-
接口查询优化:优雅的处理大批量数据及 in 超过 1000 问题

一、问题点
- 有时候在查询数据时可能需要根据【A表】的某个 ID 去获取 【B表】 的具体信息,但是又因为数据量的庞大,我们需要对 【A表】查出来的数据结果进行分页处理之后再循环调用【B表】
二、解决方案
1、在业务层面用Java代码进行分页处理
- 比如:通过策略ID去获取当前策略下的订单信息,那么为了防止订单信息过多我们可以这么做
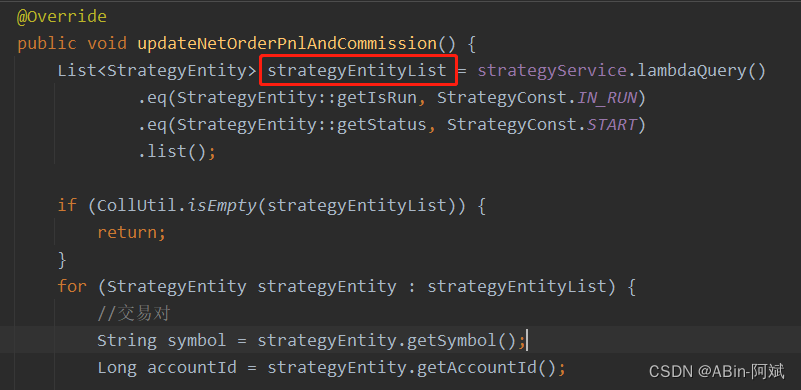
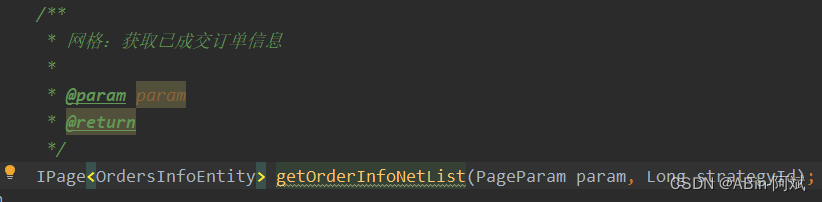
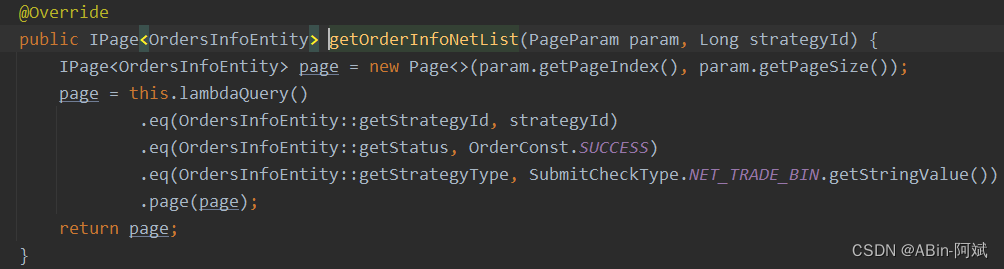
- 首先将查询获取订单信息在Service层写一个分页接口,然后进行调用
- 具体的分页参数信息可以根据业务来定,这里进行分批处理,一页:100条
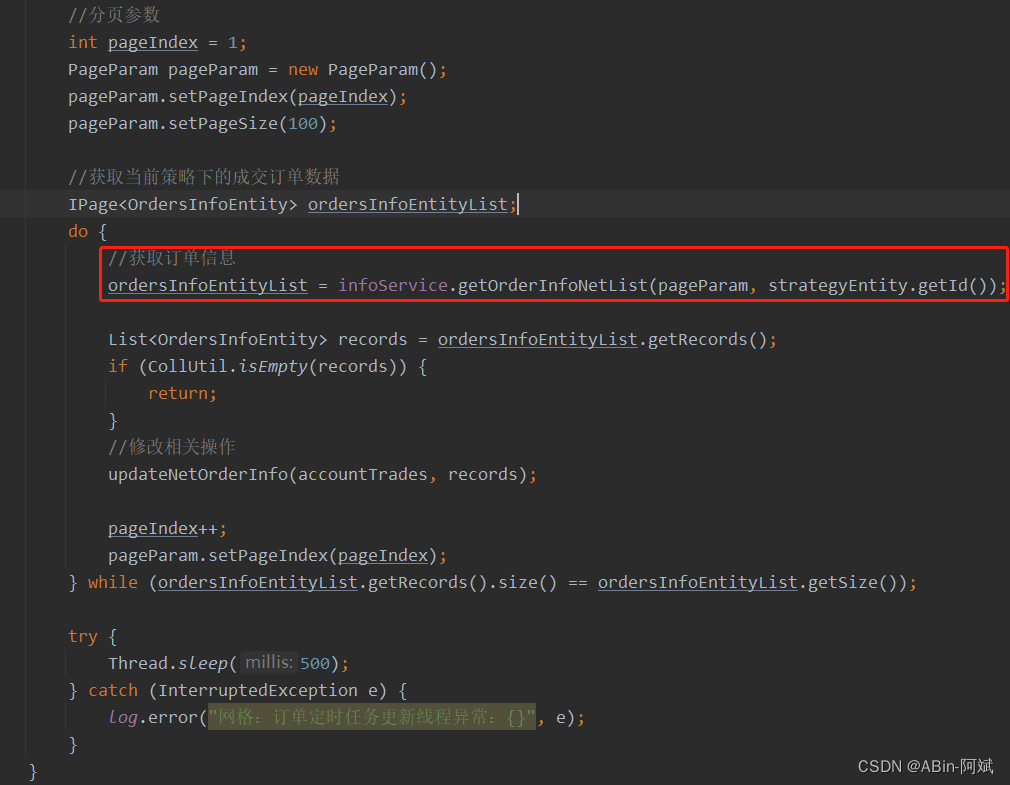
- 然后进行循环翻页处理
2、使用工具类 List 总数切分
-
注意: ListUtil.partition(),这个方法从某种意义上说并没有达到真正分页的效果,因为当我们使用这个方法时,List结果早已执行出来了;我们要做的就是在结果没有出来之前就减少 DB 的压力。
-
当然,具体业务具体分析,少量的数据可以使用这个方法
-
直接使用 Hutool 工具类中的 ListUtil.partition(list,100)方法,参数一: 具体 list、参数二: 具体分多少条
3、自己封装一个分页工具类
- 下面这个工具类适用于 MyBatisPlus
工具类代码
public class MybatisParameterUtils { public static <T, F> void cutInParameter(LambdaQueryWrapper<T> wrapper, SFunction<T, ?> column, List<F> coll) throws Exception { List<List<F>> newList = splitList(coll, 900); if (ObjectUtils.isEmpty(newList)) { throw new Exception("参数错误"); } else if (newList.size() == 1) { wrapper.in(column, newList.get(0)); return; } wrapper.and(i -> { i.in(column, newList.get(0)); newList.remove(0); for (List<F> objects : newList) { i.or().in(column, objects); } }); } public static <T, F> void cutNotInParameter(LambdaQueryWrapper<T> wrapper, SFunction<T, ?> column, List<F> coll) throws Exception { List<List<F>> newList = splitList(coll, 900); if (ObjectUtils.isEmpty(newList)) { throw new Exception("参数错误"); } else if (newList.size() == 1) { wrapper.notIn(column, newList.get(0)); return; } wrapper.and(i -> { i.in(column, newList.get(0)); newList.remove(0); for (List<F> objects : newList) { i.or().notIn(column, objects); } }); } public static <T, F> void cutInParameter(LambdaQueryChainWrapper<T> wrapper, SFunction<T, ?> column, List<F> coll) throws Exception { List<List<F>> newList = splitList(coll, 900); if (ObjectUtils.isEmpty(newList)) { throw new Exception("参数错误"); } else if (newList.size() == 1) { wrapper.in(column, newList.get(0)); return; } wrapper.and(i -> { i.in(column, newList.get(0)); newList.remove(0); for (List<F> objects : newList) { i.or().in(column, objects); } }); } public static <T, F> void cutNotInParameter(LambdaQueryChainWrapper<T> wrapper, SFunction<T, ?> column, List<F> coll) throws Exception { List<List<F>> newList = splitList(coll, 900); if (ObjectUtils.isEmpty(newList)) { throw new Exception("参数错误"); } else if (newList.size() == 1) { wrapper.notIn(column, newList.get(0)); return; } wrapper.and(i -> { i.in(column, newList.get(0)); newList.remove(0); for (List<F> objects : newList) { i.or().notIn(column, objects); } }); } public static <T, F> void cutInParameter(LambdaUpdateWrapper<T> wrapper, SFunction<T, ?> column, List<F> coll) throws Exception { List<List<F>> newList = splitList(coll, 900); if (ObjectUtils.isEmpty(newList)) { throw new Exception("参数错误"); } else if (newList.size() == 1) { wrapper.in(column, newList.get(0)); return; } wrapper.and(i -> { i.in(column, newList.get(0)); newList.remove(0); for (List<F> objects : newList) { i.or().in(column, objects); } }); } public static <T, F> void cutNotInParameter(LambdaUpdateWrapper<T> wrapper, SFunction<T, ?> column, List<F> coll) throws Exception { List<List<F>> newList = splitList(coll, 900); if (ObjectUtils.isEmpty(newList)) { throw new Exception("参数错误"); } else if (newList.size() == 1) { wrapper.notIn(column, newList.get(0)); return; } wrapper.and(i -> { i.in(column, newList.get(0)); newList.remove(0); for (List<F> objects : newList) { i.or().notIn(column, objects); } }); } public static <T, F> void cutInParameter(LambdaUpdateChainWrapper<T> wrapper, SFunction<T, ?> column, List<F> coll) throws Exception { List<List<F>> newList = splitList(coll, 900); if (ObjectUtils.isEmpty(newList)) { throw new Exception("参数错误"); } else if (newList.size() == 1) { wrapper.in(column, newList.get(0)); return; } wrapper.and(i -> { i.in(column, newList.get(0)); newList.remove(0); for (List<F> objects : newList) { i.or().in(column, objects); } }); } public static <T, F> void cutNotInParameter(LambdaUpdateChainWrapper<T> wrapper, SFunction<T, ?> column, List<F> coll) throws Exception { List<List<F>> newList = splitList(coll, 900); if (ObjectUtils.isEmpty(newList)) { throw new Exception("参数错误"); } else if (newList.size() == 1) { wrapper.notIn(column, newList.get(0)); return; } wrapper.and(i -> { i.in(column, newList.get(0)); newList.remove(0); for (List<F> objects : newList) { i.or().notIn(column, objects); } }); } public static <F> List<List<F>> splitList(List<F> list, int groupSize) { int length = list.size(); // 计算可以分成多少组 int num = (length + groupSize - 1) / groupSize; List<List<F>> newList = new ArrayList<>(num); for (int i = 0; i < num; i++) { // 开始位置 int fromIndex = i * groupSize; // 结束位置 int toIndex = Math.min((i + 1) * groupSize, length); newList.add(list.subList(fromIndex, toIndex)); } return newList; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
案例展示
- 思路就是把条件拆成小于 1000 的组合条件 写 xml 同理
// 这是一个条件wrapper get方法的方法引用 一个参数list MybatisParameterUtils.cutInParameter(deleteInfoWrapper, Vo::getId, list);- 1
- 2
- 要带进去 In 的参数,这个参数有数量可能会很大

- 参数一:wrapper;参数二:要 in 那个的参数;参数三:具体带进去 in 的参数(list)

4、适用于Mybatis SQL写法
<if test="dto.idList != null and dto.idList.size() > 0"> and (t.id IN <foreach collection="dto.idList" index="index" open="(" close=")" item="item" > <if test="index !=0"> <choose> <when test="index % 1000 == 999">) OR t.id IN (</when> <otherwise>,</otherwise> </choose> </if> #{item} </foreach> ) </if>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5、手动计算分页处理方式举例
import java.util.List; public class MassiveDataProcessor { private DataService dataService; // 假设有一个用于操作数据的Service // 分页处理海量数据 public void processMassiveData() { int pageSize = 1000; // 每页数据量 long totalCount = dataService.getTotalCount(); // 获取总数据量 long totalPages = (totalCount + pageSize - 1) / pageSize; // 计算总页数 for (int currentPage = 1; currentPage <= totalPages; currentPage++) { List<Data> dataList = dataService.getDataByPage(currentPage, pageSize); // 获取当前页的数据 batchUpdateData(dataList); // 批量更新当前页的数据 } } // 批量更新数据 private void batchUpdateData(List<Data> dataList) { int batchSize = 100; // 每批次处理的数据量 for (int i = 0; i < dataList.size(); i += batchSize) { List<Data> batchList = dataList.subList(i, Math.min(i + batchSize, dataList.size())); dataService.batchUpdate(batchList); // 调用Service进行批量更新操作 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
6、使用Spring Data JPA分批插入和修改数据(举例)
import org.springframework.data.domain.Page; import org.springframework.data.domain.Pageable; import org.springframework.data.jpa.repository.JpaRepository; public interface YourEntityRepository extends JpaRepository<YourEntity, Long> { Page<YourEntity> findAll(Pageable pageable); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.domain.PageRequest; import org.springframework.stereotype.Service; import java.util.List; @Service public class YourService { @Autowired private YourEntityRepository yourEntityRepository; public void batchUpdate(List<YourEntity> entities) { int pageSize = 1000; // 每批次处理的数量 int currentPage = 0; PageRequest pageRequest = PageRequest.of(currentPage, pageSize); do { Page<YourEntity> page = yourEntityRepository.findAll(pageRequest); List<YourEntity> pageEntities = page.getContent(); // 对当前批次的数据进行处理,例如修改或插入 for (YourEntity entity : pageEntities) { // 修改逻辑 // entity.setSomeField(newValue); // yourEntityRepository.save(entity); // 或者插入逻辑 // yourEntityRepository.save(newEntity); } // 准备下一个批次 currentPage++; pageRequest = PageRequest.of(currentPage, pageSize); } while (page.hasNext()); // 如果还有更多页面,继续循环 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
7、多线程异步分批处理方式
- 点击跳转可观看:基于百年数据的高效添加和修改解决方案
- 点击跳转可观看:手动计算分页,分批添加和修改数据
-
相关阅读:
iview table表格 单元格合并+变色
C库函数详解 - 内存操作函数:memcpy()、memmove()、memset()、memcmp()
【JAVA】excel读取常见问题(涉及格式:xls、xlsx)
【空间&单细胞组学】第1期:单细胞结合空间转录组研究PDAC肿瘤微环境
如何使用前端表格控件实现多数据源整合?
多线程&并发篇---第十二篇
力扣刷题(123. 买卖股票的最佳时机 III)动规
关于低代码和无代码---喧嚣背后的致命问题
你了解Spring Security安全管理框架吗?
Cobalt Strike(四)
- 原文地址:https://blog.csdn.net/Mango_Bin/article/details/125155179
