-
多层感知机 MLP
mlp - dl4j多层感知机mnist识别
神经网络是具有适应性的简单单元组成的广泛并行互联的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
M-P神经元模型:
神经元接受n个其他神经元传递的输入信号并通过带权连接紧进行传播,神经元接收到的总输入值与神经元的阈值进行比较,通过“激活函数”处理以产生神经元的输出。
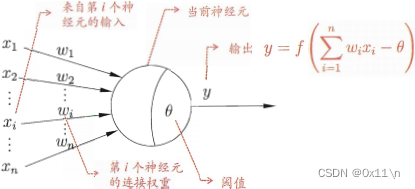
激活函数:
理想中的激活函数具有0、1二值性的阶跃函数,和具有0、1连续性的Sigmoid函数

从计算机科学的角度来看,神经网络可以视为包含了许多参数的数学模型,这个模型是若干个函数相互嵌套带入而得,有效的神经网络学习算法大多以数学证明为支撑。
感知机:
感知机由两层神经元组成,输入层接受外界信号传递给输出层,输出层是M-P神经元
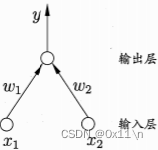
感知机能容易地实现逻辑与或非运算,M-P神经元的输出由f函数)计算,假设这里f函数就是阶跃函数(即x>0则y=1,x<0则y=0)
与:取w1=w2=1,θ=2,则y=f(x1+x2-2),当x1=x2=1时y=1

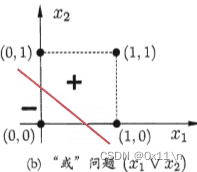
或:取w1=w2=1,θ=0.5,则y=f(x1+x2-0.5),当x1=1或x2=1时y=1
非:取w1=-0.6,w2=,0,θ=-0.5,则y=f(-0.6*x1+0.5),当x1=1时y=0,当x1=0时y=1

更一般的,给定训练集。权向量w和阈值θ可以通过学习得到,具体调整方式为,对于样本(x,y)若当前感知机输出为y^,则w调整为
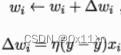
其中η∈(0,1)称为学习率,若样本(x,y)预测正确即y=y^,则感知机不发生变化。若样本(x,y)预测错误则根据错误的程度进行权重w的调整。
感知机只有输出层神经元是M-P神经元(即进行了激活函数处理),则只拥有一层功能神经元,其学习能力有限。与或非问题是线性可分的问题(见面图),两类样本可以是线性可分的则存在一个平面将他们分开,且最终感知机学习过程一定会收敛(得到一组稳定合适的w)。异或问题不是线性可分问题,感知机学习过程会发生震荡w难以稳定,即不能找到一对w1和w2,使得x1=x2时y=0,使得x1!=x2时y=1,换句话说即不能找到一条直线将(0,0)和(1,1)归为一类,(1,0)和(0,1)归为一类

多层前馈神经网络:
由于感知机不能解决异或问题,而需要使用包含多层功能神经元的网络。当多隐层和输出层都是M-P神经元(功能神经元)时,神经元之间无同层连接和跨层连接的神经网络结构称为多层前馈神经网络

单隐层前馈网络(两层感知机-包含两层功能神经元),与之前的只有一层M-P神经元的感知机仅仅多了一个隐层就能解决异或问题

神经网络的学习过程就是根据训练样本来调整神经元之间的连接权w以及每个功能神经元的阈值,学习得到的模型也就是这一组收敛稳定的w和θ。
误差逆传播算法:
多层网络的学习能力比单层感知机强得多,想要训练多层网络,M-P神经元通过y和y^调整w的方法就不够用了,需要更加强大的学习算法,误差逆传播算法(BP算法)是杰出和成功的代表。

对于每个样本,先将输入示例提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结果

对比期望值得到误差(网络在样本(xk,yk)上的均方误差),然后将误差传递至隐藏神经元,将误差分摊给各层的各个单元,计算各层各个单元的误差信号,并将其作为修正各单元权值w的根据。对于训练样本(xk,yk),求得预测值、均方损失如下
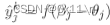

其中 根据β定义,以及 β对w求导得到b


我们的目的是求w使得均方损失最小化。当均方损失收敛(稳定)的时候,均方损失变化率(导数)趋近于0,此时w也收敛,得到一组最优w。给定初始学习率η,根据链式法则有
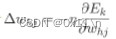

因为sigmoid函数有个很好的性质
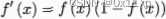
所以上面三段式中的前两段可以转化为

则可以得到w的更新式
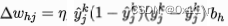
可以发现,上式中的所有参数都是网络中的已知参数,即逆传播算法给梯度下降提供了数据基础,每个样本都会触发一次w更新,当最终误差在可接受范围且变化幅度很小的时候,得到一组可能比较好w。
标准BP算法和累积BP算法:
标准BP算法只针对单个样本,参数更新非常频繁,且针对不同的样本可能造成w更新相互“抵消”。累积BP算法是在跑完全部样本之后得到一个累积误差,用累积误差E来求得w的更新式。
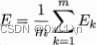
BP网络过拟合:
正因为BP网络强大的表示能力,经常造成训练误差持续下降而测试误差上升。通常有两种策略来防止过拟合,一种是“早停”,将样本划分为训练集和评分集,用训练集去学习w用评分集去估计误差,如果训练集误差降低但是评分集误差上升则网络停止学习。第二种是“正则化”,在目标函数中增加一个用于描述网络复杂度的部分,例如连接权和阈值的平方和,将误差目标函数替换

其中λ∈(0,1)用于对经验误差与网络复杂项这两式子进行折中,常通过交叉验证法来估计。
局部最小和全局最小:
从前面推导,E表示神经网络在训练集上的误差,他是关于连接权w和θ的函数,所以神经网络的训练过程可以看做一个参数寻优过程,则在参数空间中寻找一组最有参数使得E最小。空间内梯度为0的点,他在相邻的点中肯定是极小值,可能是局部极小值也可能是全局极小值。很多时候误差函数可能具有多个局部极小。

在具体求解的过程中,可以试图“跳出”局部极小,从而进一步接近全局最小:
(1)以多组不同参数初始化神经网络,按照标准方法训练之后取误差最小的解最为最终参数。因为这相当于从空间中多个不同的点开始按照梯度方向搜索,这样陷入局部最小的可能性更低。
(2)使用“模拟退火”,在每一步都以一定概率接受比当前解更差的结果,从而有利于跳出局部极小。
(3)随机梯度下降,在计算梯度时加入随机因素,这样即使陷入局部极小点但它计算出的梯度仍可能不为零,这样有几率跳出局部极小继续搜索,
(4)遗传算法
dl4j多层感知机的网络构建:

-
相关阅读:
云上竞技,360°见证速度与激情
使用 FasterTransformer 和 Triton 推理服务器部署 GPT-J 和 T5
ADI一级代理商:ADI代理商的采样与效果
河北工业大学计算机考研资料汇总
基于SpringBoot的民宿在线预定平台
在PicGo上使用github图床解决typora上传csdn图片不显示问题(保姆级教程)
和数集团:我国区块链行业发展具有广阔前景
【系统架构设计】架构核心知识:4 系统可靠性分析与设计
线性代数 --- 线性代数学习帖总纲
springBoot视频在线播放,支持快进,分片播放
- 原文地址:https://blog.csdn.net/qq_34448345/article/details/127407377