-
leetcode 90. 子集 II-java实现
题目所属分类
但是区别在于这个要去掉重复的子集 方法目前我发现了三种:
1、用哈希表储存 每个元素出现的次数

2、排序 然后在递归起点到重复元素的最后一个上
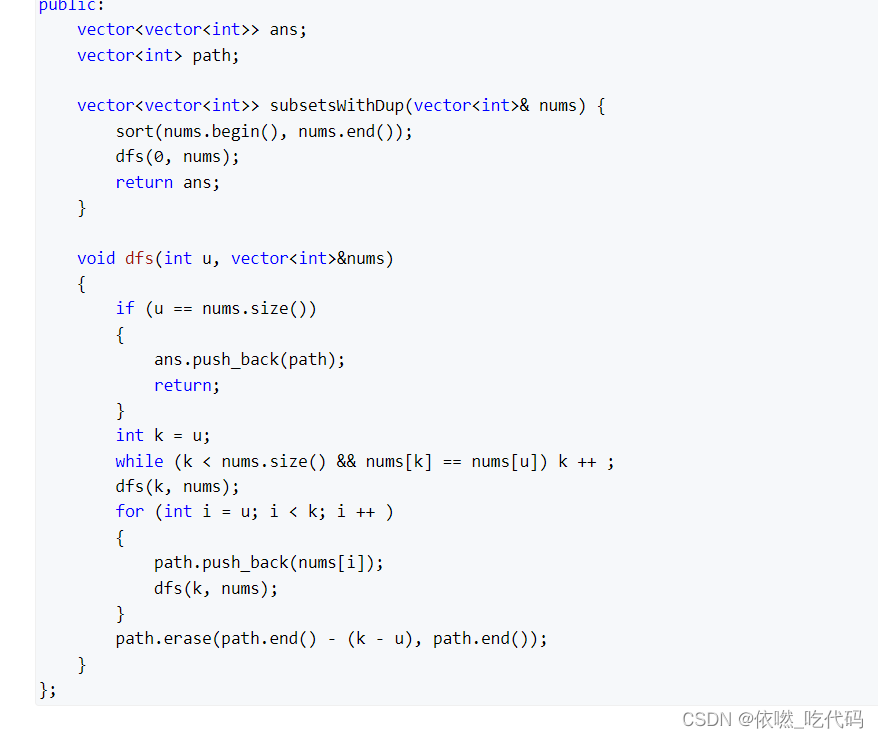
3、排序 但是按照传统的方式来做
- 先对数组从小到大排序,每个数有选和不选两种情况,若选的话,假设上一个数与当前数一致,且上一个数没有选,则当前数一定不能选,否则会产生重复情况

原题链接
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
1 <= nums.length <= 10
-10 <= nums[i] <= 10代码案例:输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]题解
时间复杂度分析:不同子集的个数最多有 2^n 个,另外存储答案时还需要 O(n) 的计算量,所以时间复杂度是 O(n*2^n) 。
class Solution { List<Integer> path = new ArrayList<>(); List<List<Integer>> ans = new ArrayList<>(); boolean[] st ; public List<List<Integer>> subsetsWithDup(int[] nums) { int n = nums.length; st = new boolean[n+1]; Arrays.sort(nums); dfs(nums,0,n); return ans ; } public void dfs(int[] nums , int u , int n ){ if(u == n){ ans.add(new ArrayList<Integer>(path)); return ; } //不选 dfs(nums,u+1,n); //选 if(u>0 && nums[u] == nums[u-1] && !st[u-1]) return ; st[u] = true ; path.add(nums[u]); dfs(nums,u+1,n); //恢复 path.remove(path.size()-1); st[u] = false; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 先对数组从小到大排序,每个数有选和不选两种情况,若选的话,假设上一个数与当前数一致,且上一个数没有选,则当前数一定不能选,否则会产生重复情况
-
相关阅读:
docker 构建python Dockerfile
ASP.NET 中验证的自定义返回和统一社会信用代码的内置验证实现
c语言 - 实现每隔1秒向文件中写入当前系统时间
可视化的mysql慢日志平台,帮助数据库管理员(DBA)和开发者更好地管理和监控 MySQL 数据库的慢查询日志
【web-渗透测试方法】(15.8)测试逻辑缺陷、共享主机漏洞、Web服务器漏洞、信息泄露
redis源码值CRC校验
OSINT技术情报精选·2024年5月第1周
java中对象和类应用实例
HTML5与CSS3实现动态网页(下)
分布式锁之 redis & redisson (你学了 synchronized 真的有用吗?)
- 原文地址:https://blog.csdn.net/qq_41810415/article/details/127400445
