-
Python版股市情感分析源代码,提取投资者情绪,为决策提供参考
情绪与股市关系的研究由来已久,情绪是市场的一个重要影响因素已成为共识。
15年股灾时,亲历了一次交易灾难,眼见朋友的数千万在一周不到的时间内灰飞烟灭。那段时间市场的疯狂,让人深刻地明白:某些时候,股票市场这个抽象、复杂的系统,反映的不再是价值与供需,而仅仅是人的贪婪与恐惧。说明
这份代码是股市情感分析项目的一部分,这个项目的本意是利用互联网提取投资者情绪,为投资决策的制定提供参考。
在国内这样一个非有效的市场中,分析投资者的情绪似乎更有意义。
这里我们利用标注语料分析股评情感,利用分析结果构建指标,之后研究指标与股市关系。
可以按以下顺序运行代码:python model_ml.py
python compute_sent_idx.py
python plot_sent_idx.py
数据
数据位于data目录下,包括三部分:标注的股评文本:这些数据比较偏门,不是很好找,这里搜集整理了正负语料各4607条,已分词。
从东财股吧抓取的上证指数股评文本:约50万条,时间跨度为17年4月到18年5月。东财上证指数吧十分活跃,约7秒就有人发布一条股评。
上证指数数据:直接从新浪抓取下来的。
模型
情感分类模型也是文本分类模型,常用的包括机器学习模型与深度学习模型。model_ml.py:机器学习模型,对比测试了8个模型。
model_dl.py:深度学习模型,对比测试了3个模型。
结果
在经过情感分析、指标构建这两个流程之后,我们可以得到一些有趣的结果,例如看涨情绪与股市走势的关系。
我们使用的看涨指标公式为:
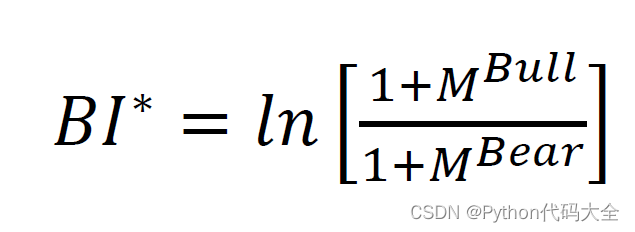
经过处理之后,“看涨”情绪与股市走势的关系可以描画出来:

这里只展示诸多关系中的一个。
总结
这份代码仅为了演示如何从互联网中提取投资者情绪,并研究情绪与股市的关系。
model_ml.pyimport os from time import time import pandas as pd import numpy as np import pickle from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer from sklearn.model_selection import train_test_split, cross_val_score, KFold from sklearn.feature_selection import SelectKBest, chi2 from sklearn.utils.extmath import density from sklearn import svm from sklearn import naive_bayes from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression, SGDClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn import metrics from sklearn.utils import shuffle np.random.seed(42) comment_file = './data/stock_comments_seg.csv' data_path = './data' pos_corpus = 'positive.txt' neg_corpus = 'negative.txt' K_Best_Features = 3000 def load_dataset(): pos_file = os.path.join(data_path, pos_corpus) neg_file = os.path.join(data_path, neg_corpus) pos_sents = [] with open(pos_file, 'r', encoding='utf-8') as f: for sent in f: pos_sents.append(sent.replace('\n', '')) neg_sents = [] with open(neg_file, 'r', encoding='utf-8') as f: for sent in f: neg_sents.append(sent.replace('\n', '')) balance_len = min(len(pos_sents), len(neg_sents)) pos_df = pd.DataFrame(pos_sents, columns=['text']) pos_df['polarity'] = 1 pos_df = pos_df[:balance_len] neg_df = pd.DataFrame(neg_sents, columns=['text']) neg_df['polarity'] = 0 neg_df = neg_df[:balance_len] return pd.concat([pos_df, neg_df]).reset_index(drop=True) # return pd.concat([pos_df, neg_df]).sample(frac=1).reset_index(drop=True) def load_dataset_tokenized(): pos_file = os.path.join(data_path, pos_corpus) neg_file = os.path.join(data_path, neg_corpus) pos_sents = [] with open(pos_file, 'r', encoding='utf-8') as f: for line in f: tokens = line.split(' ') sent = [] for t in tokens: if t.strip(): sent.append(t.strip()) pos_sents.append(sent) neg_sents = [] with open(neg_file, 'r', encoding='utf-8') as f: for line in f: tokens = line.split(' ') sent = [] for t in tokens: if t.strip(): sent.append(t.strip()) neg_sents.append(sent) balance_len = min(len(pos_sents), len(neg_sents)) texts = pos_sents + neg_sents labels = [1] * balance_len + [0] * balance_len return texts, labels def KFold_validation(clf, X, y): acc = [] pos_precision, pos_recall, pos_f1_score = [], [], [] neg_precision, neg_recall, neg_f1_score = [], [], [] kf = KFold(n_splits=5, shuffle=True, random_state=42) for train, test in kf.split(X): X_train = [X[i] for i in train] X_test = [X[i] for i in test] y_train = [y[i] for i in train] y_test = [y[i] for i in test] # vectorizer = TfidfVectorizer(analyzer='word', tokenizer=lambda x : (w for w in x.split(' ') if w.strip())) def dummy_fun(doc): return doc vectorizer = TfidfVectorizer(analyzer='word', tokenizer=dummy_fun, preprocessor=dummy_fun, token_pattern=None) vectorizer.fit(X_train) X_train = vectorizer.transform(X_train) X_test = vectorizer.transform(X_test) clf.fit(X_train, y_train) preds = clf.predict(X_test) acc.append(metrics.accuracy_score(y_test, preds)) pos_precision.append(metrics.precision_score(y_test, preds, pos_label=1)) pos_recall.append(metrics.recall_score(y_test, preds, pos_label=1)) pos_f1_score.append(metrics.f1_score(y_test, preds, pos_label=1)) neg_precision.append(metrics.precision_score(y_test, preds, pos_label=0)) neg_recall.append(metrics.recall_score(y_test, preds, pos_label=0)) neg_f1_score.append(metrics.f1_score(y_test, preds, pos_label=0)) return (np.mean(acc), np.mean(pos_precision), np.mean(pos_recall), np.mean(pos_f1_score), np.mean(neg_precision), np.mean(neg_recall), np.mean(neg_f1_score)) def benchmark_clfs(): print('Loading dataset...') X, y = load_dataset_tokenized() classifiers = [ ('LinearSVC', svm.LinearSVC()), ('LogisticReg', LogisticRegression()), ('SGD', SGDClassifier()), ('MultinomialNB', naive_bayes.MultinomialNB()), ('KNN', KNeighborsClassifier()), ('DecisionTree', DecisionTreeClassifier()), ('RandomForest', RandomForestClassifier()), ('AdaBoost', AdaBoostClassifier(base_estimator=LogisticRegression())) ] cols = ['metrics', 'accuracy', 'pos_precision', 'pos_recall', 'pos_f1_score', 'neg_precision', 'neg_recall', 'neg_f1_score'] scores = [] for name, clf in classifiers: score = KFold_validation(clf, X, y) row = [name] row.extend(score) scores.append(row) df = pd.DataFrame(scores, columns=cols).T df.columns = df.iloc[0] df.drop(df.index[[0]], inplace=True) df = df.apply(pd.to_numeric, errors='ignore') return df def dummy_fun(doc): return doc def eval_model(): print('Loading dataset...') X, y = load_dataset_tokenized() clf = svm.LinearSVC() vectorizer = TfidfVectorizer(analyzer='word', tokenizer=dummy_fun, preprocessor=dummy_fun, token_pattern=None) X = vectorizer.fit_transform(X) print('Train model...') clf.fit(X, y) print('Loading comments...') df = pd.read_csv(comment_file) df.dropna(inplace=True) df.reset_index(drop=True, inplace=True) df['created_time'] = pd.to_datetime(df['created_time'], format='%Y-%m-%d %H:%M:%S') df['polarity'] = 0 df['title'].apply(lambda x: [w.strip() for w in x.split()]) texts = df['title'] texts = vectorizer.transform(texts) preds = clf.predict(texts) df['polarity'] = preds df.to_csv('stock_comments_analyzed.csv', index=False) if __name__ == '__main__': scores = benchmark_clfs() print(scores) scores.to_csv('model_ml_scores.csv', float_format='%.4f') eval_model()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
完整源代码包下载:市情感分析源代码
-
相关阅读:
初识Java 17-2 反射
2024年度“阳江市惠民保”正式发布!阳江市专属补充医疗保险全新升级
【计算机操作系统慕课版】第一章知识点总结
Golang gorm manytomany 多对多 更新、删除、替换
2022亚太数学杯数学建模竞赛B题(思路、程序......)
易周金融分析 | 易观千帆发布7月城商行农商行APP盘点;养老理财产品跨行代销布局提速
基于 Scriptable 从零开始美化iOS桌面(集合篇)
最新Sora人工智能视频资源网址分享
Linux内核——门相关入门知识
MySQL备份和恢复
- 原文地址:https://blog.csdn.net/weixin_42756970/article/details/127408237
