-
ML |机器学习模型如何检测和预防过拟合?
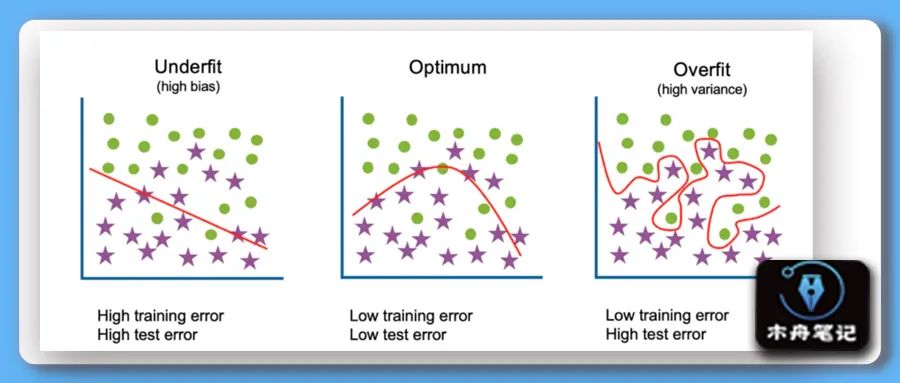
ml_overfit 「过拟合」(overfitting)也称为过学习,它的直观表现是算法在训练集上表现好,但在测试集上表现不好,泛化性能差。同理,「欠拟合」(underfitting)也称为欠学习,它的直观表现是算法训练得到的模型在训练集上表现差,没有学到数据的规律。过拟合和欠拟合会导致模型在未知的数据集上表现较差。
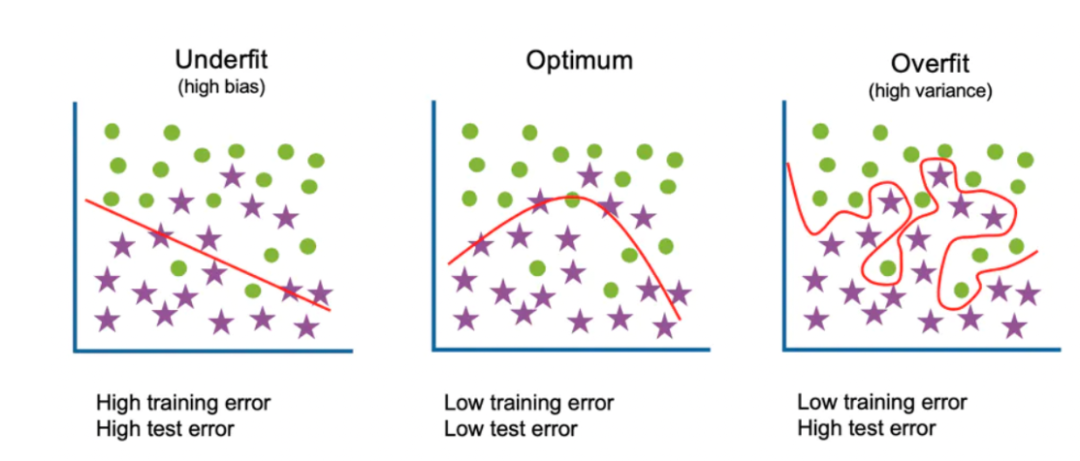
❝
如图,左中右分别代表欠拟合、适度拟合、过拟合三种情况。欠拟合在训练集和测试集上都表现较差;过拟合在训练集上表现较好,在测试集上表现较差;适度拟合则在训练集和测试集上都表现较好。
❞我们也可以从偏差和方差来看待过拟合和欠拟合,模型的泛化误差来自于两部分,分别称为偏差和方差。「偏差」(bias)是模型本身导致的误差,即错误的模型假设所导致的误差,它是模型的预测值的数学期望和真实值之间的差距。「高偏差意味着模型本身的输出值与期望值差距很大,因此会导致欠拟合问题」。「方差」(variance)是由于对训练样本集的小波动敏感而导致的误差。它可以理解为模型预测值的变化范围,即模型预测值的波动程度。「高方差意味着算法对训练样本集中的随机噪声进行建模,从而出现过拟合问题」。「如果模型过于简单,一般会有大的偏差和小的方差;反之如果模型复杂则会有大的方差但偏差很小。」这是一对矛盾,因此我们需要在偏置和方差之间做一个折中。如果我一模型的复杂度作为横坐标,把方差和偏差的值作为纵坐标,可以得到下图所示的两条曲线。
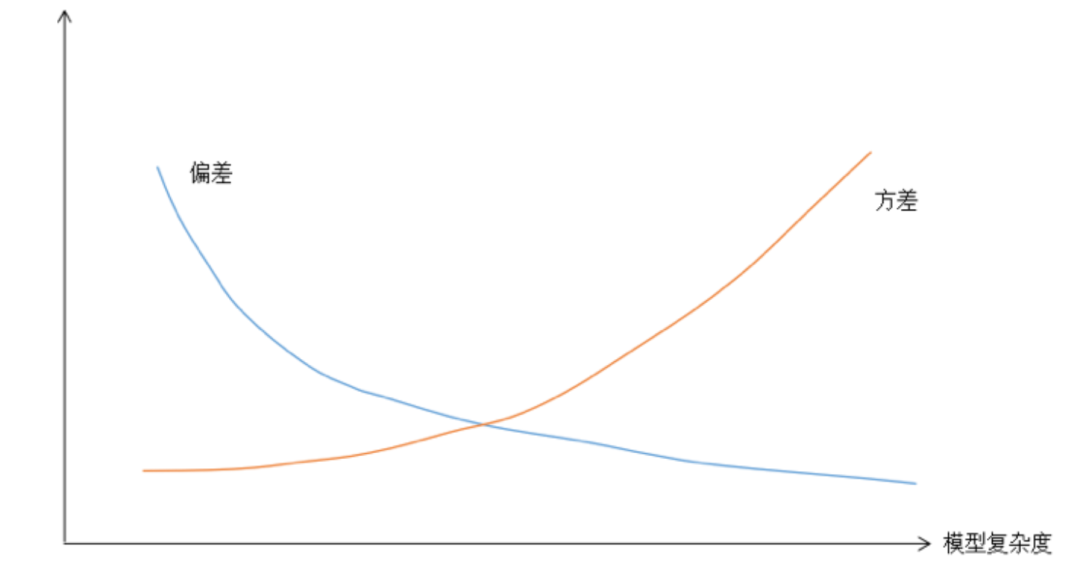
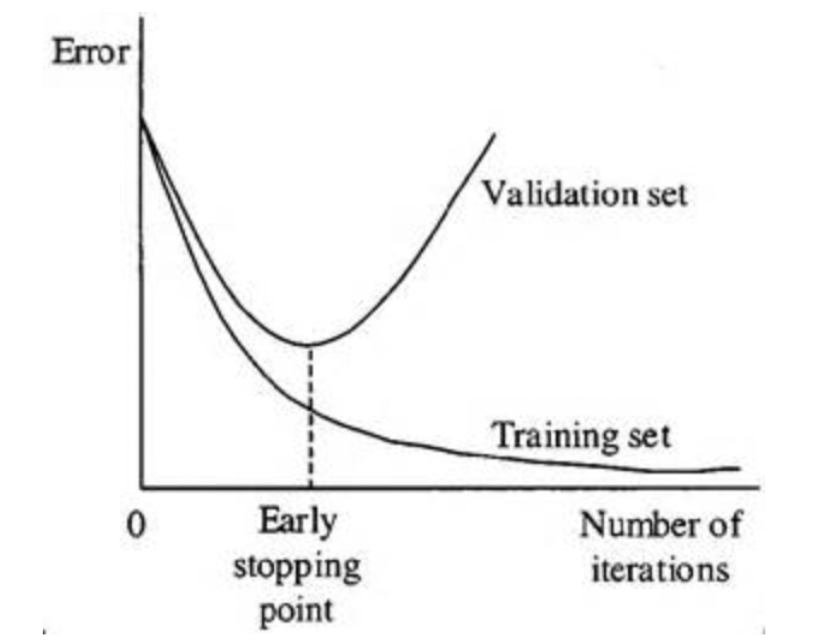
偏差方差与模型复杂度关系 下图为模型「迭代次数」(numbers of iterations)即模型复杂度与训练集和测试集的错误率之间的关系。同样,模型越复杂,在训练集中表现越好,而在测试集中错误率则先下降后上升。因此找到关键点(sweet spot)对建立最优模型至关重要。
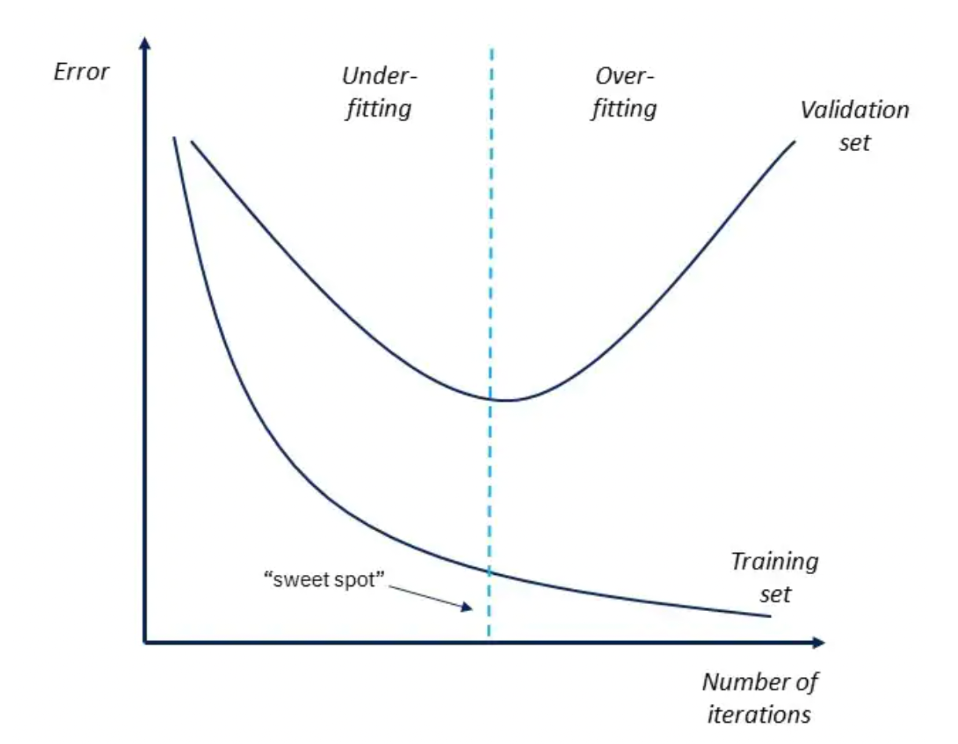
模型迭代次数与训练集验证机错误率的关系 Detection
由于过拟合是一个常见的问题,因此对其进行检测是非常必要的。要检测过拟合数据,前提是它必须用于测试数据。这方面的第一步是将数据集划分为独立的训练和测试集。如果模型在训练集上的表现比测试集上的好,那么它显然是过拟合的。
「Prevent」
在检测到过拟合后,现在模型需要消除它。有各种方法可以防止过拟合,包括:
「使用更多的数据进行训练」:有时,可以通过训练使用更多数据的模型来避免过拟合。一个模型可以输入更多的数据,这样算法就可以更好地检测信号,而不会被过度拟合。然而,这并不是一个有保证的方法。简单地添加更多的数据,特别是当数据不干净的时候,弊大于利。
「早期停止」(Early Stopping)::当一个模型通过多次重复进行训练时,可以对模型的每一次重复进行评估。有一种与重复相关的收益递减模式。最初,模型的性能不断提高,直到达到一个平台后,过拟合开始增加。提前停止是在这个点到来之前暂停这个过程。
Early Stopping 「正则化」(Regularisation)或「数据简化」:有时,即使有大量的数据,当一个模型过于复杂时,它也可能过拟合。这个问题可以通过删除参数的数量,或者对决策树模型进行剪枝(pruning down),或者在神经网络上使用
dropout来解决。❝
dropout的做法是在训练时随机的选择一部分神经元进行正向传播和反向传播,另外一些神经元的参数值保持不变,以减轻过拟合。dropout机制使得每个神经元在训练时只用了样本集中的部分样本,这相当于对样本集进行采样,即bagging的做法。最终得到的是多个神经网络的组合。
❞「删除特征」:这是关于具有内置特征选择的算法。删除不相关的输入特征可以提高模型的可泛化性。
「集成学习」(Ensembling):集成学习是将多个独立模型的预测结合起来。最常用的组合技术是「套袋」(bagging)和「增强」(boosting)。
Bagging是一种通过训练大量按顺序设置的弱学习者来减少模型过拟合的方法。这有助于顺序中的每个学习者从前面一个学习者的错误中学习。Boosting是把所有的弱学习者放在一个单一的序列中,让一个强学习者出现。套袋法适用于复杂的基础模型并使其预测变得平滑,而增强法则是使用基本模型,然后增加它们的总体复杂性。
「数据增强」(Data augmentation):与使用更多数据的训练模型相比,数据增强是更便宜的选择。这种方法不是试图获取更多的数据,而是简单地试图使数据集看起来更加多样化,从而阻止模型学习数据集。这样,每当模型重复一个数据集时,它就显得不同。
另一种类似于数据增强的方法是向输出数据添加噪声。在输入数据中添加适量的噪声可以稳定输入数据,而在输出数据中添加噪声则可以使数据集更加多样化。然而,大量的噪声也会干扰数据集。
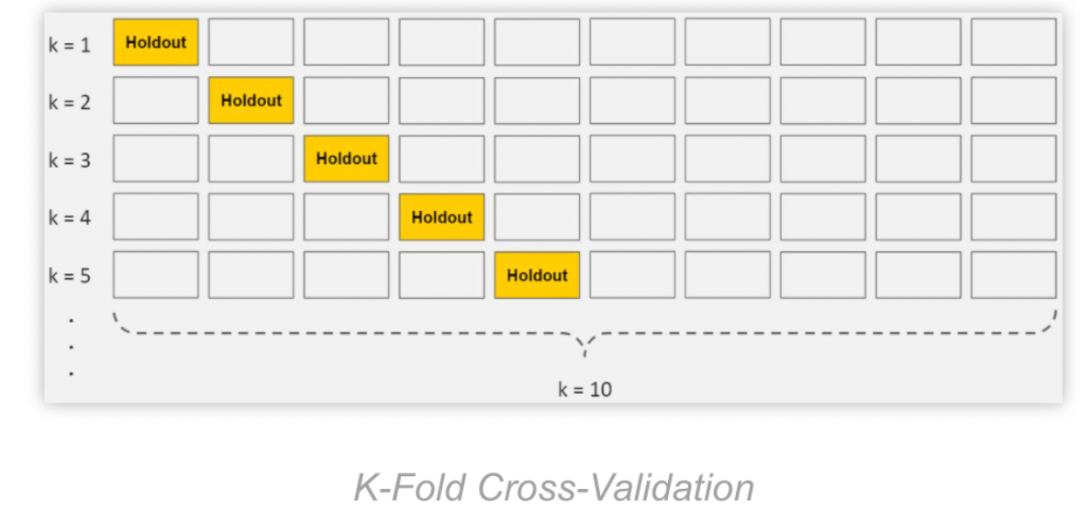
「交叉验证」(Cross-validation):在这种技术中,初始训练数据集被分割成几个小型训练-测试集。然后使用这些小型训练-测试集来调整模型的超参数。这使测试集在最终确定模型之前不可见。
k-fold
参考
https://analyticsindiamag.com/how-to-detect-and-prevent-overfitting-in-a-model/
https://zhuanlan.zhihu.com/p/38224147
往期

木舟笔记矩阵 -
相关阅读:
最优化:建模、算法与理论(最优性理论2
Linux这么在两个服务器直接传文件?
Linux高并发服务器开发第六章:项目执行流程讲解
构造函数继承
数学建模| 优化入门+多目标规划
Direct3D中的绘制
【算法基础】:(二)希尔排序
2022-08-15 - 初识MySQL
简历信息粘贴板
【算法基础】帕累托最优解
- 原文地址:https://blog.csdn.net/weixin_45822007/article/details/127385317