sep/2019' | awk '{ips[$1]++} END{for(i in ips){print i,ips[i]}}' |sort -k2 -rn | head -n 10
- sort:排序,默认升序
- -k:指定列数
- -r:降序
- -n:以数值来排序
- 6.统计tcp连接的状态---下去自己查各个状态,包括什么原因造成的!
- # netstat -n | awk '/^tcp/ {tcps[$NF]++} END {for(i in tcps) {print i, tcps[i]}}'
- LAST_ACK 5 (正在等待处理的请求数)
- SYN_RECV 30
- ESTABLISHED 1597 (正常数据传输状态)
- FIN_WAIT1 51
- FIN_WAIT2 504
- TIME_WAIT 1057 (处理完毕,等待超时结束的请求数)
8、经典案例
- UV与PV统计
- PV:即访问量,也就是访问您商铺的次数;
- 例如:今天显示有300 PV,则证明今天你的商铺被访问了300次。
- ================================================================
- UV:即访问人数,也就是有多少人来过您的商铺; #需要去重
- 例如:今天显示有50 UV,则证明今天有50个人来过你的商铺。
- =================================================================
- 1.根据访问IP统计UV
- # cat access.log | awk '{print $1}' |sort |uniq | wc -l
- uniq:去重
- -c:统计每行连续出现的次数
- 2.更具访问ip统计PV
- # cat access.log | awk '{print $1}' |wc -l
- 或者是url
- # cat access.log | awk '{print $7}' |wc -l
- 3.查询访问最频繁的URL
- # cat access.log | awk '{print $7}'|sort | uniq -c |sort -n -k 1 -r | more
- 4.查询访问最频繁的IP
- # cat access.log | awk '{print $1}'|sort | uniq -c |sort -n -k 1 -r | more
功能实现:切割nginx的日志,统计PV\UV,出现次数最多的url等各种切割统计
13、Shell Expect
在实际工作中我们运行命令、脚本或程序时, 都需要从终端输入某些继续运行的指令,而这些输 入都需要人为的手工进行. 而利用 expect 则可以根据程序的提示, 模拟标准输入提供给程序, 从而实现自动化交互执 行. 这就是 expect .
它是一个免费的编程工具, 用来实现自动的交互式任务, 而无需人为干预. 说白了 expect 就是一套用来实现自动交互功能的软件
既:通过expect可以实现将交互式的命令变为非交互式执行,不需要人为干预(手动输入)
No.1 expect的安装
[root@qfedu ~] yum -y install expectNo.2 expect的语法:
- 用法:
- 1)定义expect脚本执行的shell
- #!/usr/bin/expect -----类似于#!/bin/bash
- 2)spawn
- spawn是执行expect之后后执行的内部命令开启一个会话 #功能:用来执行shell的交互命令
- 3)expect ---相当于捕捉
- 功能:判断输出结果是否包含某项字符串(相当于捕捉命令的返回的提示)。没有捕捉到则会断开,否则等待一段时间后返回,等待通过timeout设置
- 4)send
- 执行交互动作,将交互要执行的命令进行发送给交互指令,命令字符串结尾要加上“\r”,#---相当于回车
- 5)interact
- 执行完后保持交互状态,需要等待手动退出交互状态,如果不加这一项,交互完成会自动退出
- 6)exp_continue
- 继续执行接下来的操作
- 7)timeout
- 返回设置超时时间(秒)
实战非交互式ssh连接:
- 案例1:普通操作
- [root@qfedu script]# vim expect01.sh
- #!/usr/bin/expect
- spawn ssh root@192.168.246.115
- expect {
- "yes/no" { send "yes\r"; exp_continue }
- "password:" { send "1\r" };
- }
- interact
- [root@qfedu script]# chmod +x expect01.sh
- [root@qfedu script]# ./expect01.sh
- spawn ssh root@192.168.246.115
- root@192.168.246.115's password:
- Last login: Fri Aug 28 16:57:09 2019
- #如果添加interact参数将会等待我们手动交互进行退出。如果不加interact参数在登录成功之后会立刻退出。
- ============================================================================
-
相关阅读:
vue项目引入bpmn做一款可以拖拽 输入的审核流程图
[解题报告] CSDN竞赛第11期
OpenKruise-原地升级
gitlab
mysql中的函数
python的环境安装(版本3.10.6)
50-C语言-输入n个数,并且从中输出奇数,按升序排列
这可能是你需要的vue考点梳理
ARM32开发--存储器介绍
双向链表(带头双向循环链表)的实现
- 原文地址:https://blog.csdn.net/zhouzhiwengang/article/details/127350327
