-
【数据结构与算法】图的介绍和程序实现(含深度优先遍历、广度优先遍历)
1. 为什么需要图数据结构
我们前面学习的链表和树都不能满足多对多的关系。所以需要图这种数据结构,来实现节点之间的多对多关系
2. 图的介绍
图的节点可以具有零个或多个相邻元素。两个节点之间的连接称为边(edge)。 节点也可称为顶点(vertex)。如下所示:
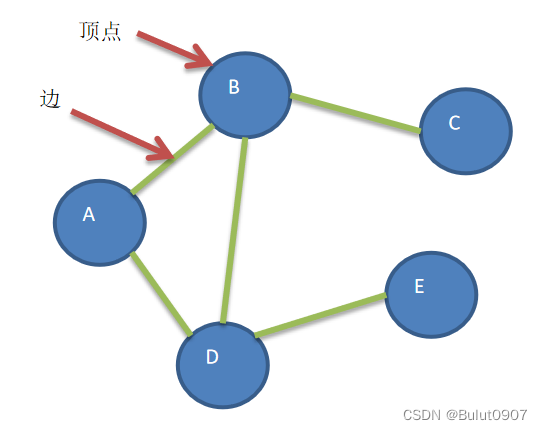 图的说明:
图的说明:- 路径:比如从D -> C的路径有D->B->C和D->A->B->C
- 无向图:上面的图就是一个无向图。顶点之间的连接没有方向
- 有向图:顶点之间的连接有方向。比如A -> B,只能是A -> B,不能是B -> A
- 带权图:边具有权值,比如距离大小。带权图也叫网
3. 图的表示方式
图的表示方式有两种:二维数组表示(邻接矩阵)、链表表示(邻接表)
邻接矩阵:
邻接矩阵是表示图形中顶点之间相邻关系的矩阵,对于n个顶点的图而言,矩阵是由n*n的二维矩阵表示。如下所示: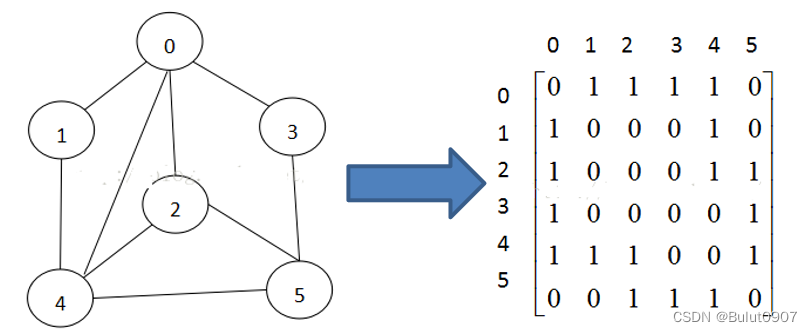
邻接表:
邻接矩阵需要为每个顶点都分配n个边的空间,其实有很多边都是不存在的, 会造成空间的一定损失
邻接表的实现只关心存在的边,不关心不存在的边。因此没有空间浪费,邻接表由数组 + 链表组成
如下所示。标号为0的节点的相关联的节点为1、2、3、4,其它的类似
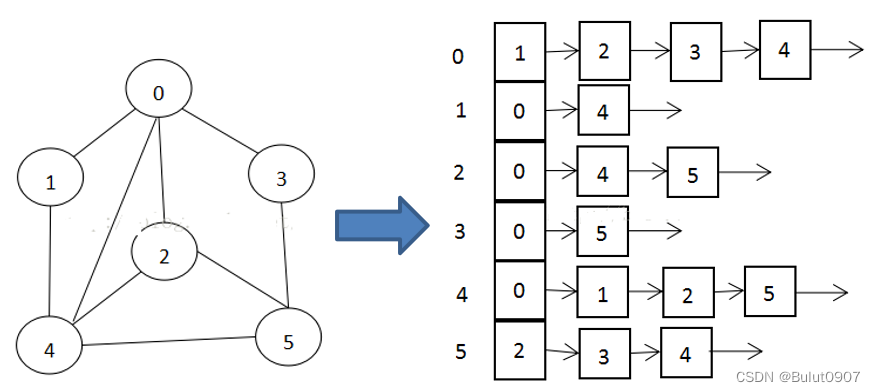
4. 图的遍历
4.1 深度优先遍历
深度优先遍历也叫深度优先搜索(Depth First Search)
- 从初始访问节点出发,首先访问第一个邻接节点,然后再以这个被访问的邻接节点作为初始节点,访问它的第一个邻接节点, 依次类推
- 策略是优先往纵向挖掘深入,而不是对一个节点的所有邻接节点进行横向访问。深度优先搜索是一个递归的过程
深度优先遍历算法步骤:
- 访问初始节点v,并标记节点v为已访问
- 查找节点v的第一个邻接节点w
- 如果w不存在,则把v节点的下一个节点当作另一个v,转到步骤1
4.1 如果w存在,且未被访问,则把w当做另一个v,然后转到步骤1
4.2 此时w存在,且一定被访问过,再从v节点的w邻接节点的下一个邻接节点继续,转到步骤3
4.2 广度优先遍历
广度优先遍历也叫广度优先搜索(Broad First Search)
- 类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以顺序保持访问过的节点index,然后按照这个顺序一层层的访问这些节点的邻接节点
- 策略是优先往横向挖掘,对一个节点的所有邻接节点进行横向访问。广度优先搜索是一个迭代的过程
广度优先遍历算法步骤:
- 访问初始节点v,并标记节点v为已访问,再将节点v入队列
- 当队列为空时,则把v节点的下一个节点当作另一个v,转到步骤1
- 当队列非空时,取队列头节点u,查找节点u的第一个邻接节点w
- 如果w不存在,则转到步骤2
5.1 如果w存在,且未被访问,则访问节点w,并标记节点w为已访问,再将节点w入队列
5.2 此时w存在,且一定被访问过,再从v节点的w邻接节点的下一个邻接节点继续,转到步骤4
5. 使用邻接矩阵实现图、图的深度优先遍历 + 广度优先遍历实现
程序如下:
import java.util.ArrayList; import java.util.Arrays; import java.util.LinkedList; public class Graph { // 顶点集合 private ArrayListvertexList; // 储存图对应的邻接矩阵 private int[][] edges; // 边的数目 private int numOfEdges; // 记录每个节点是否被遍历过 private boolean[] isVisited; public static void main(String[] args) { // 创建图对象 int vertexNum = 8; Graph graph = new Graph(vertexNum); //循环的添加顶点 String[] vertexs = {"A", "B", "C", "D", "E"}; for (String vertex : vertexs) { graph.addVertex(vertex); } // 添加边 // A-B、A-C、B-C、B-D、B-E graph.addEdge(0, 1, 1); graph.addEdge(0, 2, 1); graph.addEdge(1, 2, 1); graph.addEdge(1, 3, 1); graph.addEdge(1, 4, 1); // 显示邻结矩阵 graph.showGraphEdges(); // 深度遍历测试 System.out.println("深度遍历:"); graph.dfs(); System.out.println(); // 广度遍历测试 System.out.println("广度遍历:"); graph.bfs(); System.out.println(); } public Graph(int vertexNum) { vertexList = new ArrayList (vertexNum); edges = new int[vertexNum][vertexNum]; numOfEdges = 0; } // 插入节点 public void addVertex(String vertex) { vertexList.add(vertex); } // 添加边 // vertex1Index: 顶点1的index // vertex2Index:顶点2的index // isConnectValue:两个顶点是否连接。0表示两个顶点未连接,1表示两个顶点连接 public void addEdge(int vertex1Index, int vertex2Index, int isConnectValue) { edges[vertex1Index][vertex2Index] = isConnectValue; edges[vertex2Index][vertex1Index] = isConnectValue; numOfEdges++; } // 获取节点的个数 public int getNumOfVertex() { return vertexList.size(); } // 获取边的数目 public int getNumOfEdges() { return numOfEdges; } // 根据传递的index,获取顶点的值 public String getVertexValueByIndex(int vertexIndex) { return vertexList.get(vertexIndex); } // 根据vertex1Index和vertex2Index,获取两个顶点是否连接的值 public int getIsConnectValue(int vertex1Index, int vertex2Index) { return edges[vertex1Index][vertex2Index]; } // 显示图对应的邻接矩阵 public void showGraphEdges() { for (int[] line : edges) { System.out.println(Arrays.toString(line)); } } // 根据一个节点的index,查询它的第一个邻接节点的index。查询不到则返回-1 public int getFirstNeighborIndex(int vertexIndex) { for (int i = 0; i < vertexList.size(); i++) { if (edges[vertexIndex][i] > 0) { return i; } } return -1; } // 获取一个节点的邻接节点的下一个邻接节点的index public int getNextNeighborIndex(int vertexIndex, int neighborIndex) { for (int i = neighborIndex + 1; i < vertexList.size(); i++) { if (edges[vertexIndex][i] > 0) { return i; } } return -1; } // 深度优先遍历。打印所有顶点的信息,每个顶点只打印一次 public void dfs() { isVisited = new boolean[vertexList.size()]; // 如果w不存在,则把v节点的下一个节点当作另一个v,转到步骤1 for (int vertexIndex = 0; vertexIndex < getNumOfVertex(); vertexIndex++) { if (!isVisited[vertexIndex]) { dfs(isVisited, vertexIndex); } } } // 深度优先遍历算法实现。其中vertexIndex为顶点的index private void dfs(boolean[] isVisited, int vertexIndex) { // 访问初始节点v,并标记节点v为已访问 System.out.print("->" + getVertexValueByIndex(vertexIndex)); isVisited[vertexIndex] = true; // 查找节点v的第一个邻接节点w int w = getFirstNeighborIndex(vertexIndex); while (w != -1) { // 如果w存在,且未被访问,则把w当做另一个v,然后转到步骤1 if (!isVisited[w]) { dfs(isVisited, w); } // 此时w存在,且一定被访问过,再从v节点的w邻接节点的下一个邻接节点继续,转到步骤3 w = getNextNeighborIndex(vertexIndex, w); } } // 广度优先遍历。打印所有顶点的信息,每个顶点只打印一次 public void bfs() { isVisited = new boolean[vertexList.size()]; // 当队列为空时,则把v节点的下一个节点当作另一个v,转到步骤1 for (int vertexIndex = 0; vertexIndex < getNumOfVertex(); vertexIndex++) { if (!isVisited[vertexIndex]) { bfs(isVisited, vertexIndex); } } } // 广度优先遍历算法实现。其中vertexIndex为顶点的index private void bfs(boolean[] isVisited, int vertexIndex) { // 表示队列头节点对应的index int u; // 当前处理节点的一个邻接节点的index int w; // 使用队列顺序保持访问过的节点index LinkedList queue = new LinkedList(); // 访问初始节点v,并标记节点v为已访问,再将节点v入队列 System.out.print("->" + getVertexValueByIndex(vertexIndex)); isVisited[vertexIndex] = true; queue.addLast(vertexIndex); while (!queue.isEmpty()) { // 当队列非空时,取队列头节点u,查找节点u的第一个邻接节点w u = queue.removeFirst(); w = getFirstNeighborIndex(u); while (w != -1) { if (!isVisited[w]) { // 如果w存在,且未被访问,则访问节点w,并标记节点w为已访问,再将节点w入队列 System.out.print("->" + getVertexValueByIndex(w)); isVisited[w] = true; queue.addLast(w); } // 此时w存在,且一定被访问过,再从v节点的w邻接节点的下一个邻接节点继续,转到步骤4 // 广度优先和深度优先的关键区别在这里。访问了当前节点和当前节点的一个邻接节点, // 然后继续访问当前节点的后面所有邻接节点 w = getNextNeighborIndex(u, w); } } } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
运行程序,结果如下:
[0, 1, 1, 0, 0, 0, 0, 0] [1, 0, 1, 1, 1, 0, 0, 0] [1, 1, 0, 0, 0, 0, 0, 0] [0, 1, 0, 0, 0, 0, 0, 0] [0, 1, 0, 0, 0, 0, 0, 0] [0, 0, 0, 0, 0, 0, 0, 0] [0, 0, 0, 0, 0, 0, 0, 0] [0, 0, 0, 0, 0, 0, 0, 0] 深度遍历: ->A->B->C->D->E 广度遍历: ->A->B->C->D->E- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
相关阅读:
Linux之bind 函数(详细篇)
Python 时间和时间戳相互转换
Go | 基本数据类型
Linux快速上手5:常用命令之帮助命令
SpringMVC全注解开发
[李宏毅老师深度学习视频] 生成式对抗网络(GAN)【持续更新】
多目标优化算法:多目标圆圈搜索算法(Multi-Objective Circle Search Algorithm,MOCSA)
怎么把flac转换成mp3格式?
格拉姆角场GAF将时序数据转换为图像并应用于凯斯西楚大学轴承故障诊断(Python代码,CNN模型)
【LQR】离散代数黎卡提方程的求解,附Matlab/python代码(笔记)
- 原文地址:https://blog.csdn.net/yy8623977/article/details/127110279
