-
深度学习——day43 ID-YOLO——基于驾驶员固定区域的实时突出目标检测
资源下载
II. Related Works
A.Saliency Detection/Fixation Prediction Models
Fig 1,交通拥挤驾驶场景中固定预测模型和目标检测模型的比较。通过我们提出的模型检测到的显着对象,该对象可以呈现驾驶员在这些显着区域中注意的内容和原因。

B. Object Detection Models
Fig 2,通过比较 YOLOv3 和 ID-YOLO,检测与当前驾驶情况密切相关的关键对象更有价值。

C. Saliency Attention and Object Detection Dataset
TABLE 1,显著性注意和物体检测数据集的比较

III. ETOD DATA
Fig 3,使用两个规则来确定在Ft帧图像中是否标记了一个对象:
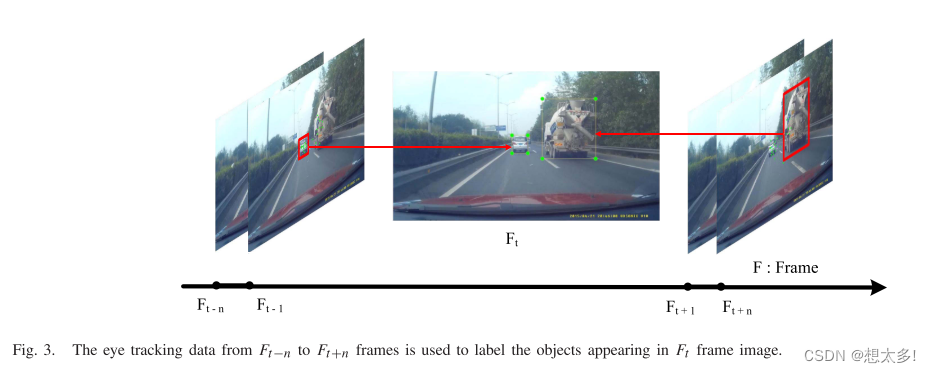
- 当驾驶员花费200毫秒或超过200毫秒 (视频的帧速率为每秒30帧) 聚焦在对象上时,合理地假设该对象对于当前驾驶环境是相关且重要的;
- 一个物体同时引起五个以上(总共28个)驾驶员的注意时,很可能该物体对驾驶具有相关性和重要性。
IV. INCREASE-DECREASE YOLO
提出了一种改进的网络,方法是增加预测规模并减少YOLO (称为ID- YOLO) 的网络深度,以预测驱动程序固定的显着对象。
A. Network Architecture
Fig 4,用红色标记了剩余网络单元的减少数量和增加的特征检测块:
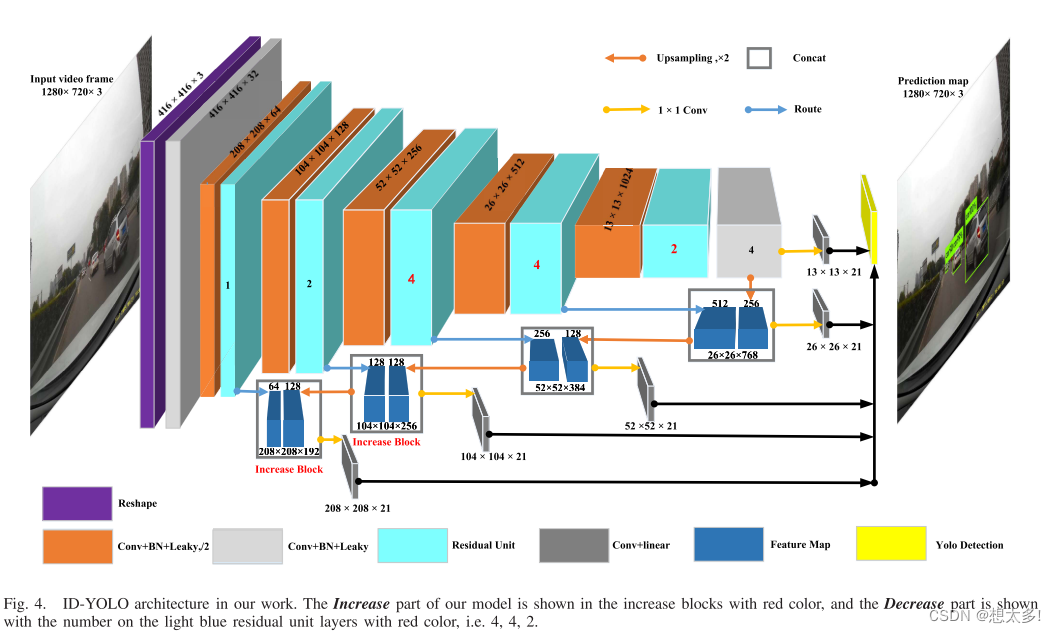
- 在YOLOv3的基础上将对象检测层的数量从3个增加到5个不同的尺度,ID-YOLO可以融合更多有用的特征;
- 在减少部分,我们将原始剩余单元的数量从 (1、2、8、4) 减少到 (1、2、4、2),可以降低计算成本并加快检测速度
Table II,ID-YOLO结构的更多细节,444个卷积层

V. RESULTS
增强的眼动跟踪对象检测 (ETOD) 数据集
B. Qualitative Evaluation
Fig 5,与基于YOLOv3的不同骨干车型相比,我们的车型在黑暗路况下表现出最佳的检测性能,在多次检查和车辆突然发生 (如超车) 的情况下,误检或漏检最少。

Fig 6,ID-YOLO的检测结果与固定标签几乎相同

C. Quantitative Evaluation
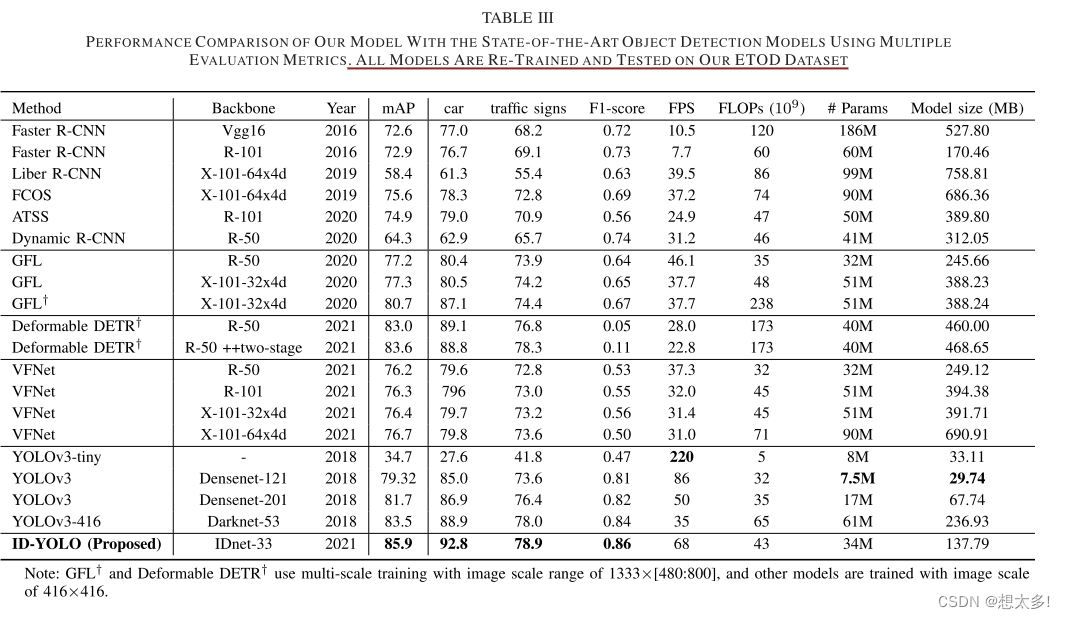
*TABLE III,虽然YOLOv3-tiny的FPS最高,但检测精度最低。我们得出的结论是,与其他模型相比,所提出的ID-YOLO体系结构可以更准确,更快速地预测显着对象。
D. Ablation Study
-
TABLE IV,在YOLOv3的基础上从3到5个不同尺度的目标检测层数量增加的效果,结果表明可以有效地提高检测精度;

-
TABLE V,不同的特征提取层数对检测速度的影响,与ID-YOLO-53相比,ID-YOLO-33具有更高的FPS和更小的模型尺寸,这表明ID-YOLO的减少部分对提高检测速度是有效的

E. Verification With Fixation Points

ID-YOLO比YOLOv3-416的精确度高 -
相关阅读:
java之TextIO库
提取字母后数字
驱动day4
java计算机毕业设计新生入学报到管理系统源码+系统+数据库+lw文档
中高级Java程序员,你不得不掌握的基本功,挑战20k+
2023年中国煤气节能器产量及市场规模分析[图]
处理非线性分类的 SVM一种新方法(Matlab代码实现)
用辗转相除法求两个整数的最大公约数
蓝桥杯刷题|01普及-真题
Tomcat配置文件
- 原文地址:https://blog.csdn.net/qq_43537420/article/details/127360490