-
map 和 set 的介绍
关联式容器
🧩在之前我们的学习中接触了STL的部分容器,如:vector、list、deque、forword_list 等容器,这些容器统称为序列式容器,因为其底层是线性序列的数据结构,里面存储元素本身。关联式容器也是用来存储数据的,但与序列式容器不同的是,其存储的是
树形结构的关联式容器:
🧩根据应用场景的不同,STL实现了两种不同结构的管理式容器:树形结构和哈希结构。树形结构的关联式容器主要有以下四种:map、set、multimap、multiset。这几个容器使用平衡搜索树(红黑树)作为其底层结构,容器中的元素是一个有序的序列。键值对:
🧩键值对用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量 key 和 value ,key 代表键值,value 表示与 key 对应的信息。SGI - STL中关于键值对的定义:
template<class T1,class T2> struct pair { typedef T1 first_type; typedef T2 second_type; T1 first; T2 second; pair() :first(T1()) ,second(T2()) {} pair(const T1& a,const T2& b) :first(a) ,second(b) {} };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

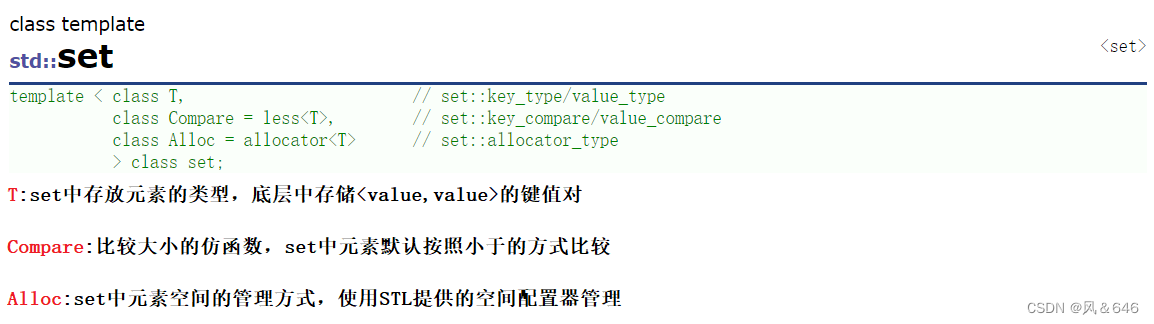
set
- set 是按照特定的顺序存储元素的容器。
- 在 set 中,元素的 value 也标识它(value 就是 key ,类型为 T),并且每个 value 必须是唯一的。set 中的元素不能在容器中修改(元素总是 const),但是可以从容器中插入或删除它们。
- 在内部,set 中的元素总是按照其内部比较对象(类型比较)指示的特定 严格弱排序(strict weak ordering) 标准进行排序。
- set 容器通过 key 访问单个元素的速度通常比 unordered_set 容器慢,但是它们允许根据顺序对子集进行直接迭代。
- set 的底层是通过二叉搜索树(红黑树)实现的。
set的使用
void test_set1() { vector<int> v{ 1,3,5,7,9,2,4,6,8,10,1,3,5,7,9,2,4,6 }; set<int> s(v.begin(), v.end()); // 用vector的迭代器区间构造set // 1.排序 + 去重 // 使用迭代器遍历set并打印 set<int>::iterator it = s.begin(); while (it != s.end()) { cout << *it << " "; // 1 2 3 4 5 6 7 8 9 10 ++it; } cout << endl; // 使用范围for进行set的遍历 for (auto& e : s) { cout << e << " "; } cout << endl; // 2.set的删除 // 先查找,找到了就删除,若没有找到则会报错 auto pos = s.find(6); if (pos != s.end()) s.erase(pos); pos = s.find(11); if (pos != s.end()) // 若没有这一个条件直接删除会报错 s.erase(pos); //数据在set中就删除,不在不删除也不报错 s.erase(8); s.erase(12); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
map
- map 是关联式容器,它按照特定的次序(按照 key 来比较)存储由键值 key 和值 value 组合而成的元素。
- 在 map 中,键值 key 通常用于排序和唯一地标识元素,而 value 值中存储与此键值 key 关联的内容。键值 key 和 value 的类型可能不同,在 map 内部,key 和 value 通过成员类型 value_type 绑定在一起,为其取名为 pair :
typedef pair。value_type - 在内部,map 中的元素总是按照键值 key 进行比较排序的。
- map 中通过键值访问单个元素的速度通常比 unordered_map 容器慢,但是 map 允许根据顺序对元素进行直接迭代。
- map 中支持使用 [] 进行访问,在 [] 中放入 key ,即可找到与 key 对应的 value 值。
- map 的底层结构通常为平衡二叉搜索树(红黑树)。
map的使用

operator[]

operator[]的原理是:
用注意:
在元素访问时,有一个与operator[]类似的操作at()(该接口函数并不常用)函数,都是通过 key 找到与 key 对应的 value 然后返回其引用,不同的是:当 key 不存在时,operator[]用默认的 value 与 key 构造键值对插入,返回该默认 value ,at()函数则直接抛异常。// operator[]的简单实现 mapped_type& operator[](const key_type& k) { pair<iterator, bool> ret = insert(make_pair(k, mapped_type())); return ret.first->second; }- 1
- 2
- 3
- 4
- 5
- 6
map的基本使用:
void test_map() { map<string, string> m; // 1.将键值对<"associative","关联的">插入map中,用pair直接来构造键值对 m.insert(pair<string, string>("associative", "关联的")); // 2.用make_pair来构造键值对 // 好处:不需要声明pair的参数类型,让函数模板自己推演,用起来更方便 m.insert(make_pair("store elements", "存储元素")); // 3.用operator[]向map中插入元素 m["uniquely"] = "独特的、唯一的"; m["internally"] = "在内部、内部的"; // 使用迭代器去遍历map中的元素,可以得到一个按照key排序的序列 map<string, string>::iterator it = m.begin(); while (it != m.end()) { //cout << (*it).first << " -> " << (*it).second << endl; cout << it->first << " -> " << it->second << endl; ++it; } cout << endl; // map中的键值对中key是唯一的,若key已存在map中再次插入则会失败 auto ret = m.insert(make_pair("associative", "关联的")); if (ret.second) cout << "- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
使用map统计次数:
void test_map_count() { // 统计水果出现的次数 string arr[] = { "香蕉","西瓜","苹果","西瓜","西瓜","苹果" ,"苹果","西瓜","苹果","草莓","苹果","西瓜","榴莲" }; 统计次数方式1: //map- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
利用map进行排序:
struct MapItCompare { bool operator()(map<string, int>::iterator x, map<string, int>::iterator y) { return x->second > y->second; } }; void test_map2() { string arr[] = { "香蕉","西瓜","苹果","西瓜","西瓜","苹果" ,"苹果","西瓜","苹果","草莓","苹果","西瓜","榴莲" }; map<string, int> countMap; for (const auto& str : arr) countMap[str]++; // 将数据导入vector中,用vector排序,比较方式用map中的第二个参数比较 vector<map<string, int>::iterator> v; map<string, int>::iterator countMapIt = countMap.begin(); while (countMapIt != countMap.end()) { v.push_back(countMapIt); ++countMapIt; } // 传入比较方式的仿函数 sort(v.begin(), v.end(), MapItCompare()); // 利用map进行排序 - 拷贝pair数据 map<int, string, greater<int>> sortMap; for (auto e : countMap) { sortMap.insert(make_pair(e.second, e.first)); } // 利用set进行排序 - 不拷贝 set<map<string, int>::iterator, MapItCompare> sortSet; countMapIt = countMap.begin(); while (countMapIt != countMap.end()) { sortSet.insert(countMapIt); ++countMapIt; } // 利用优先级队列排序 priority_queue<map<string, int>::iterator, vector<map<string, int>::iterator>, MapItCompare> pq; countMapIt = countMap.begin(); while (countMapIt != countMap.end()) { pq.push(countMapIt); ++countMapIt; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
总结:
- map 中的元素是键值对
- map 中的 key 是唯一的,不可以修改
- map 中的默认比较方式是按照小于的方式对 key 进行比较
- map 使用迭代器遍历可以得到一个有序的序列,其底层是红黑树结构,查找数据高效
- 支持 [] 操作符,operator[] 中实际进行插入查找
multimap
- multimap 是关联式容器,它存储由键值和映射值按特定顺序组合而成的元素,其中元素是可以有重复的。
- 在 multimap 中,key 通常用于对元素进行排序和唯一标识,映射的 value 存储与 key 关联的内容。key 和 value 的类型可能不同,通过 multimap 内部的成员类型 value_type 组合在一起,value_type 是组合 key 和 value 的键值对:
typedef pair。value_type - 在内部,multimap 中的元素总是通过其内部比较对象按照特定的严格弱排序(strict weak ordering)标准对 key 进行排序。
- multimap 通过 key 访问单个元素的速度通常比 unordered_multimap 容从器慢,但是可以使用迭代器直接遍历 multimap 中的元素可以得到关于 key 有序的序列。
- multimap 的底层结构是二叉搜索树(红黑树)。
multimap的使用
❗ multimap 和 map 的唯一不同就是:map 中的 key 是唯一的,而 multimap 中的 key 是可以重复的。注意:multimap 中没有重载 operator[] 操作。
multiset
- multiset 是按照特定的顺序存储元素的容器,其中的元素是可以重复的。
- 在 multiset 中,元素的 value 值也可以标识它(multiset 中存储的是
- 在内部,multiset 中的元素总是按照其内部比较规则所指示的特定严格弱排序标准进行排序。
- multiset 容器通过 key 访问单个元素的速度通常比 unordered_multiset 容器慢,使用迭代器访问会得到一个有序的序列。
- multiset 的底层结构是二叉搜索树(红黑树)。
multiset的使用
❗ multiset 和 set 的唯一不同就是:set 中的 key 是唯一的,而 multiset 中的 key 是可以重复的。
-
相关阅读:
【云备份|| 日志 day5】文件热点管理模块
Vue使用脚手架(VueCLI)搭建项目时,包管理器(npm、Yarn、pnpm等)的选择问题
【Rust日报】2022-11-05 Slint语言的新变化
C语言程序设计-10 指针
HashMap和Hashtable的区别源码对比(一)
64. 最小路径和 java解决
智慧工地管理系统源码(电脑端+手机端+APP+SAAS云平台)
C#闭包详解
MySQL 索引的使用和设计
5G消息发展的前景与挑战
- 原文地址:https://blog.csdn.net/qq_61939403/article/details/127358362
